







【论文精读】Superpixel Sampling Networks
Abstract
超像素为图像数据提供了一种高效的低/中级表示方法,大大减少了后续视觉任务所需的图像基元数量。现有的超像素算法是不可微的,这使得它们很难集成到端到端可训练的深层神经网络中。我们开发了一个新的可微分超像素采样模型,利用深度网络学习超像素分割。结果表明,该超像素采样网络(SSN)是端到端可训练的,它允许学习具有灵活损失函数的任务特定超像素,运行速度快。大量的实验分析表明,SSN不仅在传统的分割基准上优于现有的超像素算法,而且可以学习其他任务的超像素。此外,SSN可以很容易地集成到下游深度网络中,从而提高性能。
1和2部分懒得翻译
3 复习SLIC
- Pixel-Superpixel association:将每个像素与五维空间中最近的超级像素中心相关联,即判断每个像素p属于哪个新的超像素中心
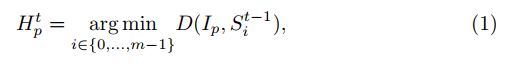
D D D表示计算距离: D ( a , b ) = ∣ ∣ a − b ∣ ∣ 2 D(a,b)=||a-b||^{2} D(a,b)=∣∣a−b∣∣2;注意由于在等式1中计算所有像素和超级像素之间的距离D是耗时的,因此该计算通常被限制在每个超像素中心周围的固定邻域内。
H p t H_{p}^{t} Hpt大小为n*m,表示第t次迭代时,原图第 p p p个像素是否属于第 i i i个超像素
I p I_{p} Ip表示原图第 p p p个像素
S i t − 1 S_{i}^{t-1} Sit−1表示第 t − 1 t-1 t−1次迭代时,第 i i i个超像素中心 - Superpixel center update:计算每个超像素内的平均像素特征(XY+Lab)以获得新的超像素中心
S
t
S^{t}
St。

S i t S_{i}^{t} Sit表示第t次迭代时,第 i i i个超像素中心
I p I_{p} Ip表示原图第p个像素
Z i t Z_{i}^{t} Zit超像素 i i i的像素个数
p ∣ H p t p|H_{p}^{t} p∣Hpt表示第t次迭代时,属于超像素 i i i的像素 p p p - 重复1、2步,直到收敛或进行固定次数的迭代。
4 Superpixel Sampling Networks(SSN)

SSN由两部分组成:一个生成像素特征的深度网络,然后将其传递给可微SLIC。
4.1 可微SLIC算法
为什么SLIC不可微?
答:问题出在Pixel-Superpixel association的计算(公式1),涉及不可微的最近邻运算。
解决方案:修改Pixel-Superpixel association从硬距离 H ∈ { 0 , 1 , . . . , m − 1 } n ∗ 1 H \in \{0,1,...,m-1\}^{n*1} H∈{0,1,...,m−1}n∗1变成软距离 Q ∈ R n ∗ m Q \in R^{n*m} Q∈Rn∗m;变不可微为可微分。
- Soft Pixel-Superpixel association:
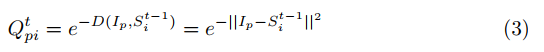
Q p i t Q_{pi}^{t} Qpit表示第t次迭代时,属于超像素 i i i与像素 p p p的软连接;
I p I_{p} Ip表示原图第p个像素
S i t − 1 S_{i}^{t-1} Sit−1表示第t-1次迭代时,第 i i i个超像素中心
D D D表示计算距离: D ( a , b ) = ∣ ∣ a − b ∣ ∣ 2 D(a,b)=||a-b||^{2} D(a,b)=∣∣a−b∣∣2 - Superpixel center update:

S i t S_{i}^{t} Sit表示第t次迭代时,第 i i i个超像素中心
I p I_{p} Ip表示原图第p个像素
Q p i t Q_{pi}^{t} Qpit表示第t次迭代时,属于超像素 i i i与像素 p p p的软连接;
Z i t = ∑ p Q p i t Z_{i}^{t}=\sum_{p}Q_{pi}^{t} Zit=∑pQpit 为归一化常数
将上述公式(4)矩阵化:
S
t
=
Q
t
^
T
I
S^{t}={\hat{Q^{t}}}^{T}I
St=Qt^TI
其中
Q
t
^
\hat{Q^{t}}
Qt^表示列归一化的
Q
t
Q^{t}
Qt。
其次,
Q
Q
Q的大小是n×m,即使对于少量的超像素m,计算所有像素和超像素之间的
Q
p
i
Q_{pi}
Qpi也是非常昂贵的。因此,我们将每个像素的距离计算限制为仅9个周围的超像素,如下图中红色和绿色框所示。

