







5 Spark核心编程
Spark提供三种数据结构:RDD(弹性分布式数据集)、累加器(分布式共享只写变量)、广播变量(分布式共享只读变量)
5.1 RDD
RDD(Resilient Distributed Dataset)弹性分布式数据集。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
- 弹性:
- 存储的弹性:内存与磁盘的自动切换
- 容错的弹性:数据丢失可以自动恢复
- 计算的弹性:计算出错重试机制
- 分片的弹性:可根据需要重新分片
- 分布式:数据存储在大数据集群不同节点上
- 数据集:RDD封装了计算逻辑,并不保存数据
- 数据抽象:RDD是一个抽象类,需要子类具体实现
- 不可变:RDD封装了计算逻辑,是不可变的,想要改变,只能重新产生新的RDD,在新的RDD里封装计算逻辑
- 可分区,并行计算。
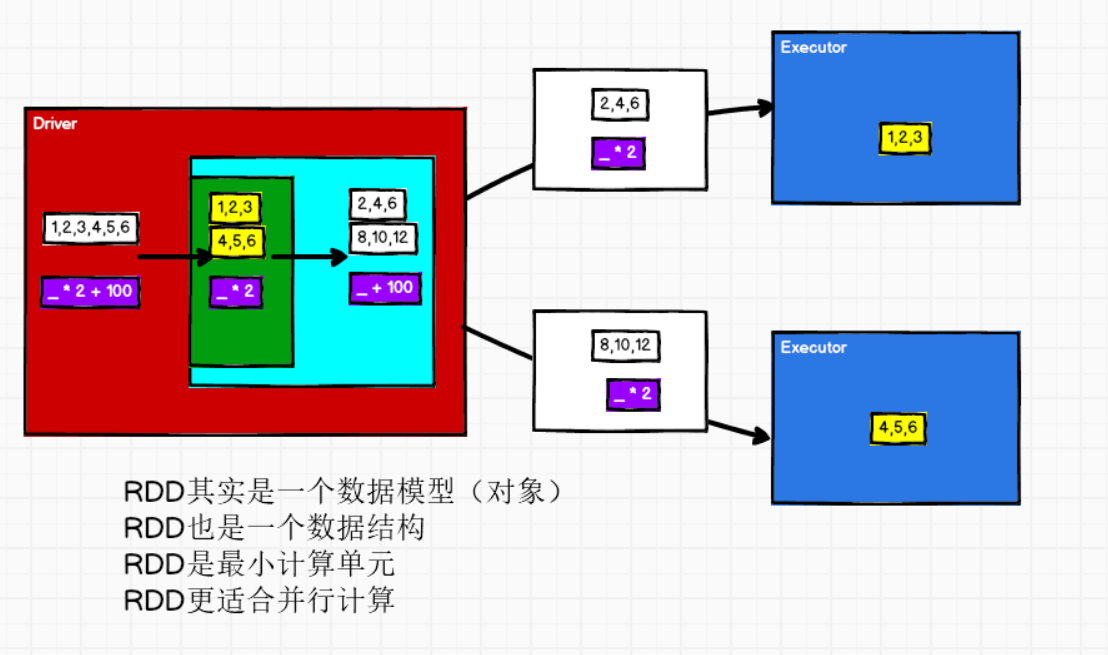
- RDD其实是一个数据模式(对象),就是一个抽象类abstract class RDD[T: ClassTag](),里面有5个核心配置
- RDD也是一个数据结构
- RDD是最小的计算单元:每一个RDD只能完成一个单独的逻辑。
- RDD将数据分区,所以才更适合并行计算。
①移动计算
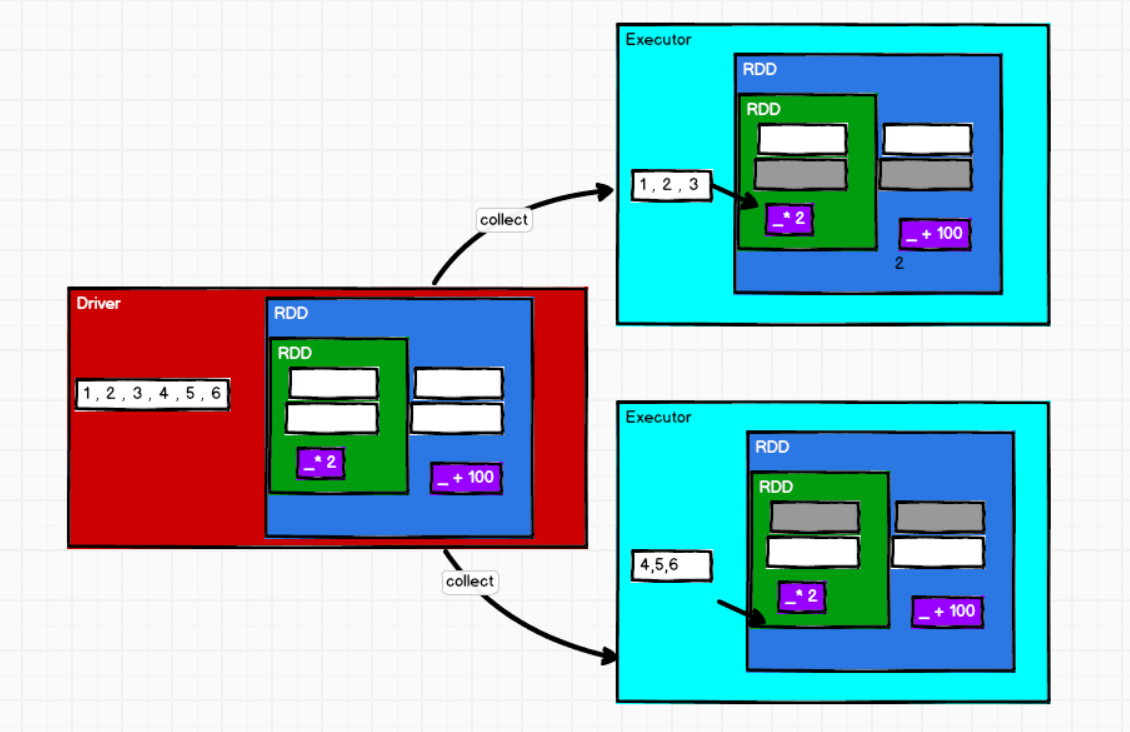
②RDD不存储数据
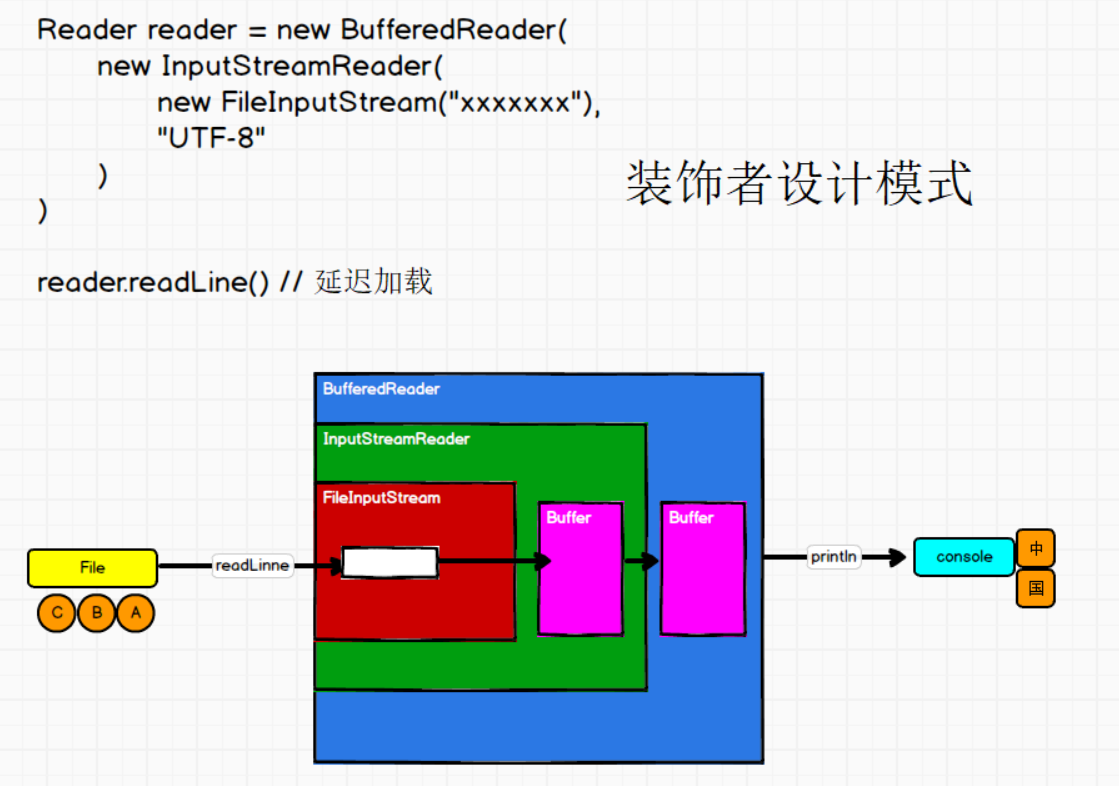
③装饰者设计模式
IO的数据流一层一层包装,就是装饰者设计模式
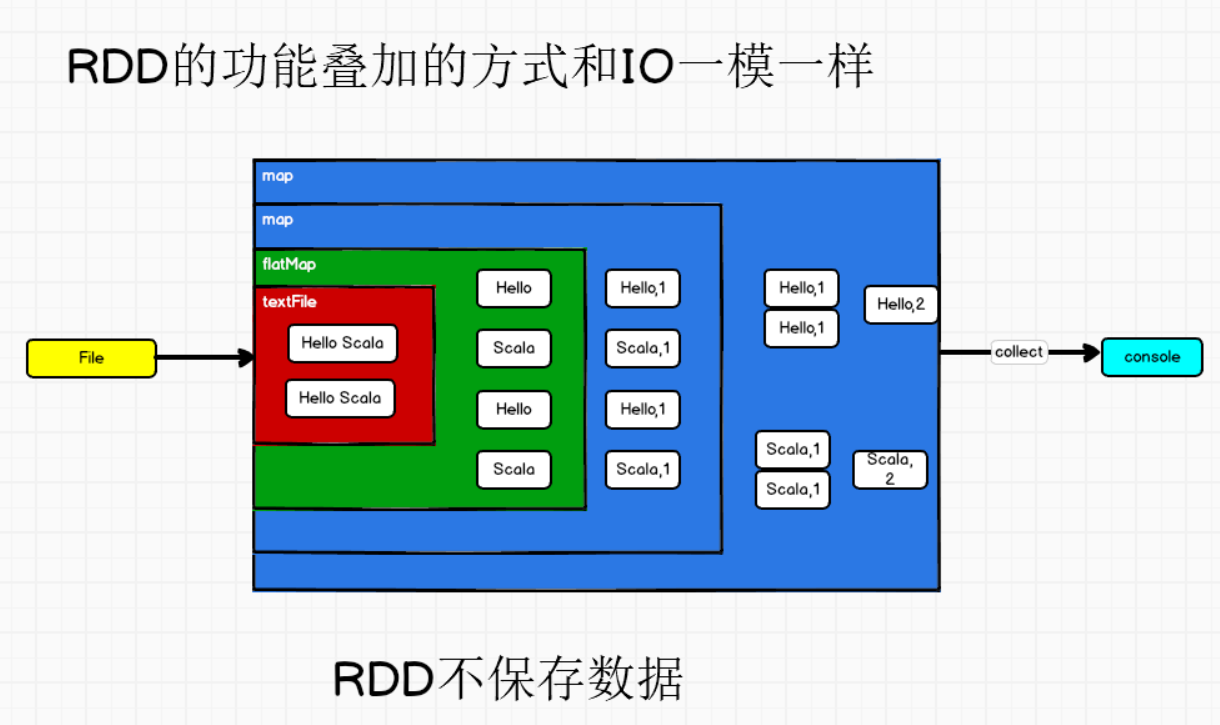
④核心属性
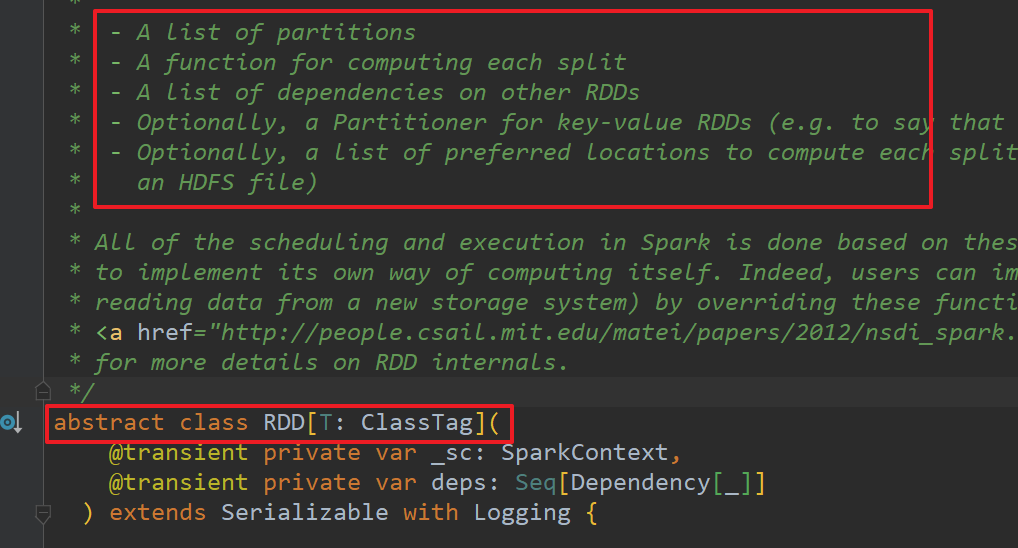
- 一个分区列表:也就是将List(1, 2, 3, 4)分区。(1, 2)核(3, 4)为两个分区
protected def getPartitions: Array[Partition]
-
每个切片有一个计算函数:计算函数是以分区为单位的
-
其他的RDD之前有一个依赖列表
-
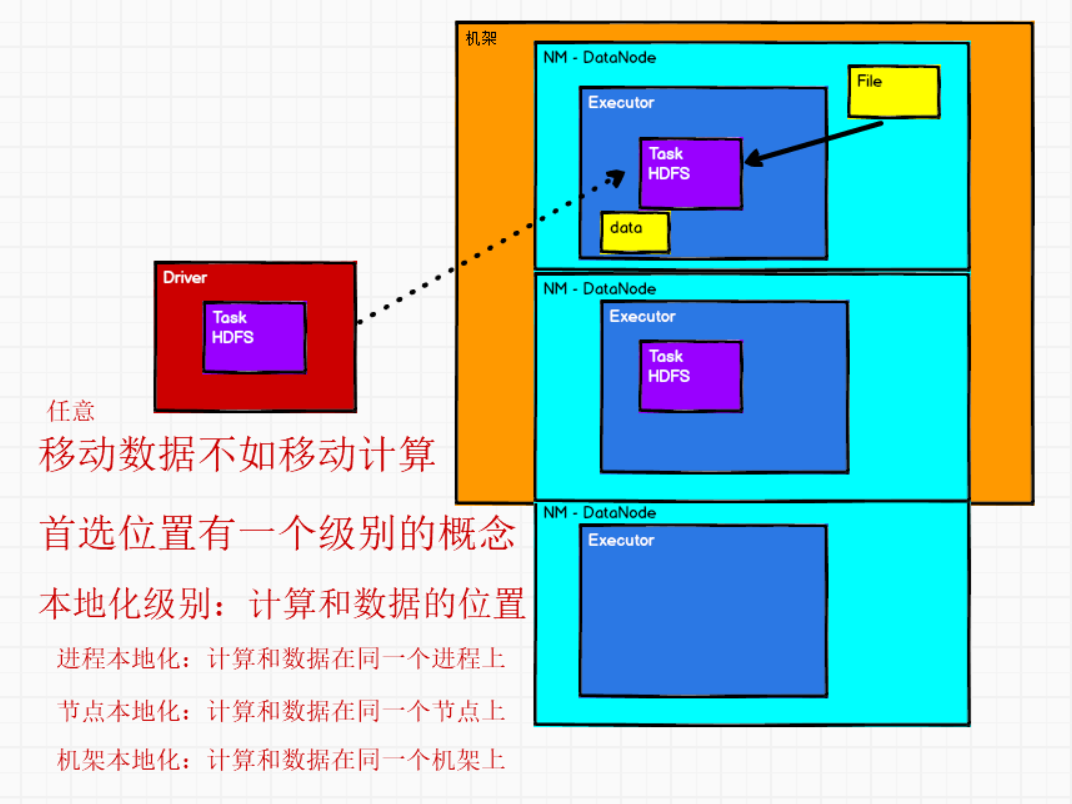
可选的,分区器用来指定来的数据到哪个分区。基本原则是,相同的key进入相同的分区
-
可选的,分区计算的首选位置:移动数据不如移动计算。
也就是数据在哪,计算就移动到哪。
⑤执行原理
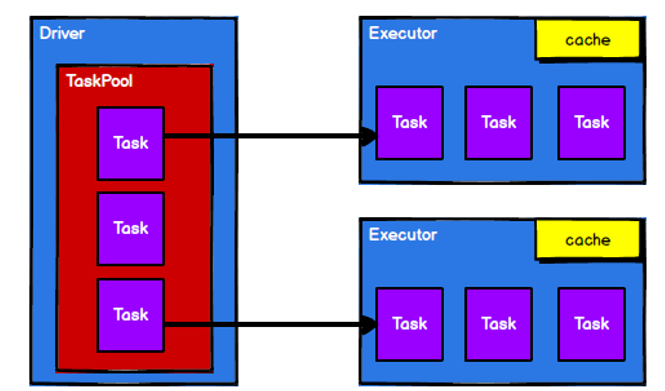
Spark框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将计算任务发到已经分配资源的计算节点上,然后按照计算模型进行数据计算。
步骤1:启动Yarn集群环境
步骤2:Spark通过申请资源创建Driver和Executor
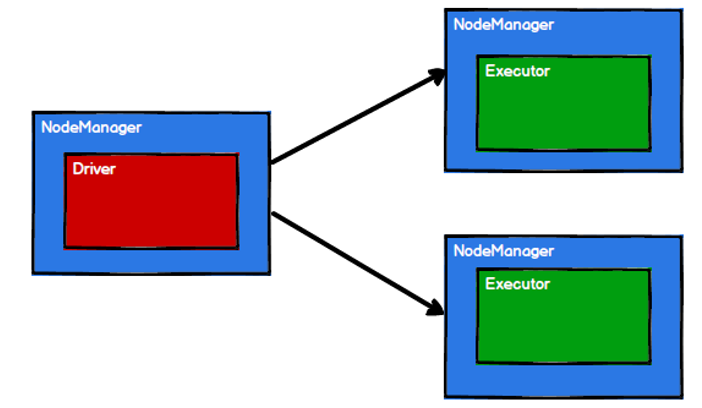
步骤3:Spark框架根据需求将计算逻辑根据分区划分成不同的任务
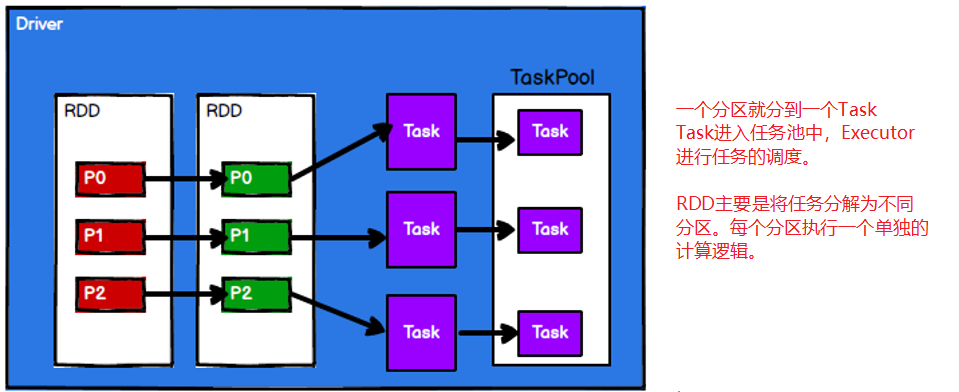
步骤4:Driver将Task根据节点状态发送到对应的计算节点Executor进行计算。
5.2 创建RDD
①从集合(内存)创建RDD
object Spark_RDD_Create {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(conf)
//RDD的创建一般采用从内存,从磁盘中创建
//RDD:弹性,分布式,数据集
// 对指定数据集(源)数据处理的数据模式
//RDD需要处理的数据源可能来自于内存,也可能来自文件
//TODO 从内存中加载数据源
//TODO 方式1:parallelize:并行,可以从内存数据源创建RDD
val seq = Seq(1, 2, 3, 4)
val list = List(1, 2, 3, 4)
val rdd: RDD[Int] = sc.parallelize(seq)
//TODO 方式2:makeRDD的底层调用就是parallelize,就是为了使用方便所提供的方法
val rdd1 = sc.makeRDD(list)
sc.makeRDD(List(11, 22, 33, 44))
rdd.collect().foreach(println)
rdd1.collect().foreach(println)
sc.stop()
}
}
②从外部文件创建RDD
sc.textFile()
object Spark_RDD_Create_File {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(conf)
//TODO 从文件中加载数据源
//从文件加载数据源,需要设定文件路径,这个路径可以是绝对路径,也可以是相对路径
//相对路径的话:是相对当前project
//Spark读取文件采用的是Hadoop读取的原理
//文件路径可以读取本地文件,也可以是HDFS中存储的文件
//到底读取的是本地文件还是HDFS文件,可以根据运行环境来确定
//1 文件读取可以是具体的文件
//返回的RDD[String]表示后续操作的数据类型为字符串,这里的字符串其实就是文件每一行数据
// val lines: RDD[String] = sc.textFile("input/word.txt")
//2 文件读取也可以是一个文件夹内的多个文件
val lines: RDD[String] = sc.textFile("input")
val words: RDD[String] = lines.flatMap(_.split(" "))
val wordToOne: RDD[(String, Int)] = words.map((_, 1))
val wordToSum: RDD[(String, Int)] = wordToOne.reduceByKey(_ + _)
wordToSum.collect().foreach(println)
sc.stop()
}
}
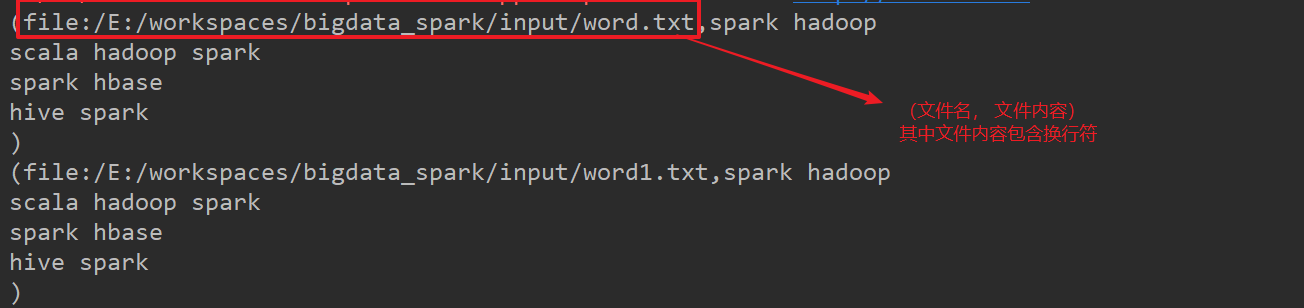
sc.wholeTextFiles()
可以用来判断某一个单词来自于哪一个文件。
- 返回值的RDD[(String, String)]第一个数据为文件名绝对路径,第二个数据为文件的完整内容
object Spark_RDD_Create_File_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
val sc = new SparkContext(conf)
val rdd: RDD[(String, String)] = sc.wholeTextFiles("input")
rdd.collect().foreach(println)
sc.stop()
}
}
③从其他RDD创建
一个RDD运算完成后,产生一个新的RDD
④直接创建一个RDD(new)
使用new的方式直接构建RDD,一般由Spark框架自身使用
5.3 RDD并行度与分区
①并行度
默认情况下,Spark的Driver将一个作业切分成多个Task任务,发送给不同的Executor节点并行计算。能够并行计算的Task数称为并行度。
这个数量在创建RDD时指定,并行执行的任务数量并不是切分任务的数量。
②分区数量设置
-
setMaster(local[*])获取当前环境中总共的核数,也就是分区数量。优先级最低。
setMaster(local)默认是1,1个分区
setMaster(local[3])指定当前环境中虚拟的核的数量,指定为3个分区
-
从配置对象中获取指定的配置参数。优先级第二
conf.set(“spark.default.parallelism”, “5”)
val conf = new SparkConf().setMaster("local").setAppName("WordCount") conf.set("spark.default.parallelism", "5") -
在创建RDD的时候设置分区
makeRDD的第二个参数表示分区数量。优先级最高
其源码为:如果不写那么会有默认值totalCores
scheduler.conf.getInt("spark.default.parallelism", totalCores)val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 3)
object Spark_RDD_Memory_Parts {
def main(args: Array[String]): Unit = {
//RDD的分区
//TODO makeRDD()内设定的分区数,优先级最高;其次是conf.set();最后是当前环境总共的核数local[*]
//获取RDD的分区数量:rdd.getNumPartitions
//3 获取当前环境中的总共的核数
val conf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2 从配置对象中获取指定的配置参数
// conf.set("spark.default.parallelism", "5")
val sc = new SparkContext(conf)
//1 makeRDD的第二个参数表示分区数量,如果设定,那么spark会按照这个数值进行分区
//scheduler.conf.getInt("spark.default.parallelism", totalCores)
// val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 3)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4)) //默认是一个分区
// 将结果按照分区存储到文件内
rdd.saveAsTextFile("output")
sc.stop()
}
}
③makeRDD的分区数据分配原理
分区编号默认由0开始的
-
默认分区1的话,那么所有的数据都会到一个分区文件中
-
如果分区数为3,数据为List(1, 2, 3, 4, 5, 6),那么会平均分到3个分区文件中;1 2 在part-0;3 4在part-1;5 6在part-2
数据个数可以整除分区数。
-
如果分区数为3,数据为List(1, 2, 3, 4, 5),那么会根据如下算法选择分区文件;1 在part-0;2 3在part-1;4,5在part-2
