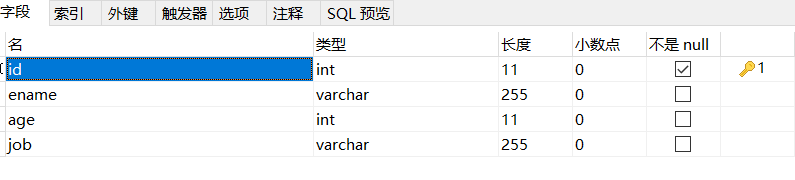
@Alias ( "employee" )
public class Employee {
private Integer id;
private String ename;
private Integer age;
private String job;
. . . .
}
package mao. shu. dao;
import mao. shu. vo. Employee;
public interface EmployeeDAO {
public Employee getEmpById ( Integer id) ;
public Integer addEmp ( Employee vo) ;
public boolean updateEmp ( Employee vo) ;
public boolean removeEmp ( Integer id) ;
}
编写sql映射文件—EmployeeMapper.xml <?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
< mappernamespace = " mao.shu.dao.EmployeeDAO" > < selectid = " getEmp" resultType = " mao.shu.vo.Employee" > </ select> < insertid = " addEmp" useGeneratedKeys = " true" keyProperty = " id" > </ insert> < updateid = " updateEmp" > </ update> < deleteid = " removeEmp" > </ delete> </ mapper> <?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
< configuration> < propertiesresource = " properties/datasource.properties" /> < environmentsdefault = " mysql" > < environmentid = " mysql" > < transactionManagertype = " JDBC" /> < dataSourcetype = " POOLED" > < propertyname = " driver" value = " ${jdbc.driver}" /> < propertyname = " url" value = " ${jdbc.url}" /> < propertyname = " username" value = " ${jdbc.username}" /> < propertyname = " password" value = " ${jdbc.password}" /> </ dataSource> </ environment> </ environments> < databaseIdProvidertype = " DB_VENDOR" > < propertyname = " MySql" value = " mysql" /> < propertyname = " Oracle" value = " oracle" /> </ databaseIdProvider> < mappers> < mapperresource = " config/EmployeeMapper.xml" /> </ mappers> </ configuration> package mao. shu. dao;
import mao. shu. vo. Employee;
import org. apache. ibatis. io. Resources;
import org. apache. ibatis. session. SqlSession;
import org. apache. ibatis. session. SqlSessionFactory;
import org. apache. ibatis. session. SqlSessionFactoryBuilder;
import org. junit. After;
import org. junit. Before;
import org. junit. Test;
import java. io. IOException;
import java. io. InputStream;
import static org. junit. Assert. *;
public class EmployeeDAOTest {
private SqlSession sqlSession;
@Before
public void before ( ) throws IOException {
String resource = "config/mybatis-config.xml" ;
InputStream inputStream = Resources. getResourceAsStream ( resource) ;
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder ( ) . build ( inputStream) ;
this . sqlSession = sqlSessionFactory. openSession ( ) ;
}
@After
public void after ( ) {
this . sqlSession. commit ( ) ;
this . sqlSession. close ( ) ;
}
@Test
public void testSelect ( ) {
EmployeeDAO employeeDAO = this . sqlSession. getMapper ( EmployeeDAO. class ) ;
Employee emp = employeeDAO. getEmpById ( 1 ) ;
System. out. println ( emp) ;
}
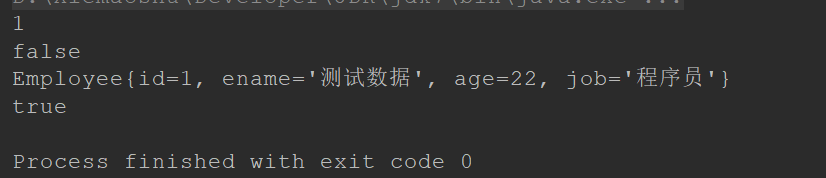
@Test
public void testUpdate ( ) {
EmployeeDAO employeeDAO = this . sqlSession. getMapper ( EmployeeDAO. class ) ;
Employee emp = employeeDAO. getEmpById ( 1 ) ;
emp. setEname ( "测试数据" ) ;
boolean flag = employeeDAO. updateEmp ( emp) ;
System. out. println ( flag) ;
}
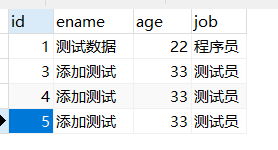
@Test
public void testInsert ( ) {
Employee emp = new Employee ( ) ;
emp. setEname ( "添加测试" ) ;
