Hadoop发展历史
最初起源nutch项目。这个项目是个通用爬虫项目。
项目中遇到两个问题:
1、数据存储
Hadoop :
HDFS---文件存储系统
MapReduce---分布式文件计算系统
HBase---非关系型数据库
2、数据检索
lucene
Hadoop版本
三种版本
线上使用CDH版本
Hadoop 1.x
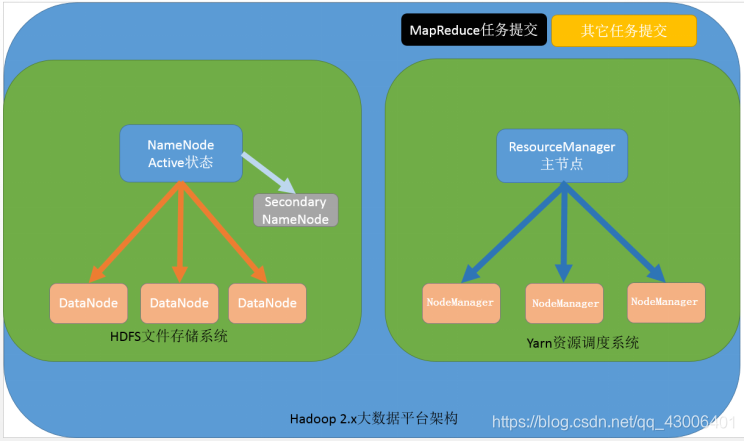
1、HDFS:
典型的主从架构,没有主备架构
nameNode :主节点,维护集群当中国的元数据,处理客户端请求
scondaryNode:协助nameNode维护元数据
dataNode:从节点,存储数据
2、元数据
描述数据的数据
例如:数据的创建时间、创建人等
3、mapReduce:
jobTracker:主节点,用于处理客户端请求,分配任务给taskTracker
taskTacker: 从节点,用户执行jobTacker分配的任务
Hadoop 2.x
2.x版本就用yarn资源调度系统取代了mapReduce,HDFS和1.x一样
resourceManager :主节点。负责处理客户端请求,分配资源(分配CPU、内存等)
nodeManagwger:从节点,负责执行appMaster分配的任务
2.x的架构模式
1、单机,主从节点都在一台服务器上
2、HDFS和yarn高可用
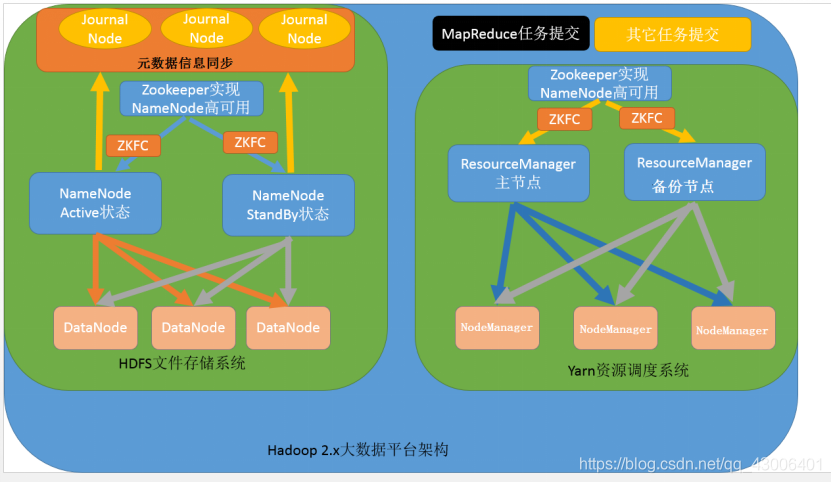
HDFS:
通过zookeeper实现高可用
NameNode有两种状态native和standBy
ZKFS 守护进程,一旦有一个NameNode宕机,standBy的NameNode立马激活为native
journalNode:元数据同步管理,为奇数
yarn
sourceManager有多个
ZKFS守护进程
配置Hadoop
下载解压Hadoop
修改 etc下的六个配置文件
core-site.xml 设置Hadoop为单机还是分布式
hdfs-site.xml 设置数据存储位置,block块大小
hadoop-env.sh 配置JAVA_HOME
mapred-site.xml 配置mapRedude
yarn-site.xml 配置yarn资源调度系统
slaves 配置从节点
使用Hadoop
bin/hadoop checknative 检查hadoop的本地库
snappy压缩是Google的一种压缩方式
1、初始化Hadoop
bin/hdfs namenode -format
2、启动HDFS
sbin/start-dfs.sh
3、启动yarn
sbin/start-yarn.sh
4、启动 历史查看、日志
sbin/mr-jobhistory-daemon.sh start historyserver
常用端口
50070默认看hdfs集群
8088默认看yarn集群
19888默认查看历史任务完成的界面





 本文详细介绍了Hadoop的起源与发展历程,从最初的Nutch项目到成为大数据处理领域的核心工具。解析了Hadoop1.x与2.x版本的主要区别,包括HDFS、MapReduce和YARN的架构原理,以及如何配置和使用Hadoop进行数据处理。
本文详细介绍了Hadoop的起源与发展历程,从最初的Nutch项目到成为大数据处理领域的核心工具。解析了Hadoop1.x与2.x版本的主要区别,包括HDFS、MapReduce和YARN的架构原理,以及如何配置和使用Hadoop进行数据处理。

















 229
229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