数据个数不能够整除分区数
val rdd1: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5), 3) //1 parallelize(seq, numSlices) //2 new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]()) //3 override def getPartitions: Array[Partition] = {slice()} //4 slice() case _ => val array = seq.toArray positions(array.length, numSlices).map { case (start, end) => array.slice(start, end).toSeq }.toSeq //5 def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = { (0 until numSlices).iterator.map { i => val start = ((i * length) / numSlices).toInt val end = (((i + 1) * length) / numSlices).toInt (start, end) } }List(1, 2, 3, 4, 5) length = 5 numSlices = 3 (0 until numSlices) => 0, 1, 2 0 => (start, end) => (0, 1) => 1 1 => (start, end) => (1, 3) => 2 3 2 => (start, end) => (3, 5) => 4 5数据个数不能整除分区数小练习:
val rdd1: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 4) //0 (0, 1) 1 //1 (1, 3) 2 3 //2 (3, 4) 4 //3 (4, 6) 5 6
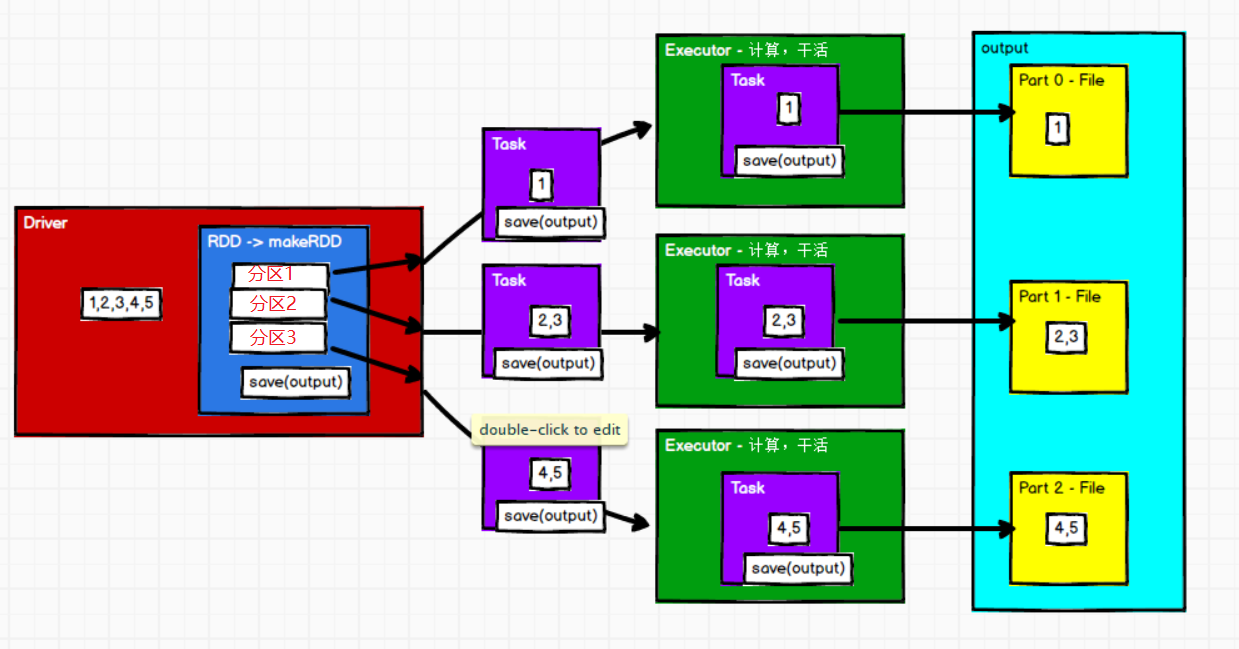
④执行过程梳理
⑤文件获取数据的分区分配原理
textFile有两个参数:第一个为文件路径;第二个参数表示最小分区数,有默认值,在调用时,可以不用传递。
math.min(defaultParallelism, 2)
Spark的文件其实采用的是Hadoop操作,源码如下:
//1
classOf[TextInputFormat]
//2
FileInputFormat
//3
public InputSplit[] getSplits(JobConf job, int numSplits)
for (FileStatus file: files) {
totalSize += file.getLen();
}
//4 如果numSplits切片数是0那么就为1;如果不为0那就是numSplits
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
/*
totalSize : 3个字节
//goalSize每个分区应该往里面放的字节数
goalSize : 3/2 = 1
分区数:一共3个字节/每个分区放1个字节 = 3个分区,所以会有3个文件
*/
文件作为数据源,分区计算方式:
-
计算所有文件总的字节数
-
用总字节数除以指定的分区数量,获取每个分区应该存储的字节数
-
因为不一定能整除,所以需要计算需要多少分区才能容纳所有的数据
总的字节数 / 每个分区存储的字节数…余数
剩余的字节数是否超过每个分区存储字节数的10% => 1.1倍
object Spark_RDD_File_Parts {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
//textFile有2个参数
//第一个参数表示文件路径;第二个参数表示最小分区数,有默认值,在调用时,可以不用传递
//
val rdd: RDD[String] = sc.textFile("input/word1.txt", 3)
//TODO 文件作为数据源,分区计算方式
//1. 计算所有的文件总的字节数
//2. 用总的字节数除以指定的分区数量,获取每个分区应该存储的字节数
//3. 如果能够整除,那么商就是真正的分区数。
// 如果不能够整除,所以需要计算需要多少个分区才能容纳所有的数据。
// 总的字节数 / 每个分区应该存储的字节数 ...... 余数
// 剩余的字节数是否超过每个分区存储字节的10% => 1.1倍
// 如果剩余的字节数超过10%,那么旧产生一个新的分区存储;如果没有超过10%,那么就和前面数据放在一个分区。
/*
* TODO 分区数怎么确定?
* 7个字节
* 分区数为3
* 每个分区存储7/3=2...1
* 7/2 = 3...1 有3个分区剩余1个字节
* 其中1/2= 50% > 10%所以多生成一个分区,分区数为4
*
* TODO 数据怎样分到分区内?
*1@@ 012
*2@@ 345
*3 6
*
[0-2]是字节/分区(容量!!!)
* part-0 [0-2] 【1】
* part-1 [2-4] 【2】
* part-2 [4-6] 【3】
* part-3 [6] 【】
*
* */
rdd.saveAsTextFile("output")
sc.stop()
}
}
object Spark_RDD_File_Parts_2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.textFile("input/word1.txt", 2)
/*
* TODO 分区数量怎么确定?
* 总共7个字节
* 设定minPartitions为2
* 每个分区分配7 / 2 = 3个字节
*
* 7 / 3 = 2...1 其中1 / 3 > 10% 所以一共有3个分区
*
* TODO 数据进入哪个分区?
* 字节 偏移量
* 1@@ 012
* 2@@ 345
* 3 6
*
* part-0 [0-3] 【12】
* part-1 [3-6] 【3】
* part-2 [6] 【】
* */
rdd.saveAsTextFile("output")
sc.stop()
}
}
5.4 RDD转换算子
Spark的RDD对象根据功能不同分为了两类:转换算子transform、行动算子action
算子其实就是一个方法,一个操作,为了和scala中的方法区分开。
object Oper01 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
//Spark的RDD对象包含了很多的方法(算子)
//这些方法根据功能的不同分为2类
//TODO 1 转换(transform),通过调用方法,将旧的RDD转换为新的RDD
val rdd1: RDD[Int] = rdd.map(_ * 2)
//TODO 2 行动(action),通过调用方法,将RDD开始执行
rdd1.collect().foreach(println)
sc.stop()
}
}
①map
map算子是用来转换结构,转换会创建新的RDD时,分区数量不变。
多个RDD所形成的依赖关系中,每一条数据必须全部的功能执行完毕后,才能继续执行后续操作。
object Oper02_map {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5), 3)
rdd.saveAsTextFile("output")
//TODO RDD - 转换算子 - map
//map:转换,将数据源中的每一个数据转换成其他数据返回
//转换算子默认情况下,创建新的RDD时,分区数量不变
//分区数据处理后所在的分区也不会发生变化
val rdd1: RDD[Int] = rdd.map(num => {
println("************************")
num * 2
})
rdd1.collect()
sc.stop()
}
}
object Oper03_map {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
//多个RDD所形成的依赖关系中,每一条数据必须全部的功能执行完毕后,才能继续执行后续操作
val rdd1: RDD[Int] = rdd.map(num => {
println(num + "==========================")
num
})
val rdd2: RDD[Int] = rdd1.map(num => {
println(num + "*********************")
num
})
rdd2.collect()
sc.stop()
}
}
②mapPartitions
mapPartitions算子用于将一个分区的数据同时进行转换
将一个分区的数据都加载到内存中进行处理,性能比较高,类似于批处理
mapPartitions算子依赖于内存大小,内存小的情况下,不推荐使用
算子中处理的每一条数据处理完毕后,并不会被回收掉,只有整个分区的所有数据全部处理完毕,才会回收,内存可能会溢出。
object Oper04_mapPartitions {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
//mapPartitions算子用于将一个分区的数据同时进行转换
//将一个分区加载到内存中进行处理,性能比较高,类似于批处理
//mapPartitions算子依赖于内存大小。如果内存小的情况下,不推荐使用
//算子中处理的每一条数据处理完毕后,并不会被回收掉,只有整个分区的所有数据全部处理完毕,才会回收
//内存可能会溢出
val rdd1: RDD[Int] = rdd.mapPartitions(iter => {
println("************************")
iter.map(_ * 2)
})
rdd1.collect().foreach(println)
sc.stop()
}
}
③mapPartitionsWithIndex
- 以分区为单位,给每个分区建立索引值Index(可以根据索引值来过滤某一个分区的值)
object Oper05_mapPartitionsWithIndex {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