对于绿框中的每个像素,仅考虑红框中周围的超级像素来计算关联。这将 Q Q Q的大小从n×m降到n×9,使得它在计算和内存方面都非常有效。 Q Q Q计算中的这种近似在本质上类似于SLIC中的近似近邻搜索。
总算法流程:用深度网络计算的k维像素特征
F
p
∈
R
n
∗
k
F_{p} \in R^{n*k}
Fp∈Rn∗k来代替上述等式3和4中的图像特征
I
p
I_{p}
Ip。

一个关于后续计算损失函数的问题:像素和超像素如何映射?
答:
超像素至像素: S = Q ^ T I S=\hat Q^{T}I S=Q^TI,其中 Q ^ \hat Q Q^表示列归一化的 Q Q Q
像素至超像素: F = Q ~ S F=\tilde Q S F=Q~S, 其中 Q ~ \tilde Q Q~表示行归一化的 Q Q Q
4.2 SSN网络架构
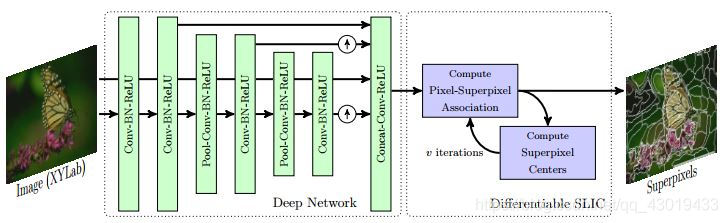
CNN由一系列卷积层、卷积层、BN和ReLU交织组成,整个网络可以进行端到端的训练:
- 在第二和第四卷积层之后,使用最大池(max-pooling),将输入的样本减少2倍,以增加感受野。
- 对第四和第六卷积层输出进行双线性上采样,然后与第二卷积层输出串联以传递到最终的卷积层。
- 用3× 3卷积滤波器,每个层的输出通道数设置为64个,但最后一个输出k− 5个频道。
- 连接这个k− 5通道与XY Lab图像原始特征,得到k维像素特征。
- 产生的k维特征被传递到可微SLIC的两个模块上,这两个模块迭代地更新像素超像素关联和v迭代的超像素中心。
4.3 损失函数:学习任务特定的超像素
- Task-specific reconstruction loss:
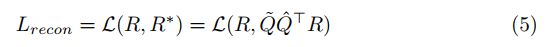
R ∈ R n ∗ l R \in R^{n*l} R∈Rn∗l表示像素特征,比如说R可以表示为语义分割标签或者光流图;
素特征映射至超像素特征: R ~ = Q ^ T R \tilde R=\hat Q^{T}R R~=Q^TR,其中 Q ^ \hat Q Q^表示列归一化的 Q Q Q, R ~ ∈ R ~ m ∗ l \tilde R \in \tilde R^{m*l} R~∈R~m∗l
超像素特征映射至像素特征: R ∗ = Q ~ S R^{*}=\tilde Q S R∗=Q~S, 其中 Q ~ \tilde Q Q~表示行归一化的 Q Q Q
L \mathcal{L} L表示特定任务的损失函数,对于分割任务,使用交叉熵损失,对于光流,使用L1范数。 - Compactness loss:
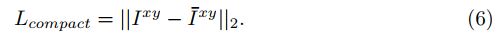
R x y R^{xy} Rxy表示像素位置特征;
像素位置特征映射至超像素位置特征: S x y = Q ^ T I x y S^{xy}=\hat Q^{T}I^{xy} Sxy=Q^TIxy
超像素位置特征映射至像素位置特征: I ‾ x y = S i x y ∣ H p = i \overline I^{xy}=S_{i}^{xy}|H_{p}=i Ixy=Sixy∣Hp=i;其中 H p H_{p} Hp表示硬位置距离 - 总损失函数:
L = L r e c o n + λ L c o m p a c t (7) L=L_{recon}+\lambda L_{compact} \tag{7} L=Lrecon+λLcompact(7)
其中本实验中 λ = 1 0 − 5 \lambda =10^{-5} λ=10−5
4.4 实现与实验参数设定
- 原文code
- 实现:Caffe=+Python
- 输入: xy坐标 + Lab(scaled);
γpos表示位置;γcolor表示颜色;
γcolor的值与超级像素的数量无关,设置为0.26,颜色值介于0和255之间。
γpos的值取决于超级像素的数量,γpos=η * max(mw/nw,mh/nh),其中mw,nw和mh,nh分别表示沿图像宽度和高度的超级像素和像素的数量。实践中,η=2.5表现良好。 - 训练网络输入:201×201的图像块,100个超级像素。
- 数据增强:左右翻转;对于小型BSDS500数据集:随机缩放图像块。
- 优化器 Adam,batch为8,学习率为0.0001。训练次500K迭代,并根据验证精度选择最终模型。
- 消融实验:200K次迭代,缩放上述输入位置特征来估计不同数量的超像素
- 可微SLIC训练:5次迭代(v=5)进行训练,测试时10次迭代,因为更多的迭代收益有限
5. Experiments
5.1 Learned Superpixels
- 数据集:BSDS500
- 损失函数:重建损失中使用GT分割标签(等式5)。具体地说,将每个图像中的GT分割表示为一个热编码向量,并将其作为重建损失中的像素属性R。 L \mathcal{L} L为交叉熵损失函数。
- 评价指标:Achievable Segmentation Accuracy (ASA) + Boundary Recall (BR) + Boundary Precision (BP)
ASA表示对超像素进行下一步的分割步骤可达到的精度上限。BR、BP度量超级像素边界与GT边界的对齐程度。
其次,对边界精度和召回的公平评估期望超像素在空间上是连接的。因此,计算hard clusters并在SSN超像素上强制执行空间连接性(算法1中的第7-8行)。 - 消融实验:
S S N d e e p SSN_{deep} SSNdeep:main model :7卷积层神经网络
S S N l i n e a r SSN_{linear} SSNlinear:用一个卷积层代替了深层网络,学习XY+lab线性变换
S S N p i x SSN_{pix} SSNpix: 可微SLIC算法,以像素XY+lab特征

