






前言
1.缓存穿透
描述:访问一个缓存和数据库都不存在的 key,此时会直接打到数据库上,并且查不到数据,没法写缓存,所以下一次同样会打到数据库上。
此时,缓存起不到作用,请求每次都会走到数据库,流量大时数据库可能会被打挂。此时缓存就好像被“穿透”了一样,起不到任何作用。
2.缓存击穿
描述:某一个热点 key,在缓存过期的一瞬间,同时有大量的请求打进来,由于此时缓存过期了,所以请求最终都会走到数据库,造成瞬时数据库请求量大、压力骤增,甚至可能打垮数据库。
3.缓存雪崩
描述:大量的热点 key 设置了相同的过期时间,导在缓存在同一时刻全部失效,造成瞬时数据库请求量大、压力骤增,引起雪崩,甚至导致数据库被打挂。
缓存雪崩其实有点像“升级版的缓存击穿”,缓存击穿是一个热点 key,缓存雪崩是一组热点 key。
一、缓存穿透
描述:访问一个缓存和数据库都不存在的 key,此时会直接打到数据库上,并且查不到数据,没法写缓存,所以下一次同样会打到数据库上。
此时,缓存起不到作用,请求每次都会走到数据库,流量大时数据库可能会被打挂。此时缓存就好像被“穿透”了一样,起不到任何作用。
解决方案:
- 接口校验。 在正常业务流程中可能会存在少量访问不存在 key 的情况,但是一般不会出现大量的情况,所以这种场景最大的可能性是遭受了非法攻击。可以在最外层先做一层校验:用户鉴权、数据合法性校验等,例如商品查询中,商品的ID是正整数,则可以直接对非正整数直接过滤等等。
- 缓存空值 当访问缓存和DB都没有查询到值时,可以将空值写进缓存,但是设置较短的过期时间,该时间需要根据产品业务特性来设置。
- 布隆过滤器 使用布隆过滤器存储所有可能访问的 key,不存在的 key 直接被过滤,存在的 key 则再进一步查询缓存和数据库。
布隆过滤器
布隆过滤器的特点是判断不存在的,则一定不存在;判断存在的,大概率存在,但也有小概率不存在。并且这个概率是可控的,我们可以让这个概率变小或者变高,取决于用户本身的需求。
布隆过滤器由一个 bitSet 和 一组 Hash 函数(算法)组成,是一种空间效率极高的概率型算法和数据结构,主要用来判断一个元素是否在集合中存在。
在初始化时,bitSet 的每一位被初始化为0,同时会定义 Hash 函数,例如有3组 Hash 函数:hash1、hash2、hash3。
写入流程
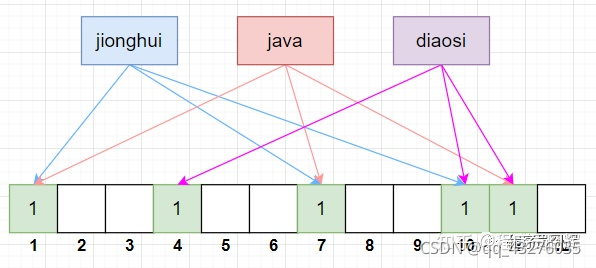
当我们要写入一个值时,过程如下,以“jionghui”为例:
1)首先将“jionghui”跟3组 Hash 函数分别计算,得到 bitSet 的下标为:1、7、10。
2)将 bitSet 的这3个下标标记为1。
假设我们还有另外两个值:java 和 diaosi,按上面的流程跟 3组 Hash 函数分别计算,结果如下:
java:Hash 函数计算 bitSet 下标为:1、7、11
diaosi:Hash 函数计算 bitSet 下标为:4、10、11
查询流程
当我们要查询一个值时,过程如下,同样以“jionghui”为例::
1)首先将“jionghui”跟3组 Hash 函数分别计算,得到 bitSet 的下标为:1、7、10。
2)查看 bitSet 的这3个下标是否都为1,如果这3个下标不都为1,则说明该值必然不存在,如果这3个下标都为1,则只能说明可能存在,并不能说明一定存在。
其实上图的例子已经说明了这个问题了,当我们只有值“jionghui”和“diaosi”时,bitSet 下标为1的有:1、4、7、10、11。
当我们又加入值“java”时,bitSet 下标为1的还是这5个,所以当 bitSet 下标为1的为:1、4、7、10、11 时,我们无法判断值“java”存不存在。
其根本原因是,不同的值在跟 Hash 函数计算后,可能会得到相同的下标,所以某个值的标记位,可能会被其他值给标上了。
这也是为啥布隆过滤器只能判断某个值可能存在,无法判断必然存在的原因。但是反过来,如果该值根据 Hash 函数计算的标记位没有全部都为1,那么则说明必然不存在,这个是肯定的。
降低这种误判率的思路也比较简单:
1)一个是加大 bitSet 的长度,这样不同的值出现“冲突”的概率就降低了,从而误判率也降低。
2)提升 Hash 函数的个数,Hash 函数越多,每个值对应的 bit 越多,从而误判率也降低。
HashMap 和 布隆过滤器
估计有同学看了上面的例子,会觉得使用 HashMap 也能实现。
确实,当数据量不大时,HashMap 实现起来一点问题都没有,而且还没有误判率,简直完美,还要个鸡儿布隆过滤器。
不过,当数据量上去后,布隆过滤器的空间优势就会开始体现,特别是要存储的 key 占用空间越大,布隆过滤器的优势越明显。
布隆过滤器占用多少空间,主要取决于 Hash 函数的个数,跟 key 本身的大小无关,这使得其在空间的优势非常大。
二、缓存击穿
解决方案
-
加互斥锁。在并发的多个请求中,只有第一个请求线程能拿到锁并执行数据库查询操作,其他的线程拿不到锁就阻塞等着,等到第一个线程将数据写入缓存后,直接走缓存。
可以选择 Redis 分布式锁,因为这个可以保证只有一个请求会走到数据库,这是一种思路。 也可以选择JVM
锁保证了在单台服务器上只有一个请求走到数据库,通常来说已经足够保证数据库的压力大大降低,同时在性能上比分布式锁更好。需要注意的是,无论是使用“分布式锁”,还是“JVM 锁”,加锁时要按 key 维度去加锁。
我看网上很多文章都是使用一个“固定的 key”加锁,这样会导致不同的 key 之间也会互相阻塞,造成性能严重损耗。
-
热点数据不过期。直接将缓存设置为不过期,然后由定时任务去异步加载数据,更新缓存。 这种方式适用于比较极端的场景,例如流量特别特别大的场景,使用时需要考虑业务能接受数据不一致的时间,还有就是异常情况的处理,不要到时候缓存刷新不上,一直是脏数据,那就凉了。
三、缓存雪崩
解决方案
- 过期时间打散。既然是大量缓存集中失效,那最容易想到就是让他们不集中生效。可以给缓存的过期时间时加上一个随机值时间,使得每个 key
的过期时间分布开来,不会集中在同一时刻失效。 - 热点数据不过期。该方式和缓存击穿一样,也是要着重考虑刷新的时间间隔和数据异常如何处理的情况。
- 加互斥锁。该方式和缓存击穿一样,按 key 维度加锁,对于同一个
key,只允许一个线程去计算,其他线程原地阻塞等待第一个线程的计算结果,然后直接走缓存即可。















 113
113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