//以分区为单位,给每个分区建立索引值index
val rdd1: RDD[Int] = rdd.mapPartitionsWithIndex {
case (index, iter) => {
//可以用来过滤某一个分区:
if (index == 1)
iter
else
Nil.iterator
}
}
rdd1.collect().foreach(println) //1 2
sc.stop()
}
}
④flatMap
- 将处理的数据进行扁平化后再进行映射处理,所以算子也称之为扁平映射
fill [泛型] (数组维度) (要填充的元素)
object Oper06_flatMap {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
//创建RDD
val rdd: RDD[String] = sc.makeRDD(List("Hello Scala", "Hello Spark"))
val rdd1: RDD[String] = rdd.flatMap(_.split(" "))
//创建RDD
val rdd2 = sc.makeRDD(List(List(1, 2),3, List(4, 5)))
//模式匹配如果不是List[_]那么就转成List
val rdd3 = rdd2.flatMap {
case list: List[_] => list
case l => List(l)
}
println(rdd3.collect().mkString(", "))
sc.stop()
}
}
⑤glom
- 将一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变
object Oper07_glom {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5), 1)
//TODO glom() 将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变
val rdd1: RDD[Array[Int]] = rdd.glom()
rdd1.collect().foreach(println) //[I@f4c0e4e
rdd1.collect().foreach(data => println(data.mkString(", "))) //1, 2, 3, 4, 5
sc.stop()
}
}
案例:计算所有分区最大值求和(分区内取最大值,分区间最大值求和)
方式1:使用mapPartitions(iter => {List(iter.max).iterator})求得每个分区的最大值,然后求和
方式2:使用glom将每个分区分到一个Array内,然后每个Array内求最大值,然后reduce求和
object Oper07_glom_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
// 小功能:计算所有分区最大值求和(分区内取最大值,分区间最大值求和)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 3)
//【1,2】【3,4】【5,6】
//【2】【4】【6】 => 12
//方式1:mapPartitions每个分区取最大值,然后求和
val rdd1: RDD[Int] = rdd.mapPartitions(iter => {
List(iter.max).iterator
})
val result = rdd1.reduce(_ + _)
// println(rdd1.sum()) //12.0
// println(result) //12
//方式2:glom将每个分区的作为一个Array
val rdd2: RDD[Array[Int]] = rdd.glom()
val rdd3: RDD[Int] = rdd2.map(_.max)
val result1 = rdd3.reduce(_ + _)
println(rdd3.collect().mkString(",")) //2,4,6
println(result1) //12
sc.stop()
}
}
⑥groupBy
- groupBy算子将根据传入的规则,将相同的key的数据会放置到一个组中。
object Oper08_groupBy {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
//分组-groupBy算子用于将用于将数据源中的每一条数据计算分组key
//相同的key的数据会放置到一个组中。
val rdd1: RDD[(Int, Iterable[Int])] = rdd.groupBy(data => data % 2)
// val rdd2: RDD[List[Int]] = rdd1.map {
// case (part, iter) => iter.toList
// }
//List(2, 4)
//List(1, 3)
rdd1.collect().foreach(println)
//(0,CompactBuffer(2, 4))
//(1,CompactBuffer(1, 3))
sc.stop()
}
}
- groupBy()内的第二个参数可以指定分区数,也就是说groupBy有shuffle操作。
object Oper08_groupBy_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
rdd.saveAsTextFile("output1") //结果有2个文件
val rdd2: RDD[(Int, Iterable[Int])] = rdd.groupBy(num => num % 2, 3)
rdd2.saveAsTextFile("output2") //结果有3个文件,内容格式为(1,CompactBuffer(1, 3))
sc.stop()
}
}
案例实操1:
object Oper08_groupBy_test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
// 小功能:将List("Hello", "hive", "hbase", "Hadoop")根据单词首写字母进行分组。
// 小功能:WordCount。
val rdd: RDD[String] = sc.makeRDD(List("Hello", "hive", "hbase", "Hadoop"))
val rdd1: RDD[(String, Iterable[String])] = rdd.groupBy(_.substring(0, 1))
val rdd2: RDD[((String, Int), List[String])] = rdd1.map {
case (word, iter) => ((word, iter.size), iter.toList)
}
rdd2.collect().foreach(println)
sc.stop()
}
}
案例实操2:
object Oper08_groupBy_test_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
//小功能:从服务器日志数据apache.log中获取每个时间段访问量
//1 获取每一行数据
val rdd: RDD[String] = sc.textFile("input/apache.log")
//2 提取每个时间段,转换格式为(时间段, 1)
val rdd2: RDD[(String, Int)] = rdd.map(line => {
val word = line.split(" ")
(word(3).substring(0, 13), 1)
})
//3 reduceByKey统计求和
val rdd3: RDD[(String, Int)] = rdd2.reduceByKey(_ + _)
rdd3.collect().foreach(println)
sc.stop()
}
}
⑦filter
- 暗中指定的规则对数据进行过滤,会根据返回的结果判断是否保留。true保留;false丢弃
object Oper09_filter {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
//TODO 过滤 - Filter
//按照指定的规则对数据进行过滤,会根据返回的结果判断是否保留
//true 保留;false 丢弃
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)
val rdd2: RDD[Int] = rdd.filter(num => num % 2 == 0)
rdd2.collect().foreach(println)
sc.stop()
}
}
案例实操
object Oper09_filter_test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
// 小功能:从服务器日志数据apache.log中获取2015年5月17日的请求路径
val rdd: RDD[String] = sc.textFile("input/apache.log")
val rdd1: RDD[String] = rdd.filter(line => {
val datas = line.split(" ")
datas(3).startsWith("17/05/2015")
})
val rdd2: RDD[String] = rdd1.map(line => {
val datas = line.split(" ")
datas(6)
})
rdd2.collect().foreach(println)
sc.stop()
}
}
⑧sample
- sample从数据源中抽取一部分数据,采样
- 第一个参数:表示抽取数据是否放回数据集中,true放回;false不放回
- 第二个参数:基于第一个参数判断
- 如果抽取放回的场合表示,期望抽取的次数
- 如果抽取不放回的场合,表示抽取数据集的概率(数据集中抽取每一个数据的概率)
- 第三个参数:表示抽取数据集的种子(随机数),如果不传递,就是当前的系统时间
