







本篇博客在爬取新闻网站信息2的基础上进行。
主要内容如下:
1.定义获取一页20条链接内容的函数
2.构造多个分页链接
3.抓取多个分页链接新闻内容
4.用pandas整理爬取的资料
5.保存数据到csv文件
6.Scrapy的安装
1.定义获取一页20条链接内容的函数
#定义获取一页20条链接内容的函数
def parseListLinks(url):
newsdetails = []
res = requests.get(url)
jd = json.loads(res.text)
#获取一个页面所有链接(20个左右)
for ent in jd['result']['data']:
#getNewsDetail为获取一个链接内容详情
newsdetails.append(getNewsDetail(ent['url']))
return newsdetails#测试
url = 'https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page=1&encode=utf-8'
parseListLinks(url) 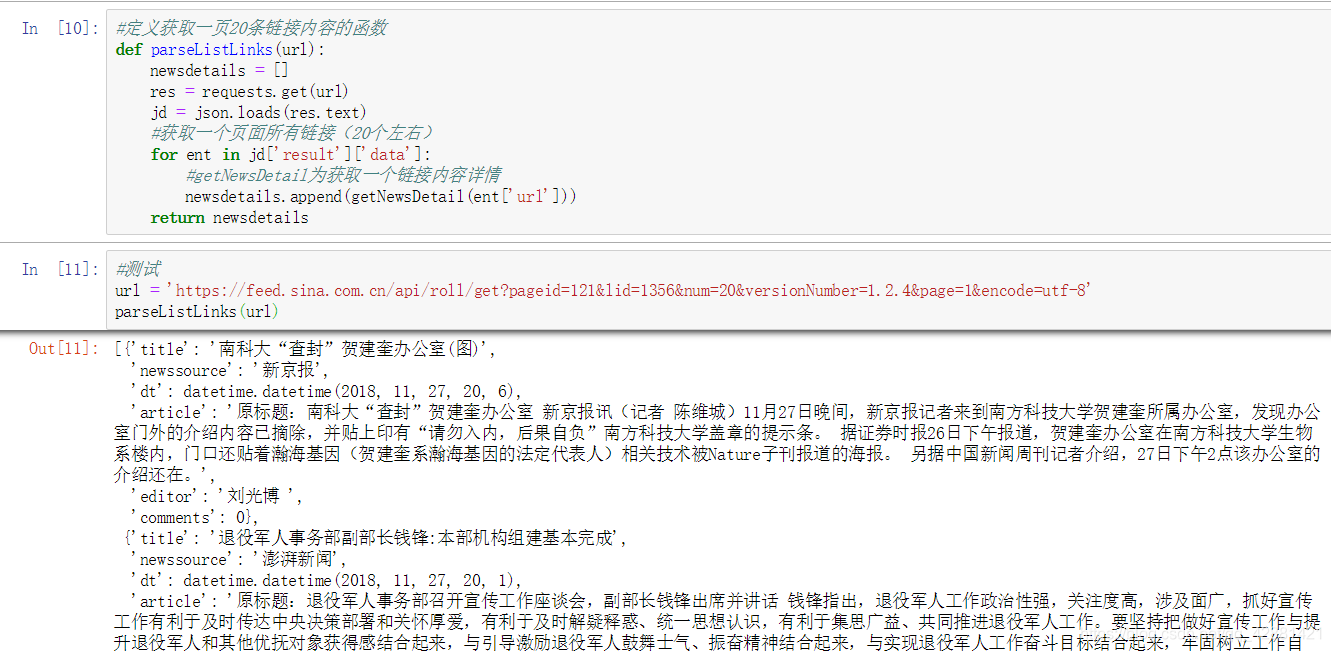
2.构造多个分页链接
#构造多个分页链接
pageurl = "https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page={}&encode=utf-8"
for i in range(1,10):
newsurl = pageurl.format(i)