emp. setAge ( 33 ) ;
emp. setJob ( "测试员" ) ;
EmployeeDAO employeeDAO = this . sqlSession. getMapper ( EmployeeDAO. class ) ;
Integer result = employeeDAO. addEmp ( emp) ;
System. out. println ( result) ;
}
@Test
public void testRemove ( ) {
EmployeeDAO employeeDAO = this . sqlSession. getMapper ( EmployeeDAO. class ) ;
boolean flag = employeeDAO. removeEmp ( 2 ) ;
System. out. println ( flag) ;
}
}
要使用自增主键,首先在创建数据表的时候,就需要设置主键自增 只有数据库支持自动生成主键(例如:MySQL,SQL Server等数据库)
create table (
id int PRIMARY KEY AUTO_INCREMENT
)
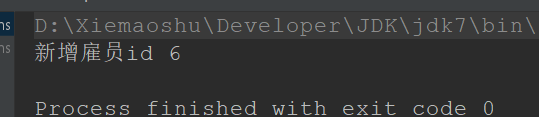
< insertid = " addEmp" useGeneratedKeys = " true" keyProperty = " id" > </ insert> @Test
public void testInsert ( ) {
Employee emp = new Employee ( ) ;
emp. setEname ( "添加测试" ) ;
emp. setAge ( 33 ) ;
emp. setJob ( "测试员" ) ;
EmployeeDAO employeeDAO = this . sqlSession. getMapper ( EmployeeDAO. class ) ;
Integer result = employeeDAO. addEmp ( emp) ;
Integer id = emp. getId ( ) ;
System. out. println ( "新增雇员id " + id) ;
}
Oracle不支持直接生成主键,在Oracle中使用序列的方式代替了自增主键 Oracle中创建序列的语法: CREATE SEQUENCE name
[ INCREMENT BY n]
[ START WITH n]
[ {MAXVALUE n | NOMAXVALUE}]
[ {MINVALUE n | NOMINVALUE}]
[ {CYCLE | NOCYCLE}]
[ {CACHE n | NOCACHE}]
使用序列创建数据 序列的使用 currval 表示序列的当前值,新序列必须使用一次nextval 才能获取到值,否则会报错 nextval 表示序列的下一个值。新序列首次使用时获取的是该序列的初始值,从第二次使用时开始按照设置的步进递增 示例: insert info tablename( id, feld) values ( sequenceName. nextval, field)
< insert id= "addEmp" databaseId= "oracle" >
< ! -- 设置查询主键值的sql语句
order 属性控制查询主键sql是在插入sql语句之前执行还是之后执行
BEFORE : 之前执行
AFTER : 之后执行
在执行添加语句之前, 会限制性< selectKey> ,
而后将查询出来的数据赋值给 keyProperty 对应的类属性
-- >
< selectKey keyProperty= "id" resultType= "integer" order= "BEFORE" >
SELECT EMPLOYEE_SEQ. nextval
FROM dual
< / selectKey>
INSERT INTO EMP ( empno, ename, job)
VALUES ( #{ id} , #{ ename} , #{ job} )
< / insert>
@Test
public void testInsert ( ) {
Employee emp = new Employee ( ) ;
emp. setEname ( "oracleTest" ) ;
emp. setJob ( "测试员" ) ;
EmployeeDAO employeeDAO = this . sqlSession. getMapper ( EmployeeDAO. class ) ;
Integer result = employeeDAO. addEmp ( emp) ;
Integer id = emp. getId ( ) ;
System. out. println ( "新增雇员id " + id) ;
}
示例:先插入数据,再查询序列值 Oracle中使用序列可以使用序列.nextval的方式直接获取序列下一个值,使用这样的方式插入数据,而后再使用"序列.currval"的方式取得刚刚插入的序列值. 在sql映射文件中支持使用<selectKey>标签中的order属性,控制查询序列值执行顺序. 这样的方式非常的不安全,可能会导致得到的序列值并非最新的,因此不建议使用 < insertid = " addEmp" databaseId = " oracle" > < selectKeykeyProperty = " id" resultType = " integer" order = " AFTER" > </ selectKey> </ insert>
#{参数名}:此时mybatis不会做任何处理,参数名可以任意取. 示例: < selectid = " getEmpById" resultType = " mao.shu.vo.Employee" > </ select> @Test
public void testSelect ( ) {
EmployeeDAO employeeDAO = this . sqlSession. getMapper ( EmployeeDAO. class ) ;
Employee emp = employeeDAO. getEmpById ( 1 ) ;
System. out. println ( emp) ;
}
多个参数会被封装成一个map,
key=param1,param2,或者为map索引0,1 value=传入的参数值 而"#{}"就是从map中获取指定的key的值
public Employee getEmpByIdAndName ( Integer id, String ename) ;
< selectid = " getEmpByIdAndName" resultType = " mao.shu.vo.Employee" > </ select> @Test
public void testgetEmpByIdAndName ( ) {
EmployeeDAO employeeDAO = this . sqlSession. getMapper ( EmployeeDAO. class ) ;
Employee emp = employeeDAO. getEmpByIdAndName ( 1 , "测试数据" ) ;