object Oper10_sample {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1,2,3,4,5,6,7,8,9,10))
//TODO sample从数据源中抽取一部分数据,采样
// 第一个参数:表示抽取数据是否放回数据集中,true放回,false不放回
// 第二个参数:基于第一个参数来判断的
// 如果抽取放回的场合,表示期望抽取的次数
// 如果抽取不放回的场合,表示抽取数据的概率(数据集中抽取每一个数据的概率!)
// 第三个参数:表示抽取数据的种子(随机数),如果不传递,就是当前的系统时间
val rdd1 = rdd.sample(false, 0) //表示抽取每个数据的概率为0
val rdd2 = rdd.sample(false, 1) //表示抽取每个数据的概率为1
val rdd3 = rdd.sample(false, 0.5) //表示抽取每个数据的概率为0.5
val rdd4 = rdd.sample(false, 0.5, 1)
rdd1.collect().foreach(println)
println("============================")
println(rdd2.collect().mkString(", "))
println("============================")
println(rdd3.collect().mkString(", "))
println("============================")
println(rdd4.collect().mkString(", "))
sc.stop()
}
}
object Oper10_sample_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1,2,3,4,5,6,7,8,9,10))
//抽取放回,期望抽取2次 (泊松算法)
// 第一个参数:抽取的数据是否放回,true:放回;false:不放回
// 第二个参数:重复数据的几率,范围大于等于0.表示每一个元素被期望抽取到的次数
// 第三个参数:随机数种子
val rdd1 = rdd.sample(true, 1)
println(rdd1.collect().mkString(", "))
sc.stop()
}
}
⑨distinct
- distinct()去重
- distinct(n)可以在去重的时候更改分区数量。
object Oper11_distinct {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
//TODO distinct去重
val rdd = sc.makeRDD(List(1, 2, 3, 4, 4, 3, 1, 1), 2)
val rdd1 = rdd.distinct(3)
rdd1.saveAsTextFile("output")
// println(rdd1.collect().mkString(", "))
sc.stop()
}
}
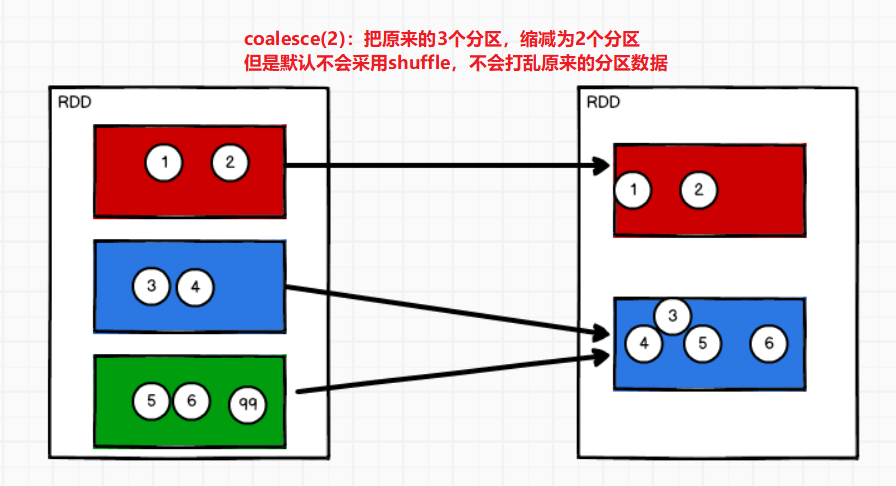
⑩coalesce
减少分区数,可视化为什么要减少分区呢?
存在这样的场景有两个文件有100条数据,但是经过filter过滤后每个task都仅剩1条数据,那么还要分配到2个Executor执行,传输的代价大于计算的代价。这样就不如把这两个分区减少为一个分区。
当spark程序中,存在过多的小文件,可以通过coalesce方法,收缩合并分区,减少分区的数量,减少任务调度成本
coalesce()算子的第一个参数为:重新分配为几个分区
第二个参数为:是否采用shuffle,是否打乱重新组合
object Oper12_coalesce {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 3)
//TODO coalesce减少分区
//用于将多个分区缩减分区,默认情况下不会将数据打乱重新组合,没有shuffle
//默认的合并规则是计算位置的关系
//如果想让合并分区后的数据更均衡一些的话,可以使用shuffle
val rdd1: RDD[Int] = rdd.coalesce(2)
rdd1.saveAsTextFile("output")
sc.stop()
}
}
如果coalesce用来扩大分区呢?
object Oper12_coalesce_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)
//TODO coalesce()
//coalesce算子的第一个参数表示缩减分区的数量,但是这个值可以比原分区大
//但是如果不适用shuffle情况下,不起作用
//使用shuffle的情况下,可以分配
val rdd1 = rdd.coalesce(3, true)
rdd1.saveAsTextFile("output")
sc.stop()
}
}
扩大分区后的数据是如何进入到其他分区的呢?
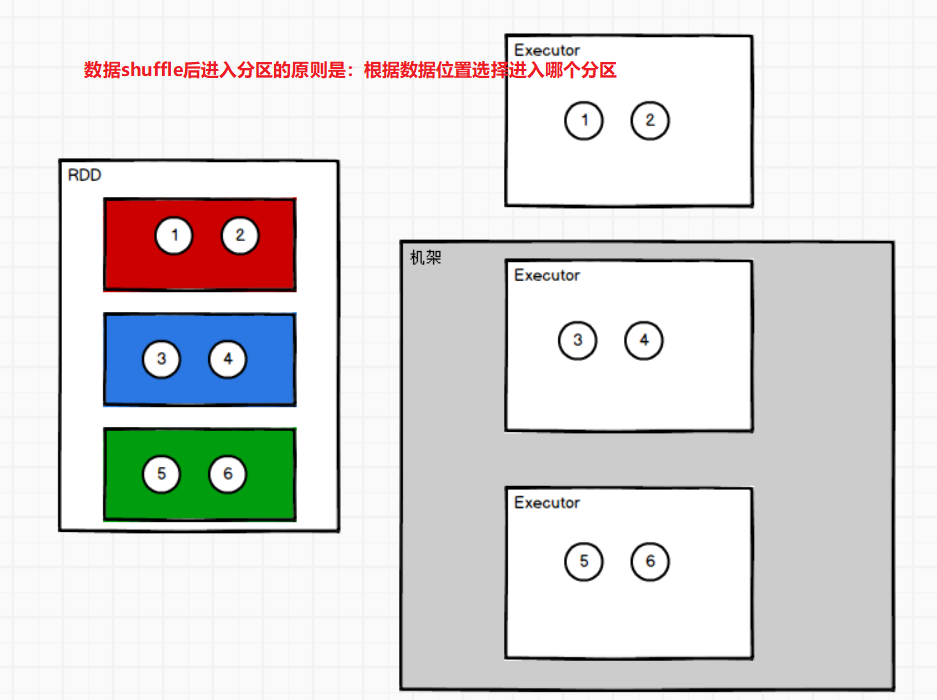
(11)repartition
扩大分区,repartition底层其实就是调用了coalesce(),不过是开始shuffle打乱数据。其源码如下:
- 无论分区数如何变化,都会采用shuffle过程。
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
object Oper13_repartition {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)
//TODO repartition扩大分区
val rdd1 = rdd.repartition(6)
rdd1.saveAsTextFile("output")
sc.stop()
}
}
(12)sortBy
sortBy():第一个参数是排序的规则;第二个参数,true升序(默认);false降序
每个分区间排序,中间存在shuffle过程
- 也能够触发执行操作~
object Oper14_sortBy {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1, 3, 2, 7, 4, 6), 2)
//TODO sortBy()
// 第一个参数是排序的规则
// 第二个参数:true升序(默认),false降序
//(每个分区内排序)中间存在shuffle过程
val rdd1 = rdd.sortBy(num => num, false)
rdd1.saveAsTextFile("output")
sc.stop()
}
}
(13)insertsection
(14)union
(15)subtract
object Oper15_intersection {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List(1, 2, 3, 4), 2)
val rdd2 = sc.makeRDD(List(3, 4, 5, 6), 2)
val rdd3 = rdd1.intersection(rdd2)
println("交集 = " + rdd3.collect().mkString(", "))
val rdd4 = rdd1.union(rdd2)
println("并集 = " + rdd4.collect().mkString(", ")) //并集因为是List,所以可以有重复数据
val rdd5 = rdd1.subtract(rdd2)
println("差集 = " + rdd5.collect().mkString(", "))
//交集,并集,差集操作时,需要两个RDD的数据类型保持一致
val rdd6 = sc.makeRDD(List("1", "2", "3", "4", "5"), 2)
//rdd1.intersection(rdd6) 错
//rdd1.union(rdd6) 错
//rdd1.subtract(rdd6) 错
sc.stop()
}
}
(16)zip
如果两个RDD的类型不一致:
类型不一致,但是分区数和元素数需要一样
如果两个RDD数据分区不一致:
会报错:Can’t zip RDDs with unequal numbers of partitions: List(3, 2)
如果两个RDD分区数据数量不一致:
会报错:SparkException : Can only zip RDDs with same number of elements in each partition
object Oper16_zip {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List(1, 2, 3, 4), 2)
val rdd2 = sc.makeRDD(List(3, 4, 5, 6), 2)
val rdd4 = sc.makeRDD(List("7", "8", "9", "10"), 2)
// SparkException : Can only zip RDDs with same number of elements in each partition
// Can't zip RDDs with unequal numbers of partitions: List(3, 2)
//spark RDD的zip操作要求分区数量保持一致,并且每个分区的元素数量保持一致
val rdd3 = rdd1.zip(rdd2)
println(rdd3.collect().mkString(", "))
//两个数据源的类型不相同,也可以拉链
val rdd5 = rdd1.zip(rdd4)
println(rdd5.collect().mkString(", "))
sc.stop()
}
}
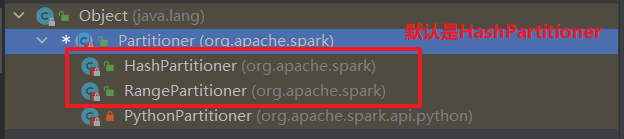
(17)partitionBy
partitionBy()需要传入指定的分区器partitioner,按照分区器的规则,把数据分到指定的分区。
repartition()是重新指定分区的数量。
partitionBy()是kv-类型RDD特有的方法,如果不是kv类型的RDD需要转成kv类型RDD才能使用partitionBy。
kv类型的操作方法全部来自于PairRDDFunctions,那么为什么RDD可以使用呢?
