






1. 基本环境的配置
2. 安装Zookeeper
3. 安装Hadoop
4. 安装Hbase
5. 构建数据仓库
注意事项和说明
- 这里用到三台虚拟机(尽量通过一台克隆为三台,使其IP地址连续,好记一些)
- 建议使用Xshell,连接虚拟机的IP地址,远程操作,使用得心应手啊
- 输入su和密码后直接切换到root用户
- vi和vim都可以啦,用vim配置文件好看…
- 一定要先把原Java版本移除,否则环境变量生效不了
1.1 修改主机名
暂时修改
hostname + 主机名称
永久修改
vim /etc/sysconfig/network ,进入后,修改内容如下
NETWORKING = yes
HOSTNAME = 主机名,这里设为master
然后保存退出编辑模式 :wq 回车
重启reboot,再 hostname 检验
1.2 配置host文件
vim /etc/hosts
输入个节点对应IP
保存退出
1.3 关闭防火墙(暂时关闭)
查看状态:systemctl status firewalld
关闭防火墙:systemctl stop firewalld
启动:systemctl start firewalld
1.4 时间同步
1.5 配置ssh免密
ssh-keygen -t dsa -->在 /.ssh 下产生公私密钥:id_dsa.pub为公钥,id_dsa为私钥
接下来把master的公钥内容copy和paste到slave1和slave2的id_dsa.pub公钥中,然后互相 ssh+主机名称,实现ssh免密登陆(ps: 第一次免密登陆需输入密码,以后不需要)
1.6 安装Jdk
- java-version \ 查看Java版本(原版本或自带版本)
- yum -y remove java +java原版本
- tar解压gz包到工作路径
- vim /etc/profile \ 修改环境变量
- source /etc/profile
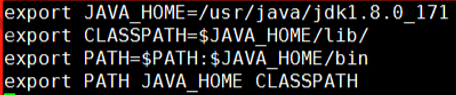
2.1 修改主机名称到IP地址映射配置
vim /etc/hosts
2.2 修改Zookeeper配置文件(PS:过程较为复杂,不易语言叙述,详解请@)
2.3 配置环境变量的示例代码(以实际版本改动)
2.4 source /etc/profile 修改环境变量生效后启动zookeeper集群
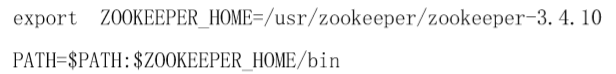
3.1 主要修改Hadoop的环境变量并source生效

3.2 注意各节点上使用jps命令查看进程,查看hdfs(hadoop分布式文件系统)
4.1 同上,修改hbase的环境变量
export HBASE_MANAGES_ZK=false
export JAVA_HOME=/usr/java/jdk1.8,0_171
export HVASE_CLASSPATH=/usr/hadoop/hadoop-2.7,3/etc/Hadoop
4,2 配置各文件
经过以上搭建,三台虚拟机中,master作为client客户端,slave1作为hive server 服务器端,slave2则安装mysql server
5.1 在slave2 上安装mysql server
- 安装EPEL源
yum -y install eqel-release- 翻墙下载社区版(免费)的mysql server包,下载源安装包:
wget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm- 安装源
rpm -ivh mysql157-community-release-e17-8.noarch.rpm- 安装mysql
yum -y install mysql-community-server- 启动服务
重载所有修改过的配置文件:systemctl daemon-reload
开启服务:systemctl start mysqld
开机自启:systemctl enable mysqld- 登陆mysql服务端
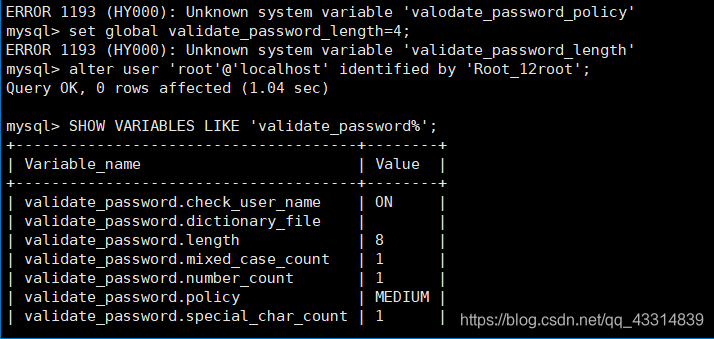
5.2 mysql 密码安全策略
- 设置密码强度为低级
set global validate_password_policy=low;
注意 回车后这里可能会出现一个特殊的问题
ERROR 1193 (HY000): Unknown system variable ‘validate_password_policy’
原因是在这个mysql版本中, 'validate_password_policy’变量不存在。
解决方案:先修改一个满足的密码 (如:Root_12root),密码修改后,可用命令查看 validate_password 密码验证插件是否安装
mysql> SHOW VARIABLES LIKE ‘validate_password%’;
之后重新调整密码规则
mysql> set global validate_password.policy=0;
mysql> set global validate_password.length=1;
ps: 详细解释参照https://blog.csdn.net/HaHa_Sir/article/details/80552663,表示感谢
5.3 设置远程登陆
- 以新密码登陆mysql:
mysql -root -p123456- 创建用户
create user ‘root’@’%’ identified by ‘123456’;- 允许远程连接
grant all privileges on . to ‘root’ @’%’ with grant option:- 刷新权限
flush privileges;
在mysql中,\q或ctrl + l表示退出
5.4 slave1上安装hive数据库
创建/usr/hive 文件夹,解压apache包,之后设置环境变量
export HIVE_HOME=/usr/hive/apache-hive-2,1,1-bin
export PATH= P A T H : PATH: PATH:HIVE_HOME/bin
…
5.5 启动hive数据库
把以有的数据资源或爬取的数据上传到Hdfs指定路径,再将其存放在制定的Hive表中
- 整个Hadoop的体系结构主要是通过HDFS(Hadoop distributed File System)来实现对分布式存储的底层支持。
- hive 和 hbase 的不同是hive基于数据仓库(即可直接导入数据成表),提供静态数据的动态查询,其使用类SQL语言,底层经过编译转为MapReduce程序,在Hadoop上运行,数据存储在HDFS上;hbase, 顾名思义,是hadoop databaseses的缩写,易得出hbase即hadoop数据库,它是一个适合于非结构化数据存储的数据库,HBase基于列的而不是基于行的模式。
- 而zookeeper是为hbase提供稳定服务和failover机制,相当于一种补救的,备份操作模式(来自网络)
- 而整体上,hadoop系统可以将数据分散存储在数以千记的节点上。数据在各个节点上执行mapreduce任务。"map"对数据进行映射运算,"reduce"对数据进行规约,ouput出来结果。














 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