print(newsurl) 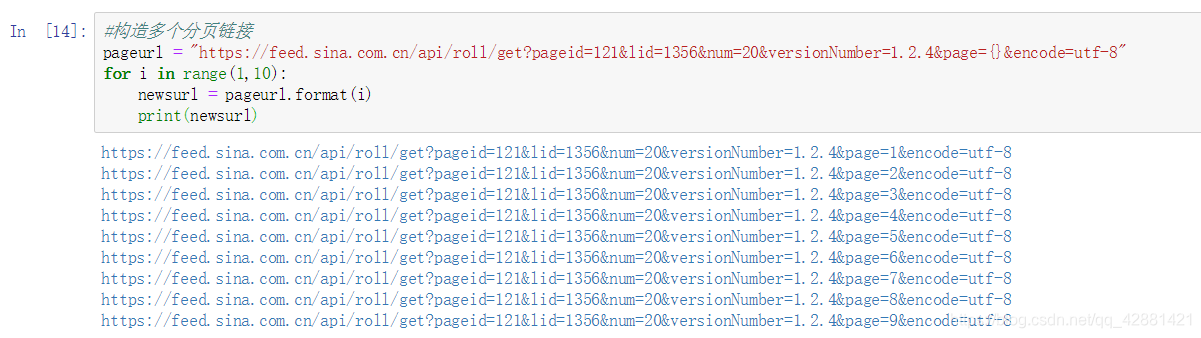
3.抓取多个分页链接新闻内容
#抓取多个分页链接新闻内容
import requests
url = 'https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page={}&encode=utf-8'
news_total = []
for i in range(1,3):
newsurl = url.format(i)
newsary = parseListLinks(url)
news_total.extend(newsary)#测试打印抓取的两个页面
print(news_total)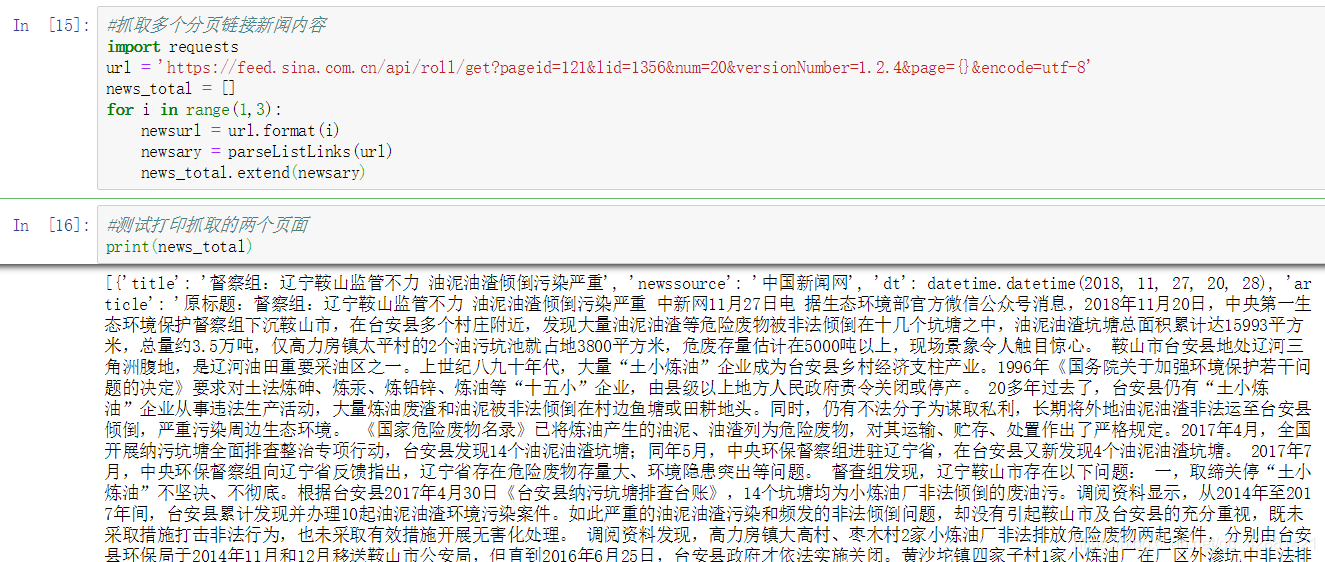
4.用pandas整理爬取的资料
Pandas 是python的一个数据分析包(Python Data Analysis Library),这里我们用到pandas的DataFrame函数将爬取出来的数据整理成二维的表格型数据结构。
安装pandas套件:进入cmd命令行,输入以下命令安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas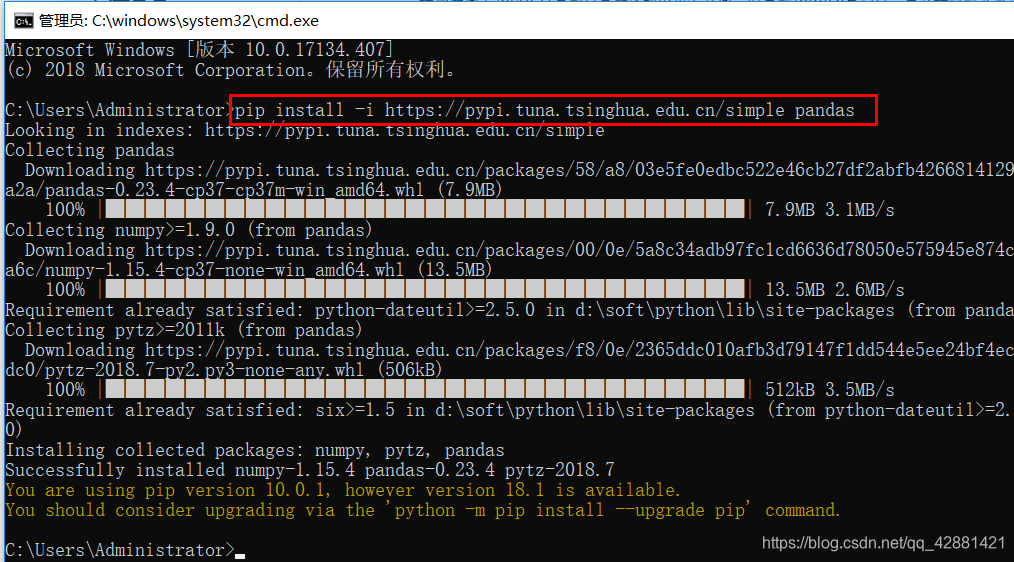
#用pandas整理爬取出的资料
import pandas
df = pandas.DataFrame(news_total)
#查看后5行数据
df.tail()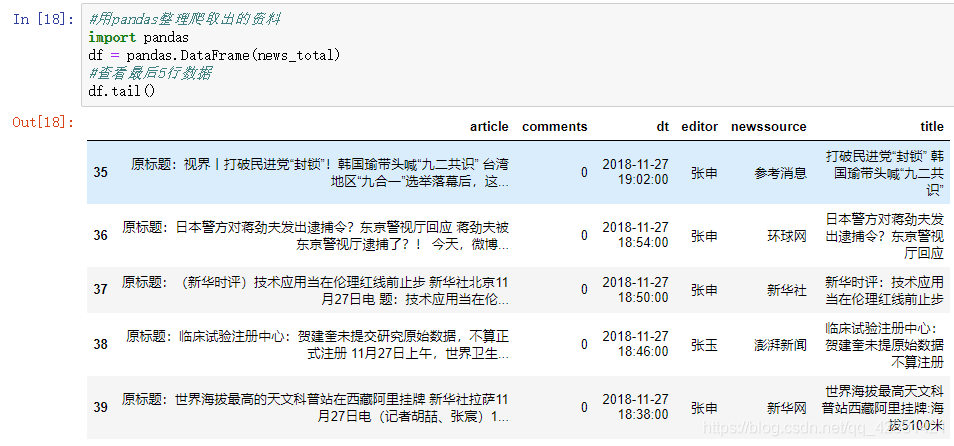