这是因为scala的隐式转换语法

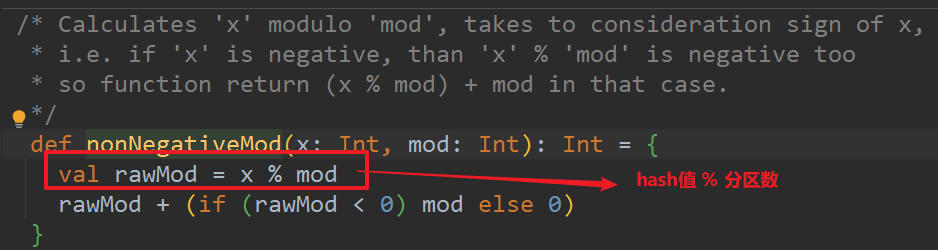
- 默认是HashPartitioner,根据hash值 % 分区数将数据分到指定分区。
object Oper17_partitionBy {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
//Spark的RDD处理的数据类型,如果为kv类型,需要进行特殊的转换才能调用特殊的功能
//非kv类型的RDD没有partitionBy方法,上面说的特殊转换,是将RDD转换成kv类型的RDD
val rdd1 = rdd.map((_, 1))
//所有的kv数据的操作方法全部都来自于PairRDDFunctions
//使用的scala中的隐式转换语法
val rdd2 = rdd1.partitionBy(new HashPartitioner(2))
val rdd3 = rdd1.partitionBy(new HashPartitioner(2))
rdd3.saveAsTextFile("output")
//TODO partitionBy方法根据指定的规则对数据进行重分区
//rdd.repartition()主要目的是改变分区的数量
//partitionBy需要传递一个分区器对象,改变数据所在的分区
//partitioner分区器对象有两个具体的分区器,HashPartitioner & RangePartitioner
//Spark中很多的RDD操作默认的分区器都是HashPartitioner
sc.stop()
}
}
reduceByKey有默认的分区器:因为reduceByKey有分组的操作。
new HashPartitioner(defaultNumPartitions)

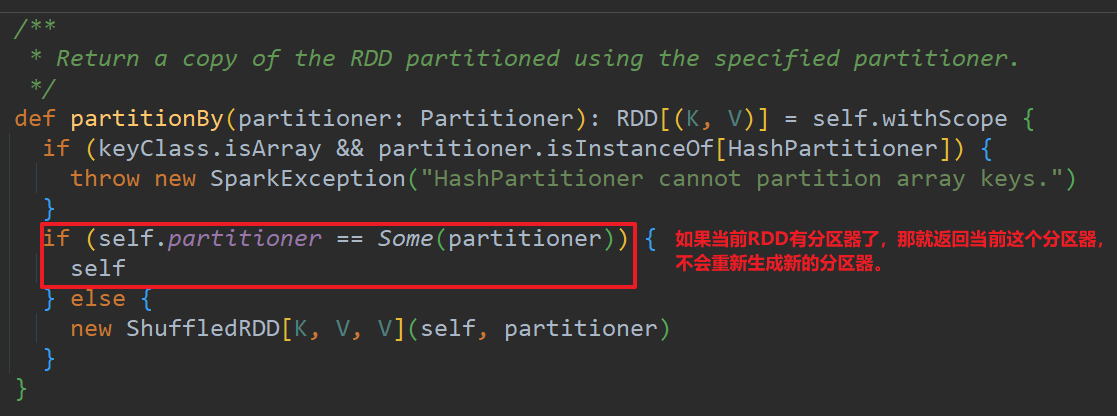
如果重分区的分区器和当前RDD的分区器一样怎么办?
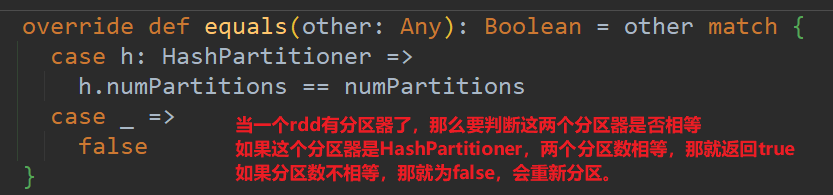
(18)reduceByKey
reduceByKey是将相同的key汇总到一起,对v进行聚合操作。
- 需要注意的是:reduceByKey在分区内预聚合核分区间聚合,数据处理的逻辑是相同的。
- 影响spark性能的主要有磁盘IO和数据大小:
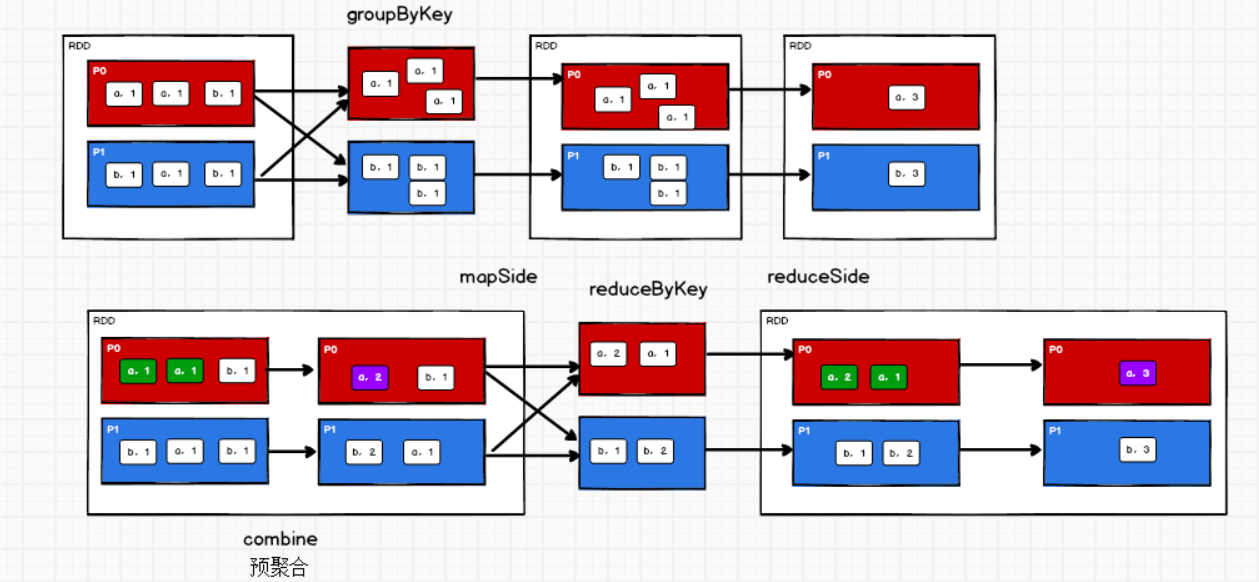
reduceByKey和groupByKey的区别?
