




 本文介绍了分类算法的基础知识,包括K-近邻(KNN)、支持向量机(SVM)、朴素贝叶斯和决策树。朴素贝叶斯常用于文本分类,适合多分类任务,而SVM通过构建分类边界进行分类。决策树则以树状结构进行特征测试,形成分类规则。这些算法在实际应用中各有优势,选择时需考虑数据特性和问题需求。
本文介绍了分类算法的基础知识,包括K-近邻(KNN)、支持向量机(SVM)、朴素贝叶斯和决策树。朴素贝叶斯常用于文本分类,适合多分类任务,而SVM通过构建分类边界进行分类。决策树则以树状结构进行特征测试,形成分类规则。这些算法在实际应用中各有优势,选择时需考虑数据特性和问题需求。
分类算法原理
一、KNN(K-近邻)
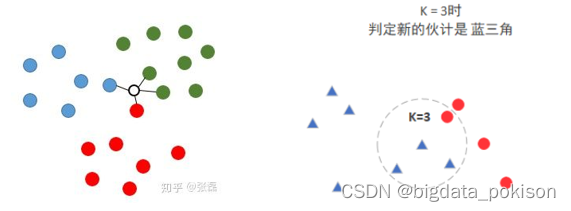
| 1、定义: 如果待推测点(空心点)在中间的某个位置,则计算出与其最邻近的4个样本点(K=4),而此时这4个样本点包含了3个类别(1红、1蓝、2绿),针对这样的情况,knn算法通常采用投票法来进行类别推测,即找出k个样本点中类别出现次数最多的那个类别,因此该待推测点的类型值即被推测为 --------绿色类别。
knn算法的基本法则是: 在特征空间中,相同类别的样本之间 应当聚集在一起。 |
| K-NN: 意思就是K个最近的邻居。 KNN的原理:当预测一个新的值x的时候,根据它距离最近的K个点是什么类别 来判断x属于哪个类别。 关键点: K值的选取、点距离的计算。 (K值选取要调参测试) |
二、支持向量机SVM (就是条直线)
| 1、定义: 支持向量:那些距离分割平面最近的点。 支持向量机就是用来分割数据点那个分割面,他的位置是由支持向量(点)确定的 (如果支持向量发生了变化,往往分割面的位置也会随之改变), 因此这个面就是一个支持向量确定的分类器---即支持向量机。 对于线性可分两类数据,支持向量机就是条直线 (对于高维数据点就是一个超平面) 。 两类数据点中的的分割线有无数条,SVM就是这无数条中最完美的一条。 怎么样才算最完美呢?就是这条线距离两类数据点越远。 则当有新的数据点的时候我们使用 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











