







SIMD Technology and Streaming SIMD Extension 2
可以提升处理器性能的一种办法就是并行的执行多个计算,这样可以使用单条指令处理多个计算操作。实现这个办法就是使用单指令多数据(SIMD)计算技术。
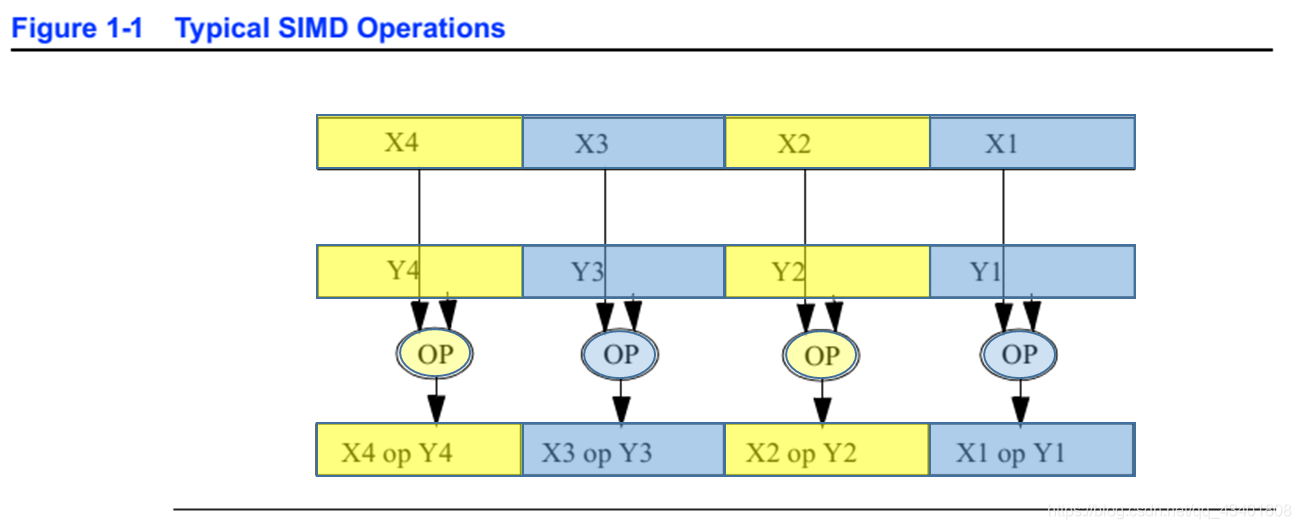
下图是一个典型的SIMD计算。一条指令指定要进行的计算类型(OP表示),8个数据元素(X1, X2, X3, X4和Y1, Y2, Y3, Y4)分成了两组,分别紧缩在各自的数据结构中。相应的数据元素对(X1与Y1; X2与Y2; X3与Y3; X4与Y4)同时执行相同的计算操作。计算的结果也是相应的紧缩数据元素。
上图描述的SIMD计算方式,最早是由IA32架构引入的MMX技术实现。MMX技术可以对存储在8个64位的MMX寄存器中的紧缩的字节,单字和双字上进行SIMD计算。MMX寄存器集参看下图。

Pentium III处理器扩展了最初的SIMD计算模型,引入了Streaming SIMD Extension,即SSE技术。SSE技术可以对紧缩的单精度浮点数进行SIMD计算,这些操作数可以位于存储器中或者8个128位的XMM寄存器中。 每个单精度浮点数是32比特位长,所以一个XMM寄存器可以保存4个浮点数据元素。内存中的操作数也遵循128位长。XMM寄存器参看下图:

此外,SSE还扩展了SIMD计算能力(即MMX指令集),引入了若干额外的64位的MMX指令。
Pentium 4处理器进一步扩展了SIMD计算模型,引入了SSE2指令集。SSE2没有增加新的寄存器,依然利用存储器操作数和128位的XMM寄存器进行计算。但是引入了两种新的数据类型:紧缩的双精度浮点数据类型以及128位的紧缩的整型数据类型。因此SSE2的144条指令可以操作如下的数据类型及其数据元素:2个紧缩的双精度浮点数,16个紧缩的字节,8个紧缩的单字,4个紧缩的双字,以及2个紧缩的四字类型。
注:回忆一下:SSE指令集只能操作4个紧缩的单精度浮点数。
MMX指令集与SSE/SSE2指令集联合在一起,使得程序员具有了操作(即设计算法)紧缩的64位/128位整型,以及单精度/双精度浮点数的能力。
SIMD计算能力提升了3D图形处理,语音识别,图像处理,科学计算,以及其他多媒体程序的性能。这些程序具有如下的特征:
- 内在的计算并行性
- 规律的,重复的内存访问模式
- 局部的,重复的操作数据
- 独立于数据的控制流
IA32架构上的 SIMD浮点指令完全遵循IEEE 754二进制浮点算术标准。而且这些指令在处理器的各种执行模式下都可用:模式模式,实地址模式,以及虚拟8086模式。
SSE/SSE2技术和MMX技术是对IA32体系结构在架构层面上的增强扩展。所有的现有软件,无需修改,都可以继续正确地运行在采用了这些技术的处理器上。现有软件也可以和使用了这些技术的新软件共同运行,互不干扰。
SSE和SSE2指令集也引入了控制数据可缓存性以及存储器操作的指令,用来提升高速缓存的利用率和程序性能。
Summary of SIMD Technology
下面我们按时间顺序总结一下添加到IA32架构上的SIMD技术的新特性:
MMX技术
- 64位MMX寄存器
- MMX指令操作紧缩的字节,单字,双字整型数据
- MMX指令主要用于多媒体及通信软件
- MMX技术的PRM:Order#:243007-002
SSE技术
- 128位XMM寄存器
- SSE指令操作紧缩的单精度浮点数据类型
- 引入数据预取指令
- 引入非临时存储指令(non-temporal instruction)以及其他的数据可缓存性指令,内存排序指令
- 新增额外的64位SIMD整型指令(即相当于扩充了MMX指令集)
- SSE技术主要用于3D几何,3D渲染,语音识别,以及视频编解码
SSE2技术
- 新增128位紧缩的双精度浮点数据类型
- 新增128位SIMD整型操作指令,作用于16字节,8单字,4双字,或2四字紧缩数据类型
- 新增支持对64位整型操作数进行SIMD计算
- 新增指令用于新增与现存数据类型进行转换
- 扩展对data shuffling的支持
- 扩展对可缓存性与内存排序操作的支持
- SSE2指令主要用于3D图形,视频编解码,以及加密计算














 594
594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