- 从shuffle的角度:reduceByKey和groupByKey都存在shuffle过程,但是reduceByKey可以在shuffle前对分区数据进行预聚合combine功能,这样会减少罗盘的数据量;而groupByKey只是进行分组,不存在数据量减少的问题,reduceByKey性能比较高。
- 从功能的角度:reduceByKey其实包含分组和聚合的功能。groupByKey只能分组。
object Oper18_reduceByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(
List(
("a", 1), ("b", 1), ("a", 1), ("b", 1)
),2
)
//TODO reduceByKey将相同key的数据汇总到一起,对v进行聚合操作
//reduceByKey也能实现wordCount, 2/10
//reduceByKey在分区内预聚合和分区间聚合时,数据处理的逻辑是相同的
val rdd1 = rdd.reduceByKey(_ + _)
println(rdd1.collect().mkString(", "))
sc.stop()
}
}
(19)groupByKey
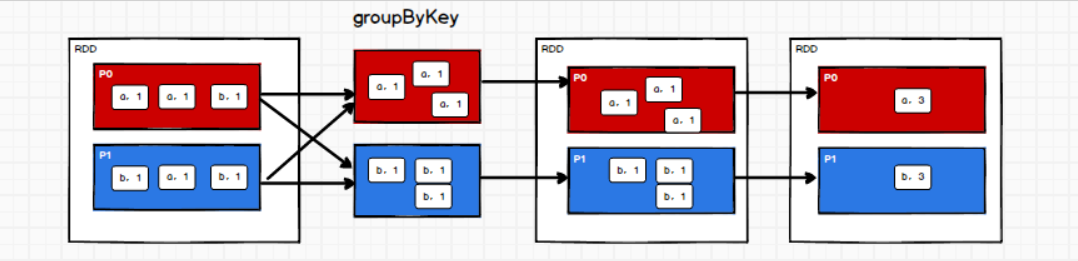
- 固定采用数据的key作为分组的key,分组后每一个kv数据的v会放在一个组中。(”a”,(1,1))
- groupByKey不会有预聚合,所以相比reduceByKey性能会差一点
object Oper18_reduceByKey_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(
List(
("a", 1), ("b", 1), ("a", 1), ("b", 1)
),2
)
//TODO groupBy & groupByKey
//groupBy可以根据数据来计算分区的key
// 分组后,每一个数据会放在一个组中(“a”,(“a”,1))
val rdd1: RDD[(String, Iterable[(String, Int)])] = rdd.groupBy(_._1)//(b,CompactBuffer((b,1), (b,1))), (a,CompactBuffer((a,1), (a,1)))
val rdd3: RDD[(String, Int)] = rdd1.map {
case (word, iter) => (word, iter.size)
} //(b,2), (a,2)
//groupByKey()固定采用key作为分组的key
// 分组后,每一个kv数据的v会放在一个组中(“a”,(1,1))
val rdd2: RDD[(String, Iterable[Int])] = rdd.groupByKey() //(b,CompactBuffer(1, 1)), (a,CompactBuffer(1, 1))
val rdd4: RDD[(String, Int)] = rdd2.mapValues(iter => iter.size)//(b,2), (a,2)
println(rdd4.collect().mkString(", "))
sc.stop()
}
}
(20)aggregateByKey
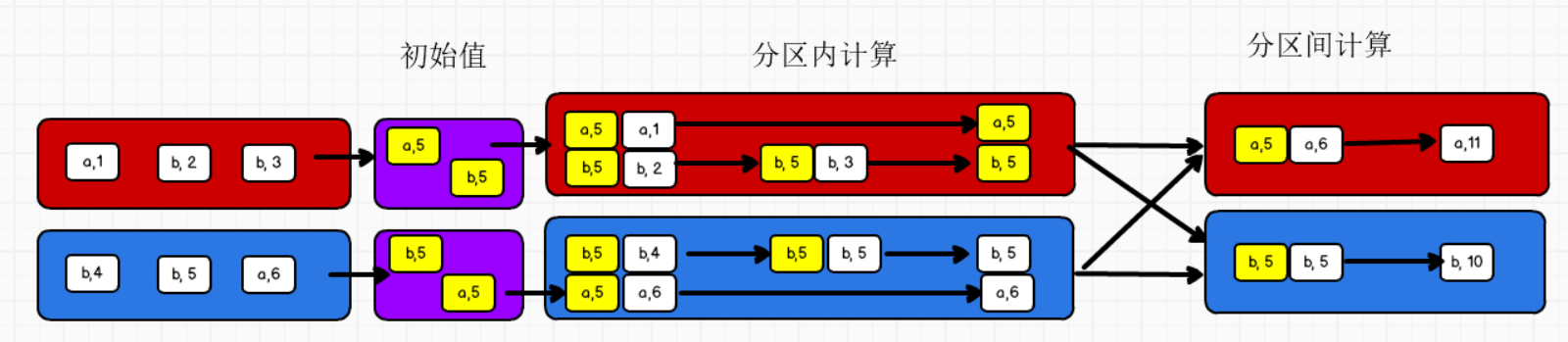
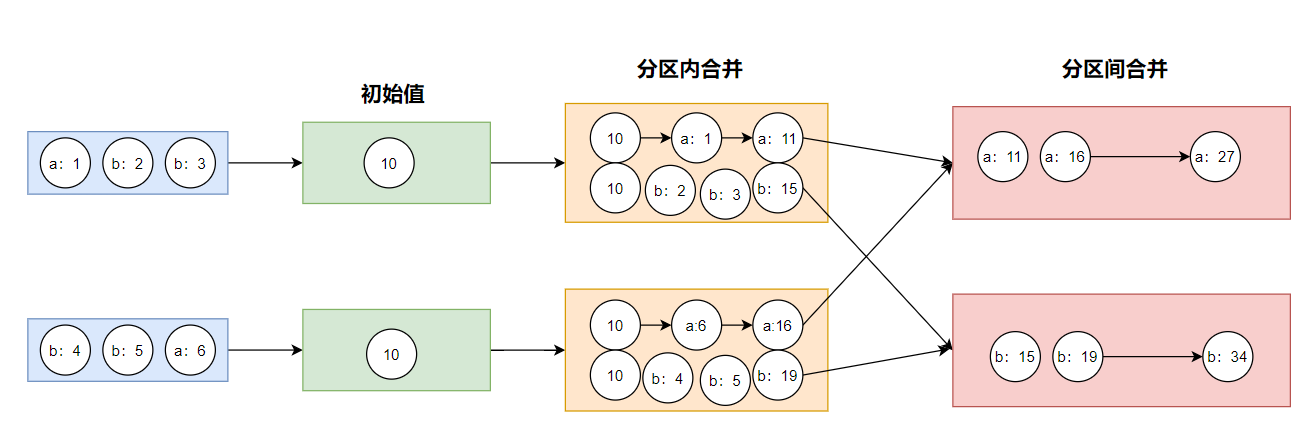
aggregateByKey()()有两个参数列表:
第一个参数列表:表示初始值
第二个参数列表:
- 第一个参数:表示分区内的计算规则
- 第二个参数:表示分区间的计算规则
object Oper19_aggregateByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
// TODO 取出每个分区内相同key的最大值然后分区间相加
val rdd = sc.makeRDD(
List(
("a", 1), ("b", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6),
),2
)
// 【("a", 1), ("b", 2), ("a", 3)】
// 【("b", 4), ("b", 5), ("a", 6)】
// =>
// 【("b", 2), ("a", 3)】
// 【("b", 5), ("a", 6)】
// =>
// 【("a", 6), ("a", 3)】 => 【(a, 9)】
// 【("b", 5), ("b", 2)】 => 【(b, 7)】
//aggregateByKey有2个参数列表
//第一个参数列表有一个参数,表示计算的初始值
// 用于分区内相同key的第一个value的计算
//第二个参数列表有两个参数
// 第一个参数表示分区内计算功能(函数)
// 第二个参数表示分区间计算功能(函数)
val rdd1: RDD[(String, Int)] = rdd.aggregateByKey(0)(
(x: Int, y: Int) => {
math.max(x, y)
},
(a: Int, b: Int) => {
a + b
}
)
println(rdd1.collect().mkString(","))
sc.stop()
}
}
(21)foldByKey
foldByKey()()其实就是aggregateByKey()()的分区内和分区间的计算规则相同。
foldByKey()()有两个参数列表:
- 第一个参数列表:初始值
- 第二个参数列表:分区内和分区间相同的计算规则
object Oper20_foldByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(
List(
("a", 1), ("b", 2), ("b", 3),
("b", 4), ("b", 5), ("a", 6),
),2
)
//aggregateByKey算子的第二个参数列表的两个参数可以一致:表示分区内和分区间的计算规则一样
val rdd1: RDD[(String, Int)] = rdd.aggregateByKey(0)(_ + _, _ + _)
//TODO aggregateByKey算子的分区内和分区间的计算规则一样的话,可以简化为:foldByKey()
val rdd2: RDD[(String, Int)] = rdd.foldByKey(0)(_ + _)
println(rdd2.collect().mkString(", "))
sc.stop()
}
}
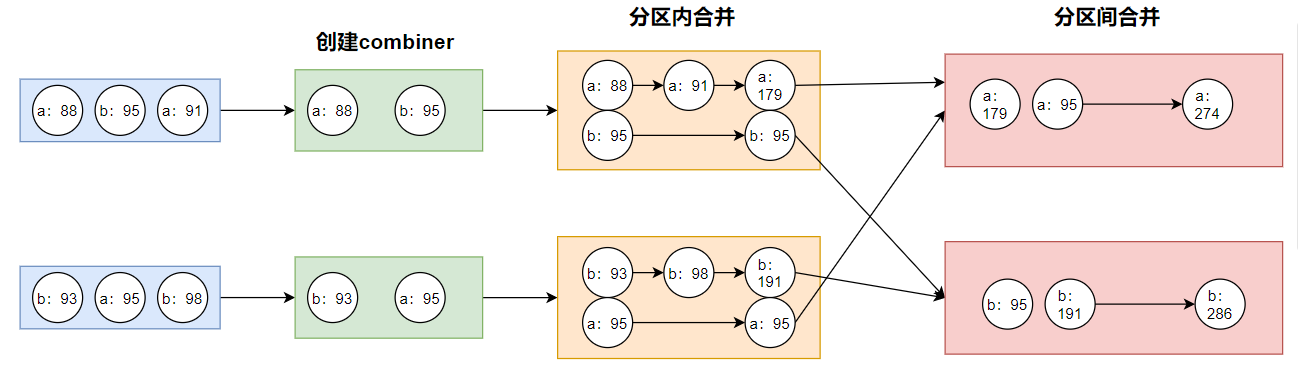
(22)combineByKey
combineByKey()算子有三个参数:
注意!!!combineByKey是不考虑key的所以,三个参数都是针对v进行的操作
- 第一个参数:表示将相同key的第一个value进行转换;目的是创建combiner,用来和同分区的v进行计算
- 第二个参数:表示分区内计算规则
- 第三个参数:表示分区间计算规则
案例1:用combineByKey求wordCount的图解
object Oper21_combineByKey_2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
//创建rdd
val rdd: RDD[(String, Int)] = sc.makeRDD(
List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98))
, 2
)
//使用combineByKey计算word count
val rdd1: RDD[(String, Int)] = rdd.combineByKey(
//参数1,创建combiner,用来和同分区的数据计算
num => num,
//参数2,分区内两个v的计算规则
(num1: Int, num2: Int) => num1 + num2,
//参数3,分区间两个v的计算规则
(cNum1: Int, cNum2: Int) => cNum1 + cNum2
)
println(rdd1.collect().mkString(", "))
sc.stop()
}
}
案例2:用combineByKey计算word count的平均数

object Oper21_combineByKey_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(
List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)),
2
)
//使用combineByKey
val rdd1: RDD[(String, (Int, Int))] = rdd.combineByKey(
//参数1:创建combiner,更改v的结构(v,1)
(num: Int) => (num, 1),
//参数2:分区内v的计算规则
(com: (Int, Int), v: Int) => (com._1 + v, com._2 + 1),
//参数3:分区间v的计算规则
(newV1: (Int, Int), newV2: (Int, Int)) => (newV1._1 + newV2._1, newV1._2 + newV2._2)
)
//每个字母的平均数为:
val rdd2: RDD[(String, Int)] = rdd1.map {
case (word, (total, count)) => (word, total / count)
}
println(rdd2.collect().mkString(", ")) //(b,95), (a,91)
sc.stop()
}
}
(23)sortByKey
- sortByKey()根据kv数据的key进行排序,和value无关
- sortBy()根据指定的规则进行排序
sortBy(_. _1)其实也就是sortByKey()
sortByKey()括号内可以填写true,表示升序(默认);false降序
sortByKey如果key为一个对象的话,那么这个对象所在的类必须实现Ordered接口(特质)
object Oper22_sortByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(
List(
("b", 5),("a",1),("b", 2),("a", 4),("a", 3)
)
)
//TODO sortByKey根据数据的key进行排序,和value无关
val rdd1: RDD[(String, Int)] = rdd.sortByKey()
println(rdd1.collect().mkString(", ")) //(a,1), (a,4), (a,3), (b,5), (b,2)
//TODO sortBy根据指定的规则进行排序
// val rdd1: RDD[(String, Int)] = rdd.sortBy(_._1)
// println(rdd1.collect().mkString(", ")) //(a,1), (a,4), (a,3), (b,5), (b,2)
sc.stop()
}
}
sortByKey的key为一个对象:
object Spark20_Oper_KV_1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
val sc : SparkContext = new SparkContext(sparkConf)
val rdd = sc.makeRDD(
List(
(new User(), 5),(new User(),1),(new User(), 2),(new User(), 4),(new User(), 3)
)
)
val rdd1 = rdd.sortByKey(true)
rdd1.collect().foreach(println)
sc.stop()
}
class User extends Ordered[User]{
override def compare(that: User): Int = {
0
}
}
}
(24)join
join 用于链接两个RDD,连接的条件是相同的key
- 如果一个rdd中有另一个rdd中没有的key,那么这个key就不会连接。
- join会产生笛卡尔积,也就是说一个key,在另一个rdd中如果有多个对应的值,那么会连接多次。
- join输出结果的格式为:(key,(rdd1的value,rdd2的value))
object Oper23_join {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
//TODO join
//join 方法表示用于链接两个数据源,链接条件为相同的key
//如果两个数据源中相同key,那么会将两个v连接在一起
//但是如果一个数据源中有key,另外一个没有,那么无法连接
val rdd1 = sc.makeRDD(
List(
("a", 1), ("b", 2),("c", 3)
)
)
val rdd2 = sc.makeRDD(
List(
("b", 4),("a", 3),("b", 5)
)
)
//join会产生笛卡尔积
val rdd3: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
rdd3.collect().foreach(println)
//(a,(1,3))
//(b,(2,4))
//(b,(2,5))
sc.stop()
}
}
(25)left|rightOuterJoin
leftOuterJoin()左外连接,左边的为主表。有可能会丢失右边表的数据。
rightOuterJoin()右外连接,右边的为主表。有可能会丢失左边表的数据。
