







前言
Maxout实现起来几行代码就可以搞定,但是作者进行了很多实验、做了很多理论分析,其中一些经验还是比较值得一看,记录一下的。
注:本文仅供参考,博主水平有限,有些地方不一定讲述的对,大家可以指出,评论区一起讨论。
Description(概述)
maxout是Goodfellow设计的一种类似于dropout的网络结构,该网络结构可以更容易的被优化,并且效果也相当可观。
maxout模型通常是一个简单的前馈神经网络,可以用在多层感知机里,也也可以用在卷积神经网络里。
Detail(细节)
如果我们用在前馈神经网络中某层中使用maxout,那么给定输入
x
∈
R
d
x∈\mathbb{R^d}
x∈Rd,那么该层的输出如下:
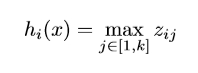
其中
z
i
j
=
x
i
T
W
i
j
+
b
i
j
z_{ij} = x_{i}^TW_{ij} + b_{ij}
zij=xiTWij+bij
上面两个式子中,一共有3个参数,k(人为设定)、W和b是学习得到的。
说明一下维度信息
W
∈
R
d
×
m
×
k
W∈\mathbb{R^{d\times m\times k}}
W∈Rd×m×k,
b
∈
R
m
×
k
b∈\mathbb{R^{m\times k}}
b∈Rm×k
k是指有几组参数、d是输入数据的维度、m是指当前层隐藏单元的个数。
maxout可以和dropout一起使用,而且效果颇佳。做法就是只需将k个权重矩阵与dropout mask 对应元素相乘,然后再取同位置最大值即可。原文如下:
When training with dropout, we perform the elementwise multiplication with the dropout mask immediately prior to the multiplication by the weights in all cases–we do not drop inputs to the max operator.
maxout不光是可以学习到隐藏层的参数 W W W,它还可以为每个隐藏单元单独的学习一个激活函数,也就是说maxout层的每个隐藏单元的激活函数都是不一样的。这使得maxout层可以拟合任何凸函数
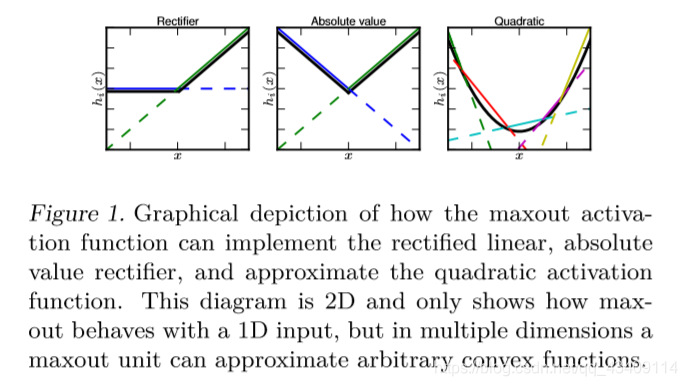
上图就简单的描述了maxout强大的拟合功能。图中不同颜色的曲线代表的是不同W与X进行乘法得到的值。可以看到在图1中,maxout拟合出了一个relu函数,图2拟合出来了一个绝对值函数,图三拟合了一个二次函数。
maxout层的激活值并不稀疏,但由于使用max函数,所以其梯度是高度稀疏的。原文描述如下
The representation it produces is not sparse at all (see Fig. 2), though the gradient is highly sparse and dropout will artificially sparsify the effective representation during training
Maxout几乎不会发生饱和现像(这会导致梯度消失),但是如果隐藏单元的输出是有界的话,它是可以学习到,并且Maxout几乎在任何地方都是局部线性的。
While a significant proportion of parameter space corresponds to the function being bounded from below, maxout is not constrained to learn to be bounded at all. Maxout is locally linear almost everywhere, while many popular activation functions have signficant curvature
对于一个多层感知机来说,只要其层数够多,隐藏单元够多,几乎可以逼近任何函数,maxout也是如此,而且效果要比多层感知机更好一些。
作者证明了,maxout网络,只需要2个隐藏单元就可以逼近任何连续的函数,当然,这个k可能是需要非常大的。
