







缺失值
缺失值的判定
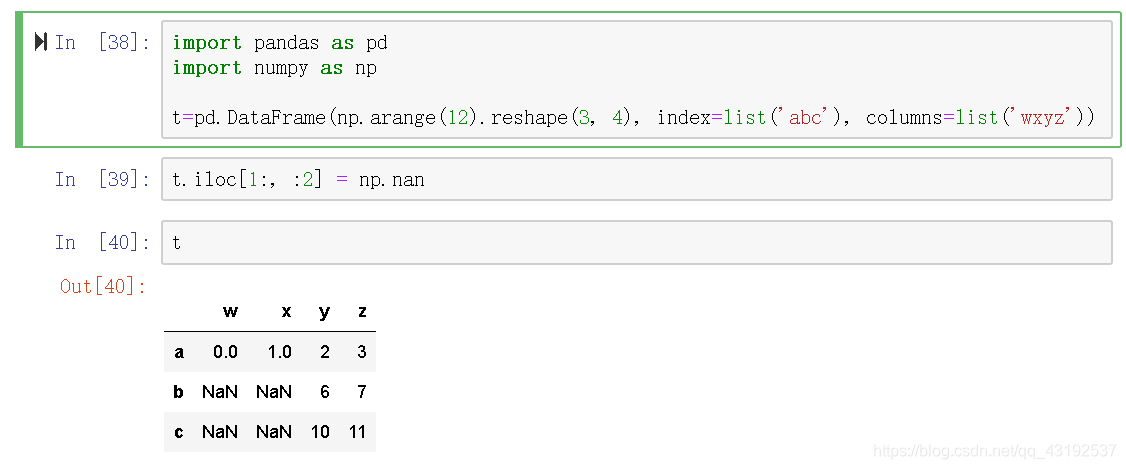
pd.isnull()
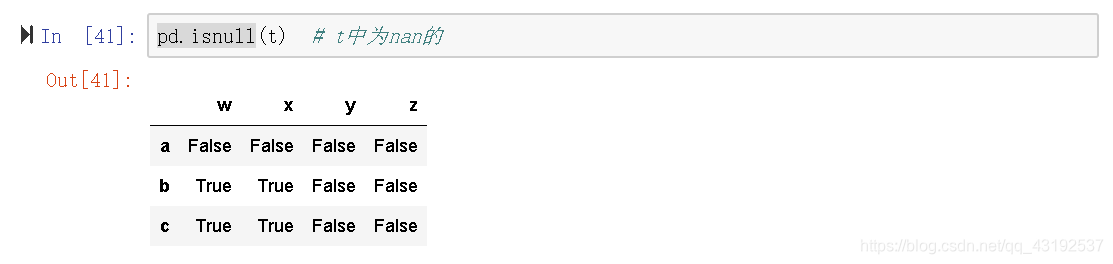
pd.notnull()
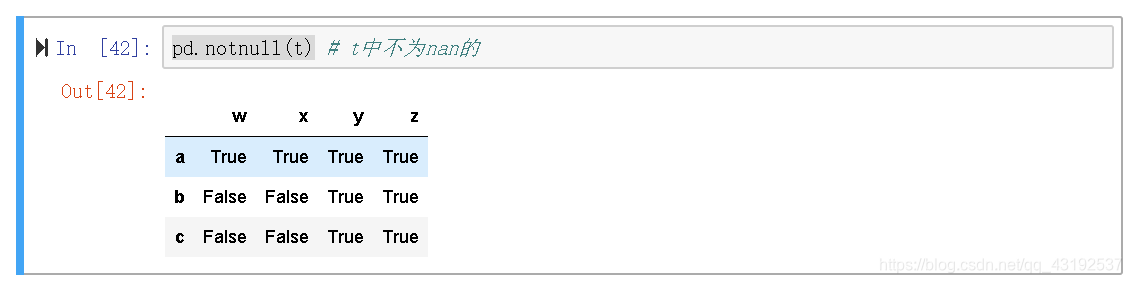

错误筛选

缺失值的处理
pd.dropna()


pd.drop_duplicates()
df = pd.DataFrame({'color':['red','blue','red','red'],'price':[10,15,20,10]})
display(df)

如果使用df3 = pd.concat([df1,df2],axis = 1)生成新的DataFrame,新的df3中columns相同,使用drop_duplicates()会出问题
# 按color这一列, 清除重复数据
df.drop_duplicates('color')

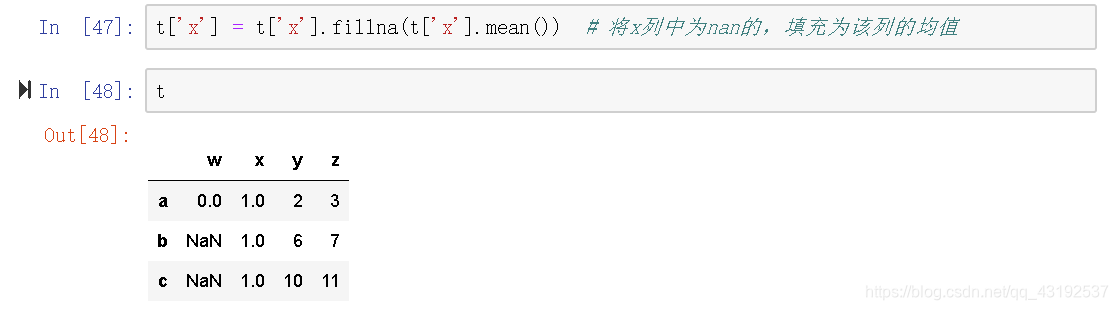
pd.fillna()
t.mean()会求当前所有列为nan的平均值

异常值
异常值处理
处理标准:根据正太分布 将过大或者过小的数据删除
即x - x_mean > 3σ该值异常值
σ:std标准差
x_mean:平均值
import pandas as pd
import numpy as np
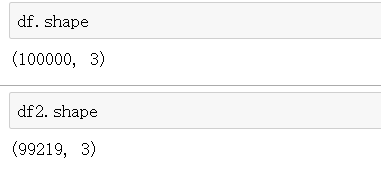
df = pd.DataFrame(np.random.randn(100000,3),columns = ['red','green','blue'])
cond = df.abs() - df.mean() > 3*df.std()
cond.sum() # 小于3σ标准的总和
# 让小于3σ标准的那些作为条件 即布尔索引
# 借助any()函数, 测试是否有True,有一个或以上返回True,反之返回False
cond = cond.any(axis = 1)
df2 = df.drop(labels=df[cond].index)














 499
499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