System. out. println ( emp) ;
}
明确指定封装参数是map的key 使用@Param注解修饰方法入参 修改接口定义的查询方法 public Employee getEmpByIdAndName ( @Param ( "id" ) Integer id, @Param ( "ename" ) String ename) ;
< selectid = " getEmpByIdAndName" resultType = " mao.shu.vo.Employee" > </ select> 如果多个参数正好是业务逻辑的数据模型,就可以直接传入POJO类对象. public Integer addEmp ( Employee vo) ;
< insertid = " addEmp" useGeneratedKeys = " true" keyProperty = " id" > </ insert> 如果多个参数不是业务模型中的数据,没有对应的pojo,为了方便,我们也可以传入Map对象. 此时"#{}"取出的就是map中对应的值 示例:接口方法定义 public Integer addEmpByMap ( Map< String, Object> ) ;
< insertid = " addEmpByMap" > </ insert> @Test
public void testAddByMap ( ) {
Map< String, Object> = new HashMap < > ( ) ;
map. put ( "ename" , "map添加测试" ) ;
map. put ( "age" , 33 ) ;
map. put ( "job" , "程序员" ) ;
EmployeeDAO employeeDAO = this . sqlSession. getMapper ( EmployeeDAO. class ) ;
Integer result = employeeDAO. addEmpByMap ( map) ;
System. out. println ( result) ;
}
如果多个参数不是业务模型中的数据,但是经常要使用,直接推荐来编写一个TO(Transfer Object) 数据传输对象. 例如,如果经常使用到分页功能,则可以将分页的基本数据包装为一个Page类 public class Page {
private Integer currentPage;
private Integer linesize;
}
当接口方法中定义了多个参数,但是其中包含POJO类的参数,此时MyBatis会如何处理? 例如: 其中参数id是单个的参数 而emp对应的类描述的是雇员表的信息 public void select ( Integer id, Employee emp)
那此时如果要在sql映射文件中获取方法的参数,因为两个参数都没有使用 @Param 注解修饰,所以MyBatis会默认将两个参数保存到Map集合中. 所以如果要取得第一个id参数内容则要使用 “#{param1}”,或者"#{0}的方式 #{param1}
#{0}
而如果要取得第二个参数"Employee"对象的lastName成员变量,则需要使用以下方式 #{param2.lastName}
特别注意:如果是Collection(List、Set)类型或者是数组 也会特殊处理。也是把传入的list或者数组封装在map中。key:Collection(collection), 如果是List还可以使用这个key(list) 数组(array) public Employee getEmpById ( List< Integer> ) ;
取值:取出第一个id的值: #{ list[ 0 ] }
获取每个标了param注解的参数@Param的值,id,lastName,赋值给Name 每次解析一个参数给map中保存信息(key:参数索引,value,name的值) public Object getNamedParams ( Object[ ] args) {
final int paramCount = names. size ( ) ;
if ( args == null || paramCount == 0 ) {
return null;
} else if ( ! hasParamAnnotation && paramCount == 1 ) {
return args[ names. firstKey ( ) ] ;
} else {
final Map< String, Object> = new ParamMap < Object> ( ) ;
int i = 0 ;
for ( Map. Entry< Integer, String> : names. entrySet ( ) ) {
param. put ( entry. getValue ( ) , args[ entry. getKey ( ) ] ) ;
final String genericParamName = GENERIC_NAME_PREFIX + String. valueOf ( i + 1 ) ;
if ( ! names. containsValue ( genericParamName) ) {
param. put ( genericParamName, args[ entry. getKey ( ) ] ) ;
}
i++ ;
}
return param;
}
}
}
#{}:是以预编译的形式,将参数设置到sql语句中:PreparedStatement ${}:取出的值直接拼装在sql语句中,会有安全问题 大多情况下:取参数的值都应该是用#{},但是有些时候,对于原生不支持占位符的情况就可以使用. 例如:sql语句中的表名字段无法使用占位符的方式设置参数 < select id= "getEmpByIdAndTableName" resultType= "mao.shu.vo.Employee" >
SELECT id, ename, age, job
FROM ${ tableName}
WHERE id = #{ id}
< / select>
< select id= "getAll" resultType= "mao.shu.vo.Employee" >
SELECT *
FROM employee
ORDER BY ${column }
< / select >
默认情况下如果参数作为"null"值被传入那么MyBatis会默认将其转换为"Type.Outher"类型,而Oracle数据库无法识别"Type.Other"类型,所以当使用Oracle的时候就可能会出现错误
这个时候可以在sql语句中取出参数时,设置jdbcType 属性,值为"NULL"大写 INSERT INTO EMP( empno, ename, job)
VALUES ( EMPLOYEE_SEQ. nextval,









































 662
662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