5.保存数据到csv文件
用to_csv函数,将数据存放在csv文件中,"ruiyigongfang.csv"为我们导出的文件名称,存放在jupyter notebook启动的根目录下,一般为C:\Users\Administrator目录下。

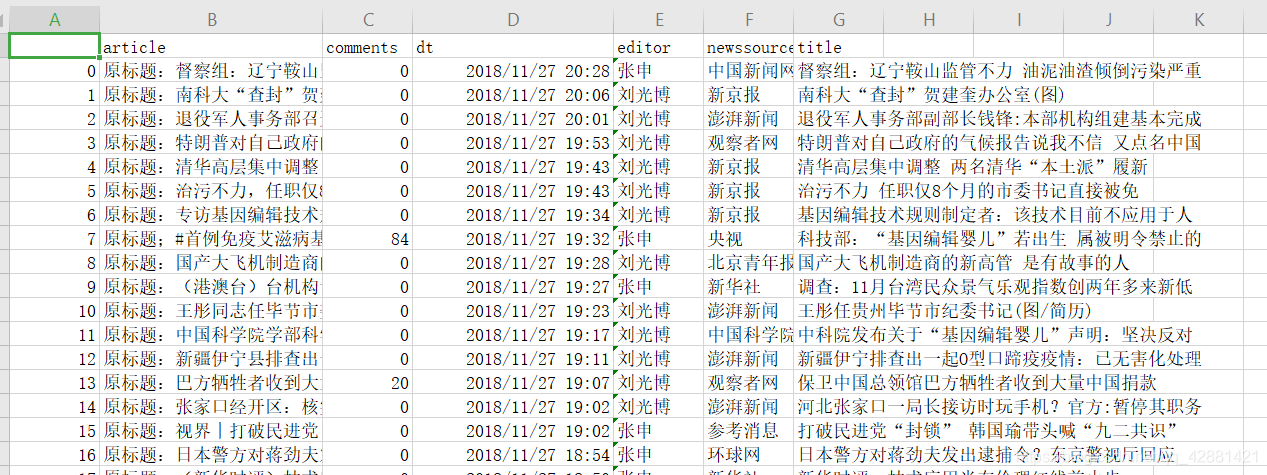
查看ruiyigongfang.csv文件内容
至此,已经完成了用python3爬取新闻网站信息的项目。
总结一下:
爬虫主要流程为分为三个阶段:

下载数据:用到requests套件,通过requests.get('url')方法获取到了网页信息
提取数据:用到BeautifulSoup4套件,通过soup.select('xxx')来解析得到关系的内容;
保存数据:通过pandas套件整理成二维数据结构的数据,再通过to_csv()函数将数据以csv格式保存在本地。
--------------------------------------------------------------------------------------------
接下来还会有第二个python爬虫项目,待下次博客更新!
这里先介绍一个简单、功能强大的爬虫框架Scrapy的安装,为后面项目做好准备。
Scrapy安装
环境:windows系统、python3
步骤:
1.安装wheel:
py -3 -m pip install wheel2.安装lxml:
py -3 -m pip install lxml3.安装Twisted:
下载Twisted:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