OuterJoin的结果输出格式为
- 左外连接:(key,(左rdd的value,Some( 右rdd的value ))) 如果没有值那么为None
- 右外连接:(key,(Some(左rdd的value),右rdd的value))
object Oper24_leftOuterJoin {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(
List(
("a", 1), ("b", 2),("c", 3)
)
)
val rdd2 = sc.makeRDD(
List(
("b", 4),("a", 3),("b", 5)
)
)
val rdd3 = rdd1.leftOuterJoin(rdd2)
val rdd4 = rdd1.rightOuterJoin(rdd2)
rdd3.collect().foreach(println)
println("========================")
rdd4.collect().foreach(println)
//(a,(1,Some(3)))
//(b,(2,Some(4)))
//(b,(2,Some(5)))
//(c,(3,None))
//========================
//(a,(Some(1),3))
//(b,(Some(2),4))
//(b,(Some(2),5))
sc.stop()
}
}
(26)cogroup
每个数据源进行groupByKey,多个数据源进行connect;
object Oper25_cogroup {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(
List(
("a", 1), ("b", 2),("c", 3)
)
)
val rdd2 = sc.makeRDD(
List(
("b", 4),("a", 3),("d", 5)
)
)
val rdd3 = rdd1.cogroup(rdd2)
rdd3.collect().foreach(println)
//(a,(CompactBuffer(1),CompactBuffer(3)))
//(b,(CompactBuffer(2),CompactBuffer(4)))
//(c,(CompactBuffer(3),CompactBuffer()))
//(d,(CompactBuffer(),CompactBuffer(5)))
sc.stop()
}
}
总结
1 几个 xxxByKey 算子的区别:
- groupByKey()根据key值进行分组,相同的key会被分到同一个组中。
- reduceByKey(),= 分组+聚合。也会根据相同key进行分组,分组后会对相同key的value进行聚合。并且在shuffle落盘之前,有combine预聚合操作。
- aggregateByKey()(),函数柯里化有两个参数列表,第一个参数列表是一个初始值,第二个参数列表的第一个参数是分区内的计算规则,第二个参数是分区间的计算规则。
- foldByKey()(),就是aggregateByKey()()当分区内和分区间的计算规则相同的情况。
- combineByKey(),有三个参数,第一个参数是创建的combiner,相当于前面的初始值,用来和分区内的value进行计算,第二个参数是分区内的计算规则,第三个参数是分区间的计算规则。
reduceByKey
=> combineByKeyWithClassTag[V](
(v: V) => v, // 用于转换相同key的第一个值
func, // 分区内计算规则 _ + _
func) // 分区间计算规则 _ + _
aggregateByKey
=> combineByKeyWithClassTag[U](
(v: V) => cleanedSeqOp(createZero(), v), // 用于转换相同key的第一个值
cleanedSeqOp, // 分区内计算规则
combOp) // 分区间计算规则
foldByKey
=> combineByKeyWithClassTag[V](
(v: V) => cleanedFunc(createZero(), v), // 用于转换相同key的第一个值
cleanedFunc, // 分区内计算规则
cleanedFunc) // 分区间计算规则
combineByKey
=> combineByKeyWithClassTag(
createCombiner, // 用于转换相同key的第一个值
mergeValue, // 分区内计算规则
mergeCombiners) // 分区间计算规则
5.5 RDD行动算子
行动算子:不会产生新的RDD,而是触发作业的执行。
行动算子执行时,会产生job对象,然后提交对象。
执行算子每一次调用都会创建一个job对象。
//1 有向无环图调度器
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
//2 提交job
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
//3 处理job提交
private[scheduler] def handleJobSubmitted()
//4 创建job
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
(1)reduce
reduce()是一个行动算子,可以创建job对象,可以直接执行。
object Action02_reduce {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("myApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 1, 2, 1, 1))
//reduceByKey()因为是转换算子,不是执行算子,当没有collect触发执行的时候,不会执行。
val rdd1: RDD[(Int, Int)] = rdd.map((_, 1)).reduceByKey(_ + _)
//reduce是一个执行算子,可以直接执行。
val i = rdd.reduce(_ + _)
println(i)
sc.stop()
}
}
(2)collect
collect采集数据,会将Executor执行的结果汇总到Driver的内存中,内存可能会溢出,所以需要谨慎使用
collect方法可以触发作业(计算)的执行,因为在运行时会创建job对象。
算子每一次调用都会创建一个作业job
以数组的形式返回所有数据
object Action03_collect {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("myApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 1, 2, 1, 1))
//TODO collect 采集数据
//会将Executor执行的结果汇集到Driver的内存中,内存可能会溢出,所以需要谨慎使用。
val array: Array[Int] = rdd.collect()
println(java.util.Arrays.toString(array))
sc.stop()
}
}
(3)count
返回RDD中数据的个数
object Action04_count {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("myApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 1, 2, 1, 1))
//TODO count 返回RDD中数据的个数
val i = rdd.count()
println(i) //8
sc.stop()
}
}
(4)first
返回RDD中的第一个元素
object Action05_first {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("myApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 1, 2, 1, 1))
//TODO first 返回RDD中的第一个元素
val i = rdd.first()
println(i) //8
sc.stop()
}
}
(5)take
返回RDD的前n个元素组成的数组
object Action06_take {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("myApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 1, 2, 1, 1))
//TODO take 返回RDD前n个元素组成的数组
val array: Array[Int] = rdd.take(3)
println(java.util.Arrays.toString(array)) //[1, 2, 3]
sc.stop()
}
}
(6)takeOrdered
对RDD先排序,从排好序的RDD中取前n个
object Action06_takeOrdered {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("myApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 1, 2, 1, 1))
//TODO takeOrdered 从排好序的RDD中取前三个
val array = rdd.takeOrdered(3)
println(array.mkString(", "))
sc.stop()
}
}
(7)aggregate
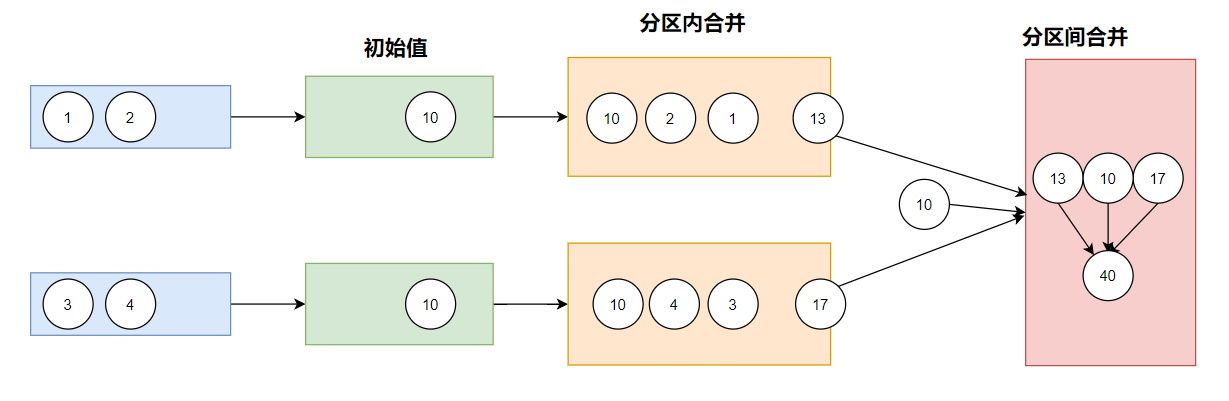
aggregate() 对RDD中的每一个元素,以参数1(初始值),以分区为单位
- 分区内按照第二个参数列表的第一个参数计算。
- 分区间按照第二个参数列表的第二个参数计算。
!!! 需要注意的是:aggregate初始值对分区内和分区间都需要计算。
aggregateByKey()根据key值,以分区为单位按照初始值,进行分区内;计算的结果在分区间计算。
object Action07_aggregate {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("myApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
//TODO aggregate 对RDD中的每一个元素以初始值为基础,
// 分区内按第二个参数列表的参数1计算
// 分区间按第二个参数列表的参数2计算。
//aggregate算子的初始值 分区内和分区间都会聚合计算
//而aggregateByKey算子的初始值,仅仅在分区内会聚合计算
val i = rdd.aggregate(10)(_ + _, _ + _)
//10+1+2 = 13
//10+3+4 = 17
//10 + 13 + 17 = 40
println(i) //40
sc.stop()
}
}
(8)fold
fold是对aggregate的简化,当aggregate的分区内操作和分区间操作一样的时候可以使用fold。
object Action08_fold {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("myApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
//TODO fold是对aggregate操作的简化
val i = rdd.aggregate(10)(_ + _, _ + _)
val j = rdd.fold(10)(_ + _)
println(i)
println(j)
sc.stop()
}
}
(9)countByValue|countByKey
- countByValue()可以对与非k-v类型的数据,统计每个value的值的数量
返回值类型为collection.Map[Int, Long];其中map中的第一个数为RDD中的非k-v类型的值,第二个数表示该值出现的次数。Map(4 -> 1, 2 -> 1, 1 -> 1, 3 -> 1)
- countByKey()对k-v类型的数据,根据key取统计value的值的数量
返回值类型为collection.Map[String, Long];其中map中的第一个数为RDD中key值;第二个数表示key出现的次数。Map(4 -> 1, 2 -> 1, 3 -> 1, 1 -> 1)
-- 这里的scala.collection.Map是一个特质,并不是我们一直用的scala.mutable.Map或者scala.immutable.Map
object Action09_countByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("myApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
//TODO countByValue
val intToLong = rdd.countByValue()
println(intToLong) //Map(4 -> 1, 2 -> 1, 1 -> 1, 3 -> 1)
//TODO countByKey
val stringToLong = rdd.map(num => (num.toString, num)).countByKey()
println(stringToLong) //Map(4 -> 1, 2 -> 1, 3 -> 1, 1 -> 1)
sc.stop()
}
}
小案例:wordCount
flatMap扁平化操作