Benchmark(测试)
作者在4个数据集上进行了实验,分别是MNIST、CIFAR-10、CIFAR100、Street View House Numbers
一、MNIST
作者使用了三个卷积的maxout隐藏层,在第一层有一个max pooling,最后接了一个softmax的全连接层。
(这里提一下在卷积层中怎么使用maxout,并不是说每个卷积核有k个,而是说卷积之后有channel个feature maps,取其中最大的最为最终结果)
其实验结果如下

可以看到,效果是比较好的。
二、CIFAR-10
作者先是使用卷积+maxout+dropout在CIRFAR-10上错误率达到11.68%,也是非常出色了。如果在使用数据增强,错误率可降低到9.38%
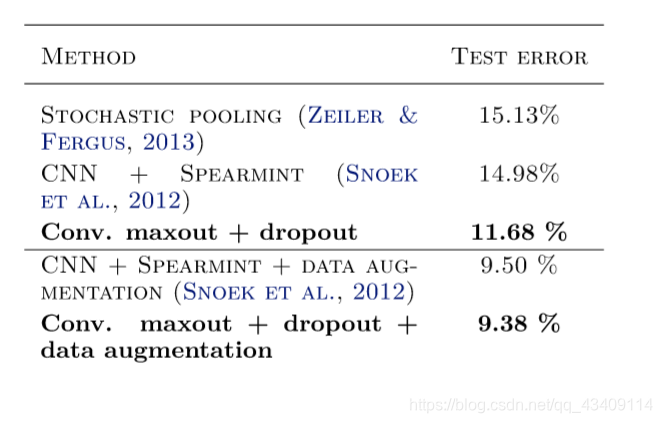
如果你使用了maxout,一般来说是要配合着dropout一起使用的,下图就描述了当使用maxout时,是否使用dropout对Error的影响
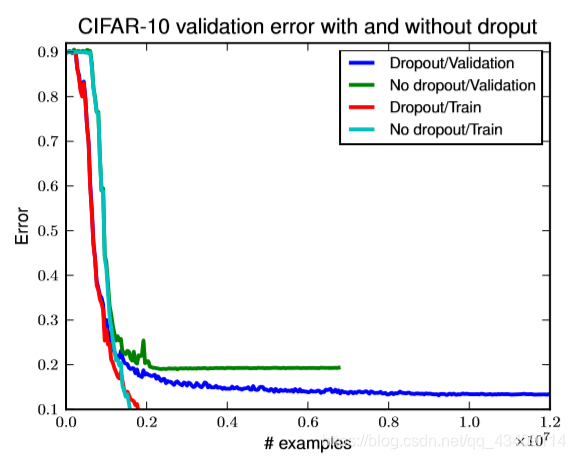
可以看到,如果使用dropout的话,模型的效果提升了很多。
三、CIRFAR-100

效果如上,不过作者并没有在此部分赘述太多。原文如下
The CIFAR-100 (Krizhevsky & Hinton, 2009) dataset is the same size and format as the CIFAR-10 dataset, but contains 100 classes, with only one tenth as many labeled examples per class. Due to lack of time we did not extensively cross-validate hyperparameters on CIFAR-100 but simply applied hyperparameters we found to work well on CIFAR-10. We obtained a test set error of 38.57%, which is state of the art. If we do not retrain using the entire training set, we obtain a test set error of 41.48%, which also surpasses the current state of the art. A summary of the best methods on CIFAR-100 is provided in Table 4.
四、SVHN
SVHM这个数据集是谷歌收集来的,均来自真实世界的数字的图片,类似于MNIST。
作者在这个数据集上实验的效果如下:
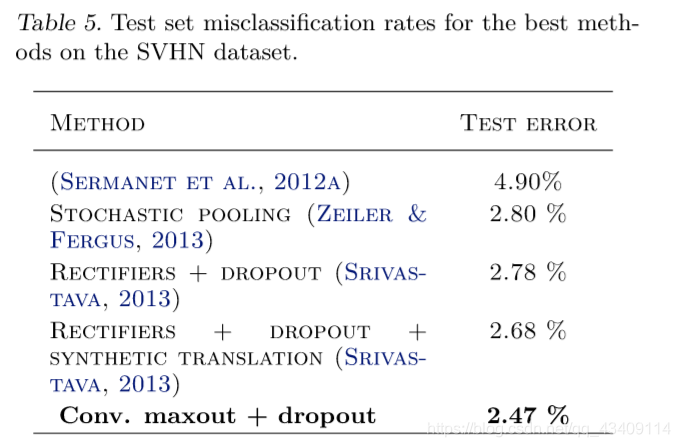
其训练方式的原文描述如下:
For SVHN, we did not train on the validation set at all. We used it only to find the best hyperparameters. We applied local contrast normalization preprocessing the same way as Zeiler & Fergus (2013). Otherwise, wefollowedthesameapproachasonMNIST.Ourbest model consists of three convolutional maxout hidden layers and a densely connected maxout layer followed by a densely connected softmax layer. We obtained a test set error rate of 2.47%, which sets the state of the art. A summary of comparable methods is provided in Table 5.
