







简介
DStream上的操作与RDD的类似,分为Transformations(转换)和Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种Window相关的原语
什么叫做原语?
例将常用的flatmap、map、fliter等RDD算子进行封装,封装成的方法在 sparkstreaming 中叫做原语
无状态转化操作
人类语言:例如统计wordcount时,会有不同的数据采集周期,无状态转化操作指的是只统计每一个采集周期内的单词数量,不会累加统计所有采集周期内单词的数量
无状态转化操作有哪些,如下表

注意: 针对键值对的DStream转化操作,比如 reduceByKey() ,需要添加 import StreamingContext._ 才能在Scala中使用
无状态转化原语中的特殊原语-Transform
人类语言:DStream中提供的方法(这里叫做原语)并不完善,例如DStrem API 只是封装了常用的RDD算子(例如只将常用的flatmap、map、fliter等RDD算子进行了封装),但像排序相关的原语就没有。那如果需求当中就是要求排序怎么办?
那就要用到 Transform 这个原语了。它可以将DStream转换为RDD,进而就可以利用RDD中的 sort 算子进行排序了
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @note: 该函数每一批次调度一次(无状态转换操作中已经介绍了)
* @Desc : 使用transform算子将DS转换为RDD
*/
object SparkStreaming08_Transform {
def main(args: Array[String]): Unit = {
//创建配置文件对象
//注意Streaming程序执行至少需要2个线程,所以不能设置为local
val conf: SparkConf = new SparkConf().setAppName("SparkStreaming08_Transform").setMaster("local[*]")
//创建SparkStreaming程序执行入口
//指定采集周期为3s
val ssc = new StreamingContext(conf, Seconds(3))
//从指定端口读取数据
val socketDS: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 8888)
//将DS转换为RDD进行操作
val resRDD: DStream[(String, Int)] = socketDS.transform(
rdd => {
val flatMapRDD: RDD[String] = rdd.flatMap(_.split(" "))
val mapRDD: RDD[(String, Int)] = flatMapRDD.map((_, 1))
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
reduceRDD.sortByKey() // 默认返回排序好的rdd
}
)
resRDD.print()
//启动采集器
ssc.start()
//等待采集结束之后,终止程序
ssc.awaitTermination()
}
}
有状态转化操作
人类语言:例如统计wordcount时,会有不同的数据采集周期,无状态转化操作指的是只统计每一个采集周期内的单词数量,不会累加统计所有采集周期内单词的数量,而有状态转化操作就会累加统计所有采集周期内单词的数量
有状态转化操作原语-UpdateStateByKey
UpdateStateByKey() 的结果会是一个新的DStream,其内部的RDD 序列是由每个时间区间对应的(键,状态)对组成的
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object demo {
def main(args: Array[String]): Unit = {
// 创建sparkconf
val conf: SparkConf = new SparkConf().setAppName("x").setMaster("local[*]")
// 创建sparkstreaming程序执行入口,并指定采集周期为3s
val ssc = new StreamingContext(conf, Seconds(3))
// 设置检查点路径,状态保持在checkpoint中
ssc.checkpoint("./cp")
// 从指定端口中读取数据
val socketDS: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
// 对数据进行扁平化
val mapDS: DStream[(String, Int)] = socketDS.flatMap(_.split(" ")).map((_, 1))
mapDS.updateStateByKey(
// 需要传递进去一个函数,该函数有2个参数
// 第一个参数:表示相同的key对应的value组成的数据集合
/*
(hello,1)
---> hello (1,1)
(hello,1)
*/
// 第二个参数:相同key对应的状态(即上一个采集周期的结果)
(seq: Seq[Int], state: Option[Int]) => {
// seq.sum:对当前key对应的value进行求和
// state.getOrElse(0):获取缓存区的数据 如果第一次,那么缓存区放一个0
Option(seq.sum + state.getOrElse(0))
}
).print()
// 启动采集器
ssc.start()
// 等待采集结束之后,终止程序
ssc.awaitTermination()
}
}
有状态转化原语-Window
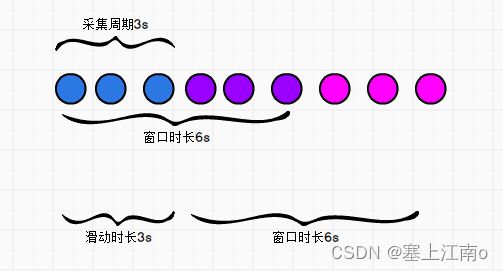
窗口时长
滑动步长
采集周期
注意:这两者都必须为采集周期的整数倍
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object demo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("x").setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(3))
val socketDS: DStream[String] = ssc.socketTextStream("hadoop102", 9999)
// 第一个参数窗口的大小,第二个参数滑动步长;两个参数都应该是采集周期的整数倍
val windowDS: DStream[String] = socketDS.window(Seconds(6), Seconds(3))
// 业务逻辑
windowDS.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()
// 启动线程
ssc.start()
// 等待采集结束之后,终止程序
ssc.awaitTermination()
}
}
关于Window的操作还有如下方法
- window(windowLength, slideInterval)
基于对源DStream窗化的批次进行计算返回一个新的Dstream
- countByWindow(windowLength, slideInterval)
返回一个滑动窗口计数流中的元素个数
- countByValueAndWindow()
返回的DStream则包含窗口中每个值的个数
- reduceByWindow(func, windowLength, slideInterval)
通过使用自定义函数整合滑动区间流元素来创建一个新的单元素流
- reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks])
当在一个(K,V)对的DStream上调用此函数,会返回一个新(K,V)对的DStream,此处通过对滑动窗口中批次数据使用reduce函数来整合每个key的value值
- reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks])
这个函数是上述函数的变化版本,每个窗口的reduce值都是通过用前一个窗的reduce值来递增计算。通过reduce进入到滑动窗口数据并”反向reduce”离开窗口的旧数据来实现这个操作。如果把3秒的时间窗口当成一个池塘,池塘每一秒都会有鱼游进或者游出,那么第一个函数表示每由进来一条鱼,就在该类鱼的数量上累加。而第二个函数是,每由出去一条鱼,就将该鱼的总数减去一














 1812
1812











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









