







多分类逻辑回归判断三分类鸢尾花
小记
2022.4.20
参考张觉非的书的 ch04章,
训练目标
有一个鸢尾花数据集,里面有150个鸢尾花样本,每个样本有4个特征,有3个类别,判断该样本属于哪个类别
思路
-
这是一个四特征,三分类的分类问题,尝试构造一个三分类逻辑回归模型来解决。 Wx+b是线性部分,线性部分经SoftMax函数得到三维概率向量p,从而得到预测值, 线性部分与分类经CrossEntropyWithSoftMax 得到交叉熵。
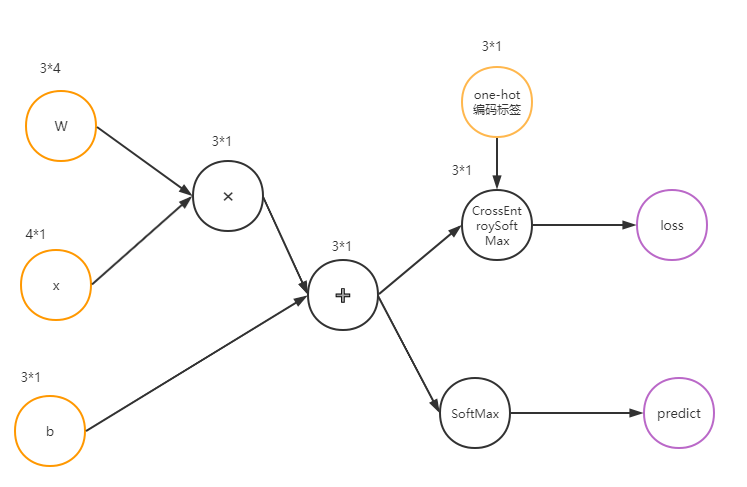
-
logit函数,也就是线性部分为

对logit向量施加SoftMax函数得到多分类概率分布函数为
**SoftMax函数的好处:**使得输出向量的所有分量之和是1,且当输入向量的某个分量极小时 候,对应分量近似为0;当输入向量的某个分量极大时,对应分量为近似为1。
- 交叉熵(cross entropy) 可以用来衡量两个分布的相似程度

