







来自:juejin.cn/post/7478893732190453798
推荐一个程序员编程资料站:
http://cxyroad.com
副业赚钱专栏:https://xbt100.top
2024年IDEA最新激活方法
后台回复:激活码
CSDN免登录复制代码插件下载:
CSDN复制插件
以下是正文。
杀鸡用牛刀
按照小数据量的查询商品标题,比如在一个四百万个商品里找标题,如果是使用%标题关键词%会全表扫描 ,一些小伙伴会忍不住上ES 或者 XunSearch ,我以前遇到的小系统,不少的人是这么干的。
其实没有必要,可能百分之99的开发者,这辈子都用不上。没有达一种非常夸张的数据量的时候,几百万个商品标题也是小事一桩。下面由我娓娓道来。

搜“一个饼干的包装”中的 “饼干” 不用%%
有没有一种方式,比如把 搜索 "一个饼干的包装" ,直接命中“饼干” 直接索引读取
思路打开
我们假设有一种方式,就是可以通过分词工具,比如 用jieba-php 进行分词。
假设,有两张表 product
product_title
Jieba::init();
Finalseg::init();
$tokens = Jieba::cut($model->title);我把商品标题表储存在 product 表中, 然后分词的储存在 product_title 中,这样就形成了对应,饼干和包装分两条数据储存在了product_title 表中,其中对应着 product_id 。 其中product_title 的title 加了索引。
这种情况就像是论坛里的朋友开发过的优化查询的插件 whereIn([product_id,product_id ])差不多的方案。
但是这种方式太low 了,要是多创建几个表搜索那不是要炸。
有没有现成的?
那有没有一种laravel 插件,或者mysql 插件能直接做呢?
话外~~~,其实写到这的时候就不想写了,现在gpt这么发达,还写博客,我都不知道自己在干嘛
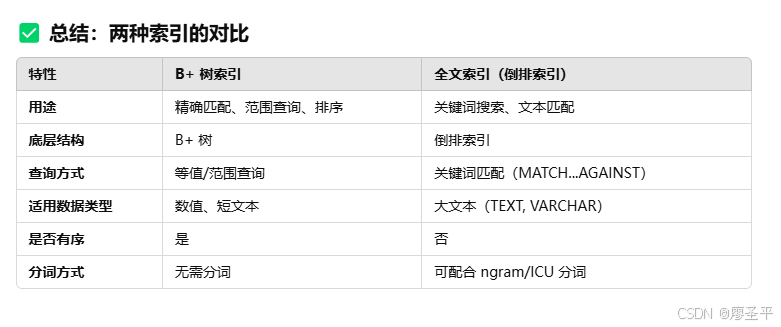
其实mysql 自带就有,叫 全文索引(FULLTEXT)
CREATETABLEtest (
idINT AUTO_INCREMENT PRIMARY KEY,
title TEXT,
FULLTEXT(title)
);这种方式的索引和我刚刚举例的的方式有点像,就是先进行了分词,分完词之后会储存到一个地方,读取的
$searchTerm = '关键词';
$results = YourModel::where('title', 'like', "%$searchTerm%")
->orWhereRaw("MATCH(title) AGAINST(? IN NATURAL LANGUAGE MODE)", [$searchTerm])
->get();这种方式又会遇到问题,因为mysql不知道中文呀,它只知道有空格的英文,中文分词默认的方式不行,需要一种 兼容 中文,日文,韩文这种语言叫做ngram分词的倒排索引
ALTERTABLE 表名 ADD FULLTEXT(title) WITH PARSER ngram;通过相对比较精确的分词,可以很快的完成我们的目标,搜索 “饼干”能找到相应的 文档ID ,直接命中索引
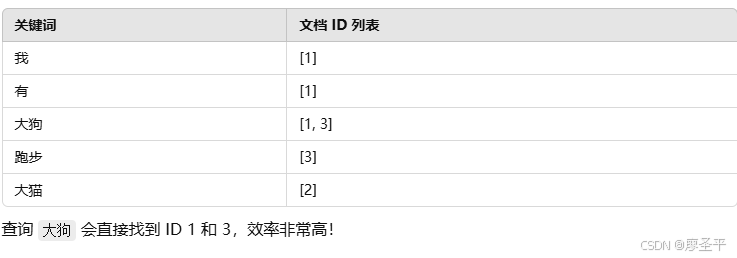
加不加 ngram 的区别:
还有最后一个问题
我们搜索场景搜索 “饼干包装” ,如果直接搜索能行吗? 不行! 因为没有储存“饼干包装”的文档库,如何实现呢?
还能再优化下吗?
从应用层面实现:
拿到用户的
keyword之后,用分词工具分开来, 再通过implode('+',$cuts)的方式塞到查询中
SELECT * FROM test_fulltext WHEREMATCH(title) AGAINST('饼干+包装'INBOOLEANMODE);还有就是索引保存在磁盘,意味着你不要买大内存的服务器部署 ,运行在内存中的中间件 ,可以调节mysql 的索引缓冲来优化查询
犟
实在不行,docker+ 主 从+从+从+从+从+从+从+从+从+从+从+从+从 .... 就能解决
再说了你用es 并发大了,也要考虑分布式
以后小伙伴们,业务中有类似的需求的时候,可以试试这种方案哈,别一个小小的系统还搞这些中间件哈,百分之99的开发碰不上,真的,我men只是配角!
<END>
推荐阅读:
免费体验AI图片生成,就在 Image Generator Hub!
程序员在线工具站:cxytools.com 推荐一个自己写的工具站:https://cxytools.com,专为程序员设计,包括时间日期、 JSON处理、SQL格式化、随机字符串生成、UUID生成、文本Hash...等功能,提升开发效 率。 ⬇戳阅读原文直达! 朕已阅


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