Comparison to rectifiers(比较)
有人可能会有疑问,maxout取得这么好的效果是不是因为模型本身比较大或者因为使用了一些比较厉害的预处理技术。所以作者在此部分,进行了一系列实验。
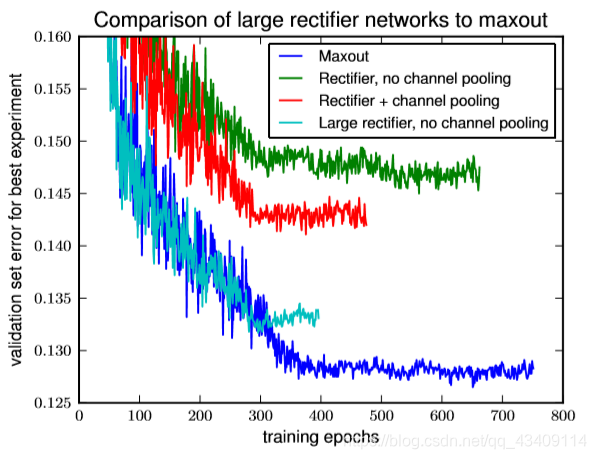
这一部分我也看的有点懵,就不写了。
Model averaging
在这一部分,GoodFellow主要就是通过实验验证了,当我们实验dropout的时候,为什么要对权重进行放缩。
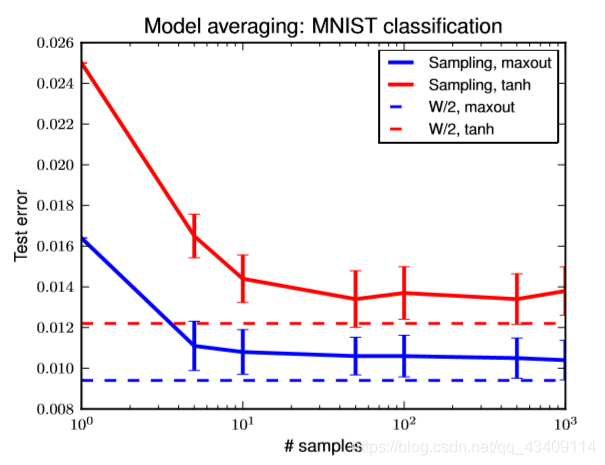
他的实验步骤是差不多是这样的,首先使用dropout进行训练,模型训练完成之后,就相当于是训练了非常多的子模型,GoodFellow就从这些子模型中随机采样一些,然后单独拿出来进行预测,一种情况下是对权重进行缩放,另一种情况是不对权重进行缩放,通过上图可以知道,当进行对权重进行缩放时,采样出的子模型Test Error比较稳定,而没有缩放的则误差比较大。
Optimization(优化)
通常在训练的时候,我们可能会采样随机梯度下降法,这种方法最好把学习率设置小一些,学习率小就会导致损失函数逐步、慢慢地、一点一点的下降,波动比较小。
然而在使用dropout进行训练的时候,通常会把学习率调的稍大一些,这就会导致目标函数损失值波对比较大。
原文描述如下:
SGD usually works best with a small learning rate that results in a smoothly decreasing objective function, while dropout works best with a large learning rate, resulting in a constantly fluctuatingobjectivefunction
GoodFellow发现,如果我们使用relu作为激活函数,然后对网络进行训练的话,其激活值饱和到0的隐藏单元所占比例是比较小的。然而如果我们使用relu+dropout来进行训练的话,在训练的过程中,隐藏单元饱和到0的比例会逐渐增长到60%!。这就导致了部分参数可能不会更新。
We find empirically that these different operating regimes result in different outcomes for rectifier units. When training with SGD, we find that the rectifier units saturate at 0 less than 5% of the time. When training with dropout, we initialize the units to sature rarely but training gradually increases their saturation rate to 60%. Because the 0 in the max(0,z) activation function is a constant, this blocks the gradient from flowing through the unit. In the absence of gradient through the unit, it is difficult for training to change this unit to become active again.
但是Maxout却不会有上述现像,GoodFellow这样解释的,对于relu来说,其函数形式为max(0,z),这里的0是常数,而maxout,其函数值均是由变量决定的。所以尽管在某一阶段可能某个隐藏单元的激活值变成0,但是后面随着网络的调整,其值又会波动的。
Maxout does not suffer from this problem because gradient always flows through every maxout unit–even when a maxout unit is 0, this 0 is a function of the parameters and may be adjusted Units that take on negative activations may be steered to become positive again later.
大佬GoodFellow做了一个实验,一个两层的MLPs…然后用某种方法进行训练,结果第一层有17%的参数没有被利用,第二层有39.22的参数没有理由到
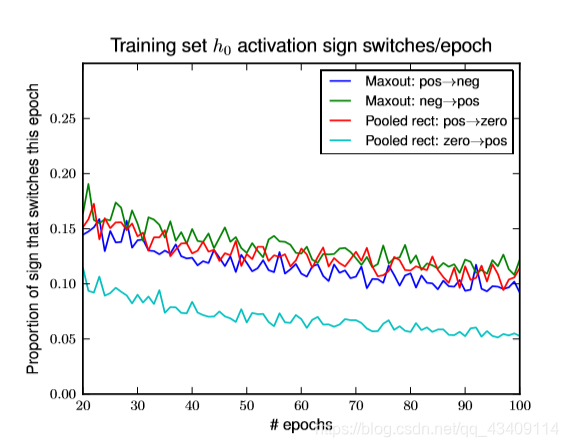
上述图片是说明了,如果采样Maxout+dropout 无论是激活值是从正数变到负数,还是负值变到正值,其比例都大致差不多。而对于rectifier units来说,正值变到0简单(也就是比例比较大),但是想从0再变回正值就很苦难了(也就是比例比较小)
总结
- Maxout和dropout一起使用,可以让Maxout中的隐藏单元在每次drop掉的input不同时,学习到差不多相似的激活函数。
- Maxout参数是普通的MPL的k倍,所以参数变多了
- Maxout最好配好上dropout一起使用
- 使用Maxout允许我们的网络比较深
- Maxout可以让dropout训练起来更容易















 720
720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