注意:下载的版本要与安装的python版本与电脑位数一致,python3.7就选择cp37, 其他版本依次类推 例如:
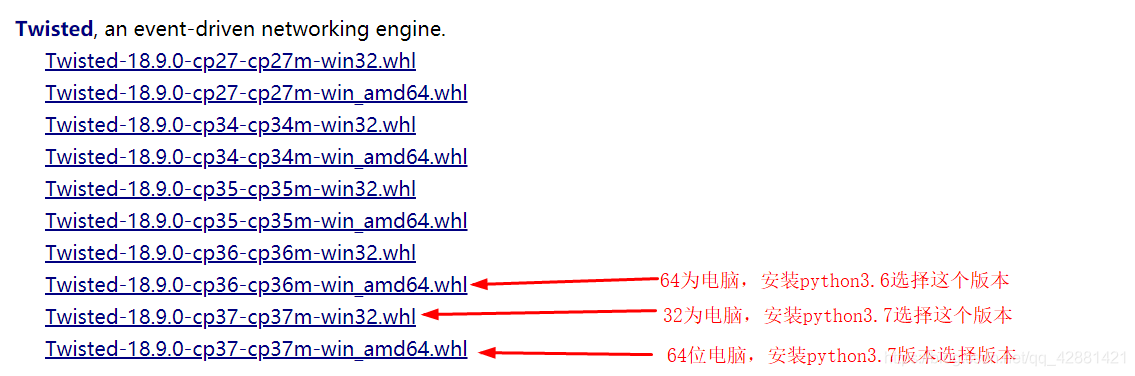
安装Twisted:
pip install xxx/xxx/Twistedxxx注意:xxx/xxx/Twistedxxx为下载的twisted文件的所在绝对路径。例如,下载的文件放在D:\目录下,文件名为Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
命令应该为pip install D:\Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
4.安装Scrapy:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy
5.安装win32py
下载:https://github.com/mhammond/pywin32/releases,注意要下载和python版本与电脑位数一致的文件
安装:双击pywin32-224.win-amd64-py3.7.exe文件安装
6.验证
scrapy -h
说明:
安装Scrapy依赖于wheel、lxml、Twisted模块
运行Scrapy依赖于win32py
完成! enjoy it!














 1118
1118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