结果表明,ASA和BR的得分随着深度网络的增加而显著提高,随着特征维数k和可微 S L I C SLIC SLIC迭代次数v的增加而略有提高
出于计算原因,选择k=20和v=10,从这里开始,将此模型称为 S S N d e e p SSN_{deep} SSNdeep - 与其它算法对比
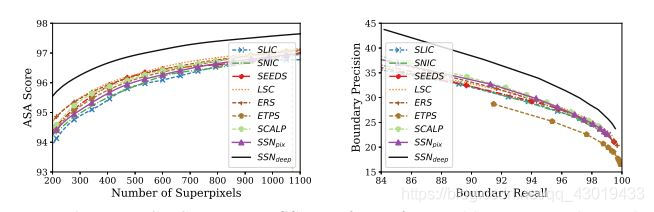
S S N p i x SSN_{pix} SSNpix的性能类似于 S L I C SLIC SLIC超像素,表明当放松近邻约束时 S L I C SLIC SLIC的性能不会下降。 S S N p i x SSN_{pix} SSNpix在ASA、BP、BR方面,对比其它超像素分割算法都有相当好的表现。
5.2 Superpixels for Semantic Segmentation
- 数据集:Cityscapes + PascalVOC
- 损失函数:与5.1相似,利用语义标签作为图像重建损失中的像素属性R
- 结果:
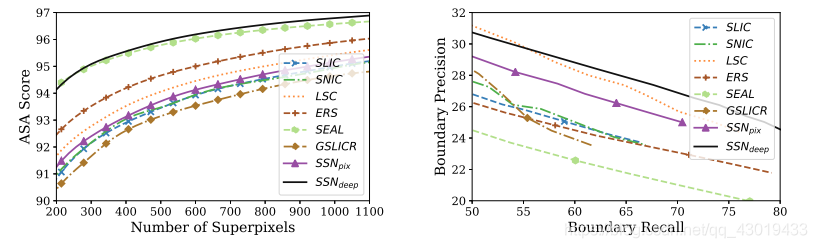
on Cityscapes :
on PascalVOC:
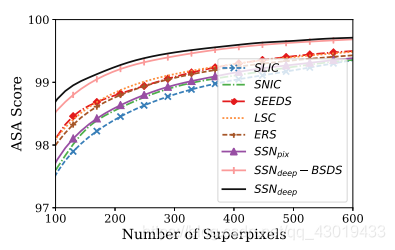
ASA和边界精确召回结果表明, S S N SSN SSN的性能优于其他技术
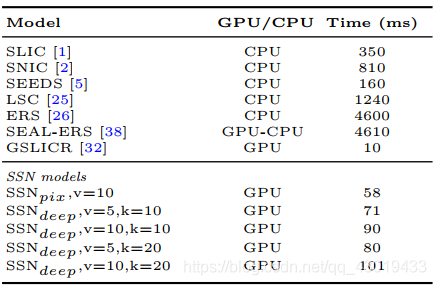
- 运行时间分析:在512×1024图像上计算1000个超像素用时
S S N p i x SSN_{pix} SSNpix和 S S N d e e p SSN_{deep} SSNdeep之间的运行时比较表明, S S N SSN SSN计算时间的很大一部分是由可微 S L I C SLIC SLIC引起的。运行时表明 S S N SSN SSN比几种超像素算法的实现速度要快得多
- 附加实验:将SSN与此文献中模型结合,与文献中使用的原始SLIC超像素相比,IoU的提升表明
S
S
N
SSN
SSN可以给使用超像素的下游任务网络带来性能改进。

5.3 Superpixels for Optical Flow
- 数据集:MPI-Sintel dataset
- 损失函数:GT光流作为重建损失中的像素属性R(等式5),并使用L1范数作为 L \mathcal{L} L损失函数
- 结果:

用不同类型的超像素获得的分段光流图像表明,与其他技术相比, S S N d e e p SSN_{deep} SSNdeep超像素可以更好地表示GT光流。














 4800
4800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