交叉熵越小,则分布p与分布l就越相似。
分布p是由SoftMax得到的, 但是在程序中,不是先调用SoftMax函数再调用交叉熵函数,而是把SoftMax函数和交叉熵合并实现为了一个结点类,这是因为这样会使得反向传播计算雅可比矩阵时候更容易。
∂
C
r
o
s
s
E
n
t
r
o
p
y
(
p
,
l
)
∂
a
s
=
p
s
−
l
s
\frac{\partial CrossEntropy(p,l) }{\partial a_s}=p_s-l_s
∂as∂CrossEntropy(p,l)=ps−ls
- 分布l,即代表 标签的分布,用独热编码即 One-Hot 编码表示,其特点是任意时候,只有一位有效。 样本属于第几类否则向量的第几分量就取1,其余分量取0。
代码更新
- 在 上篇优化器 的代码上改。
- 增加 了激活函数模块 增加 SoftMax 类,损失函数模块增加CrossEntropyWithSoftMax类
代码框架
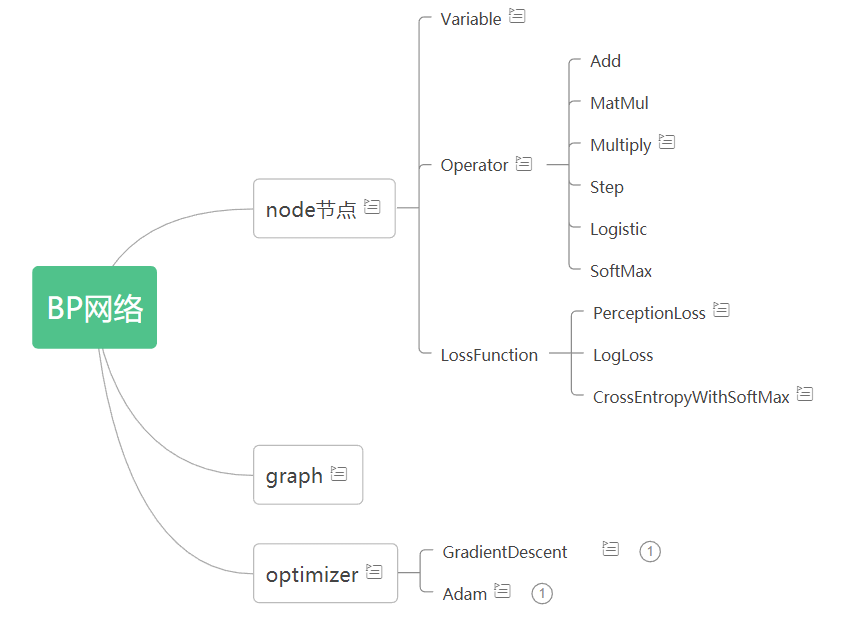
代码
main.py
# -*- coding: utf-8 -*-
"""
Created on Sat Feb 8 20:31:30 2020
@author: chaos
"""
import sys
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
import node,ope,optimizer,loss
from node import Variable
from graph import default_graph
from icecream import ic
# 读取鸢尾花数据集,去掉第一列Id
data = pd.read_csv("Iris.csv").drop("Id", axis=1)
# 随机打乱样本顺序
data = data.sample(len(data), replace=False)
# 将字符串形式的类别标签转换成整数0,1,2
le = LabelEncoder()
number_label = le.fit_transform(data["Species"])
# 将整数形式的标签转换成One-Hot编码
oh = OneHotEncoder(sparse=False)
one_hot_label = oh.fit_transform(number_label.reshape(-1, 1))
# 特征列
features = data[['SepalLengthCm',
'SepalWidthCm',
'PetalLengthCm',
'PetalWidthCm']].values
# 构造计算图:输入向量,是一个4x1矩阵,不需要初始化,不参与训练
x = Variable(shape=(4, 1), trainable=False)
W = Variable(shape=(3, 4), trainable=True)
b = Variable(shape=(3, 1), trainable=True)
W.set_value(np.mat(np.random.normal(0, 0.001, (3, 4))))
b.set_value(np.mat(np.random.normal(0, 0.001, (3, 1))))
one_hot =Variable(shape=(3, 1), trainable=False)
# 线性部分
linear = ope.Add(ope.MatMul(W, x), b)
# 模型输出
predict = ope.SoftMax(linear)
# 交叉熵损失
loss = loss.CrossEntropyWithSoftMax(linear, one_hot)
# 学习率
learning_rate = 0.02
# 构造Adam优化器
optimizer = optimizer.Adam(default_graph, loss, learning_rate)
# 批大小为16
batch_size = 16
# 训练执行200个epoch
for epoch in range(100):
# 批计数器清零
batch_count = 0
# 遍历训练集中的样本
for i in range(len(features)):
# 将特征赋给x节点,将标签赋给one_hot节点
x.set_value(np.mat(features[i, :]).T)
one_hot.set_value(np.mat(one_hot_label[i, :]).T)
# 调用优化器的one_step方法,执行一次前向传播和反向传播
optimizer.forward_backward()
batch_count += 1
# 若批计数器大于等于批大小,则执行一次梯度下降更新,并清零计数器
if batch_count >= batch_size:
optimizer.update()
batch_count = 0
# 每个epoch结束后评估模型的正确率
pred = []
# 遍历训练集,计算当前模型对每个样本的预测值
for i in range(len(features)):
feature = np.mat(features[i, :]).T
x.set_value(feature)
# 在模型的predict节点上执行前向传播 # 批计数器加1
predict.forward()
pred.append(predict.value.A.ravel()) # 模型的预测结果:3个概率值
# 取最大概率对应的类别为预测类别
pred = np.array(pred).argmax(axis=1)
# 判断预测结果与样本标签相同的数量与训练集总数量之比,即模型预测的正确率
accuracy = (number_label == pred).astype(np.int).sum() / len(data)
# 打印当前epoch数和模型在训练集上的正确率
print("epoch: {:d}, accuracy: {:.3f}".format(epoch + 1, accuracy))
SoftMax(Operator):
class SoftMax(Operator):
"""
SoftMax函数
"""
@staticmethod
def softmax(a):
a[a > 1e2] = 1e2 # 防止指数过大
ep = np.power(np.e, a)
return ep / np.sum(ep)
def compute(self):
self.value = SoftMax.softmax(self.parents[0].value)
def get_jacobi(self, parent):
"""
我们不实现SoftMax节点的get_jacobi函数, 因为它只用在输出预测值时。
训练时使用CrossEntropyWithSoftMax节点
"""
raise NotImplementedError("Don't use SoftMax's get_jacobi")
CrossEntropyWithSoftMax(LossFunction):
class CrossEntropyWithSoftMax(LossFunction):
"""
对第一个父节点施加SoftMax之后,再以第二个父节点为标签One-Hot向量计算交叉熵
"""
def compute(self):
prob = ope.SoftMax.softmax(self.parents[0].value)
self.value = np.mat(
-np.sum(np.multiply(self.parents[1].value, np.log(prob + 1e-10))))
def get_jacobi(self, parent):
# 这里存在重复计算,但为了代码清晰简洁,舍弃进一步优化
prob = ope.SoftMax.softmax(self.parents[0].value)
if parent is self.parents[0]:
return (prob - self.parents[1].value).T
else:
return (-np.log(prob)).T
















 788
788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