object Action09_countByKey_1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("myApp")
val sc = new SparkContext(conf)
//TODO 扁平化
val rdd = sc.makeRDD(
List(
("Hello", 4), ("Spark", 3), ("Hello", 5)
)
)
//TODO 方式1
// val rdd1: RDD[(String, Int)] = rdd.flatMap {
// case (word, count) => {
// val s = (word + " ") * count
// s.split(" ").map((_, 1))
// }
// }
//TODO 方式2
val rdd1: RDD[String] = rdd.flatMap {
case (word, count) => {
Array.fill[String](count)(word)
}
}
val stringToLong = rdd1.countByValue()
//word count
// val stringToLong = rdd1.countByKey()
stringToLong.foreach(println)
sc.stop()
}
}
(10)save
saveAsTextFile():将RDD并保存成TextFile文件
saveAsObjectFile:将RDD序列化成对象保存到ObjectFile文件
saveAsSequenceFile:数据必须是k-v类型才能保存到到SequenceFile文件
object Action10_save {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("myApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)
//TODO saveAsFile:输出为Text文件
rdd.saveAsTextFile("output")
//TODO saveAsObjectFile:序列化成对象保存到文件
rdd.saveAsObjectFile("output1")
//TODO saveAsSequenceFile:保存成SequenceFile文件;数据要求是k-v类型的数据才能保存
rdd.map((_,1)).saveAsSequenceFile("output2")
sc.stop()
}
}
(11)foreach
RDD的所有算子都是分布式操作。
foreach其实是scala集合的操作,是单机操作,所以是顺序循环。
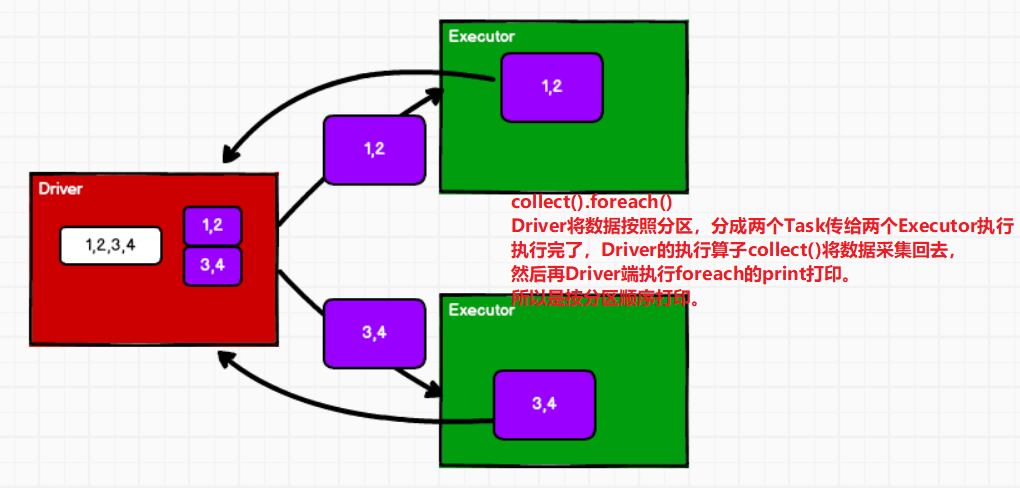
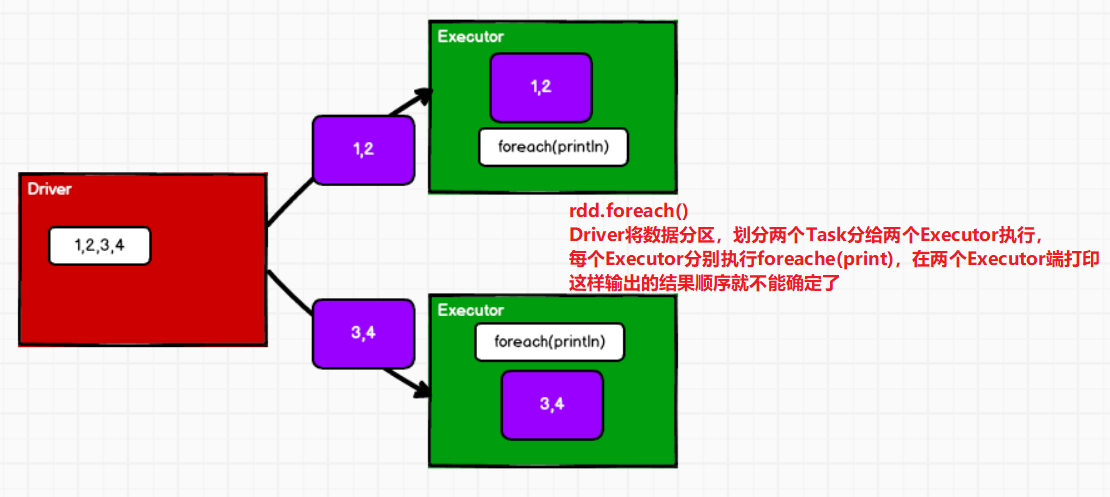
- rdd.foreach():在多个Executor端执行顺序打印,但是多个Executor哪个先打印不能确定。
- collect().foreach():Driver采集多个Executor端的数据,采集到Driver端执行foreach操作,所以采集完按照分区顺序打印。
object Action11_foreach {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("myApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)
//TODO foreach
// collect是按照分区的顺序采集数据的方法
// foreach方法其实是scala集合的方法,是单机操作,所以是按照顺序循环
rdd.collect().foreach(println) //1 2 3 4 5 6
println("**********************************")
//rdd的所有算子其实都是分布式操作
//所以这里的foreach操作其实它是分布式循环打印
//算子内部的逻辑全是在Executor端执行
//算子外部的逻辑全是在Driver端执行
rdd.foreach(println) //1 4 2 5 3 6
sc.stop()
}
}
(12)mapValues
mapValues:对value的数据结构进行转换。仅仅是对k-v类型的数据进行处理。
object Action12_mapValues {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("myApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)
//TODO mapValues,对k-v类型的数据,仅仅对v进行处理,k不变。对value的数据结构进行转换
val value: RDD[(Int, Int)] = rdd.map((_, 1)).mapValues(_ + 1)
value.collect().foreach(println)
sc.stop()
}
}
5.6 RDD序列化
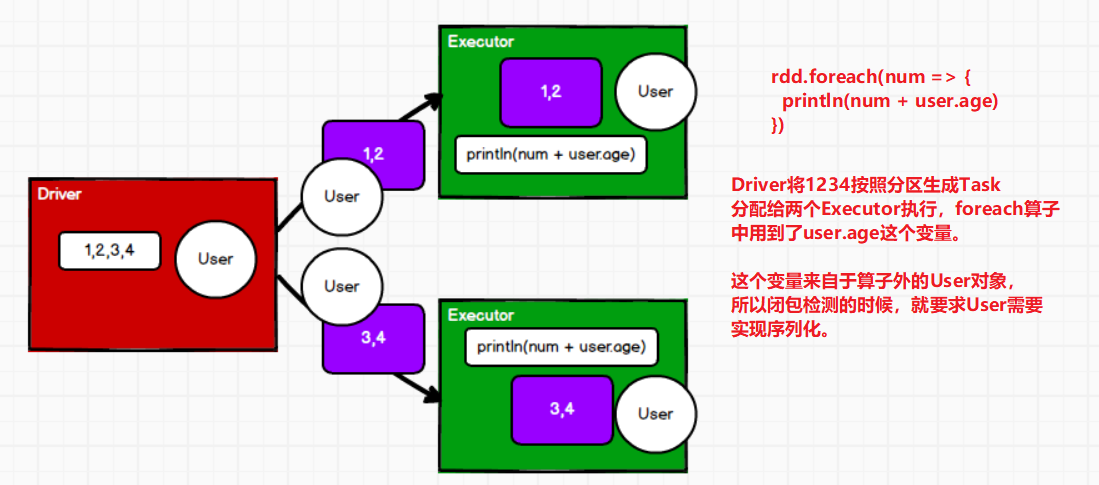
如果算子中使用了算子以外的对象,那么在执行时,需要保证这个对象能序列化。
为什么在算子中能够使用String、Int等算子外变量,这是因为它们都实现了序列化。
样例类自动混入了可序列化特质。
Spark算子都是分布式操作,所以算子在执行前都需要进行闭包检测操作,用来判断闭包操作中的外部变量对象,是否可序列化。
object Spark01_Serial {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val user = new User()
//SparkException: Task not serializable
//分布式执行时,需要考虑传输数据的序列化问题
//分布式执行计算前,需要进行闭包检测操作,用于判断闭包操作中数据是否能够序列化
//如果数据不能序列化,不需要执行作业就会发生错误。
rdd.foreach(num => {
println(num + user.age)
})
sc.stop()
}
class User extends Serializable {
val age : Int = 30
}
//case class User(val age: Int = 30)
}
Kryo序列化框架
java的序列化框架能够序列化任何的类,但是字节比较重,序列化后对象的提交比较大。Spark2.0开始支持Kryo序列化机制,Kryo速度是Serializable的10倍。“当RDD在Shuffle数据的时候,简单数据类型、数组和字符串类型已经在Spark内部使用Kryo来序列化”。
"注意:即使使用Kryo序列化,也要继承Serializable接口。
5.7 RDD的依赖关系
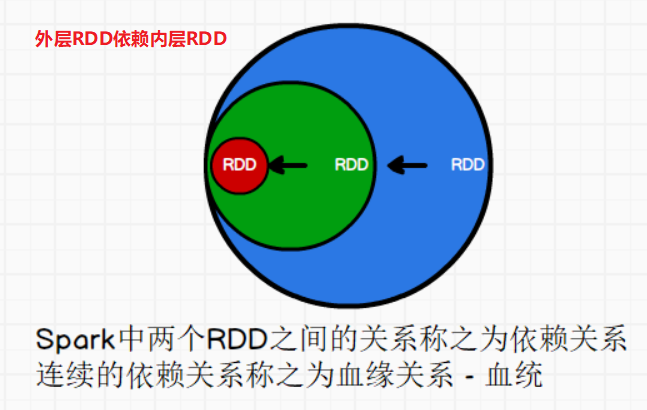
①RDD血缘关系
toDebugString()获取当前RDD的血缘关系
object Spark01_Dep {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
//1 创建RDD
val rdd = sc.makeRDD(List("Hello Spark Hive Hello"))
println(rdd.toDebugString) //血缘
println("******************************")
//2 扁平化操作
val rdd1: RDD[String] = rdd.flatMap(_.split(" "))
println(rdd1.toDebugString)
println("*******************************")
//3 结构化处理(word,1)
val rdd2 = rdd1.map((_, 1))
println(rdd2.toDebugString)
println("********************************")
//4 根据key值聚合
val rdd3 = rdd2.reduceByKey(_ + _)
println(rdd3.toDebugString)
println("********************************")
rdd3.collect().foreach(println)
sc.stop()
}
}
(16) ParallelCollectionRDD[0] at makeRDD at Spark01_Dep.scala:14 []
******************************
(16) MapPartitionsRDD[1] at flatMap at Spark01_Dep.scala:19 []
| ParallelCollectionRDD[0] at makeRDD at Spark01_Dep.scala:14 []
*******************************
(16) MapPartitionsRDD[2] at map at Spark01_Dep.scala:24 []
| MapPartitionsRDD[1] at flatMap at Spark01_Dep.scala:19 []
| ParallelCollectionRDD[0] at makeRDD at Spark01_Dep.scala:14 []
********************************
(16) ShuffledRDD[3] at reduceByKey at Spark01_Dep.scala:29 []
+-(16) MapPartitionsRDD[2] at map at Spark01_Dep.scala:24 []
| MapPartitionsRDD[1] at flatMap at Spark01_Dep.scala:19 []
| ParallelCollectionRDD[0] at makeRDD at Spark01_Dep.scala:14 []
********************************
(Hive,1)
(Hello,2)
(Spark,1)
//这里的(16)表示分区的意思,因为设置了local[*],如果是local那么就是(1)个分区。
为什么要记录RDD的血缘关系呢?
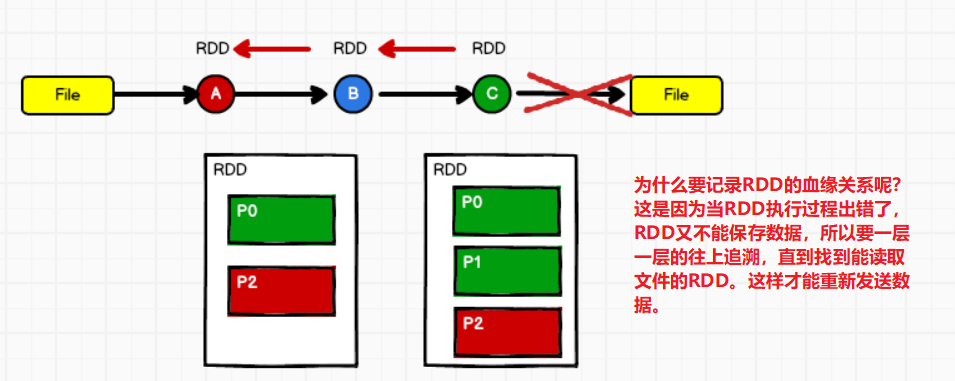
那么如果下由的RDD-P0和P1分区成功了,但是P2分区可能因为某些网络原因失败了呢?
其实RDD的血缘关系是分区与分区间的依赖关系。
②RDD依赖关系
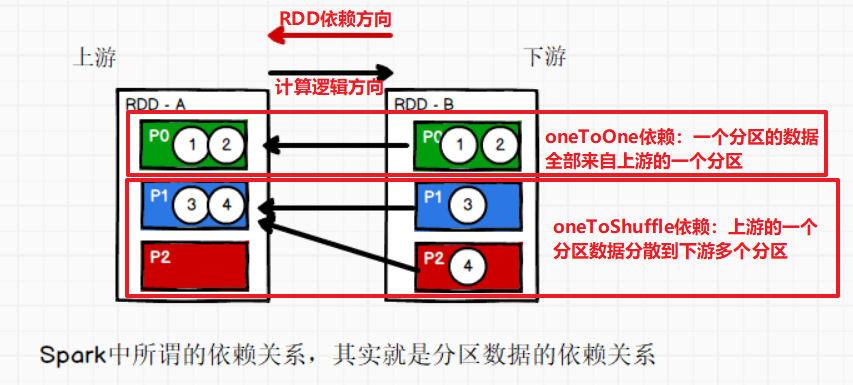
rdd.dependencies:用来查看RDD的依赖关系
依赖关系有两种:
- 一种是:OneToOne依赖,一个上游分区的数据全部到一个下游分区
- 一种是:Shuffle依赖,一个上游分区的数据分散到多个下游分区
object Spark01_Dep_2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
//1 创建RDD
val rdd: RDD[String] = sc.textFile("input/word.txt")
println(rdd.dependencies)
println("****************************")
//2 扁平化操作
val rdd1: RDD[String] = rdd.flatMap(_.split(" "))
println(rdd1.dependencies)
println("****************************")
//3 结构转换
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
println(rdd2.dependencies)
println("****************************")
//4 根据key聚合
val rdd3: RDD[(String, Int)] = rdd2.reduceByKey(_ + _)
println(rdd3.dependencies)
println("****************************")
rdd3.collect().foreach(println)
sc.stop()
}
}
List(org.apache.spark.OneToOneDependency@6b1dc20f)
****************************
List(org.apache.spark.OneToOneDependency@443effcb)
****************************
List(org.apache.spark.OneToOneDependency@97d0c06)
****************************
List(org.apache.spark.ShuffleDependency@3ddeaa5f)
****************************
(scala,1)
(hive,1)
(spark,4)
(hadoop,2)
(hbase,1)
// OneToOneDependency
③RDD窄依赖
窄依赖:上游的RDD的Partition全部被下游RDD的一个Partition使用。
其实就是oneToOneDependency
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd)
④RDD宽依赖
宽依赖:表示同一个上游RDD的Partition被多个下游RDD的Partition依赖。
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]]
5.8 阶段划分
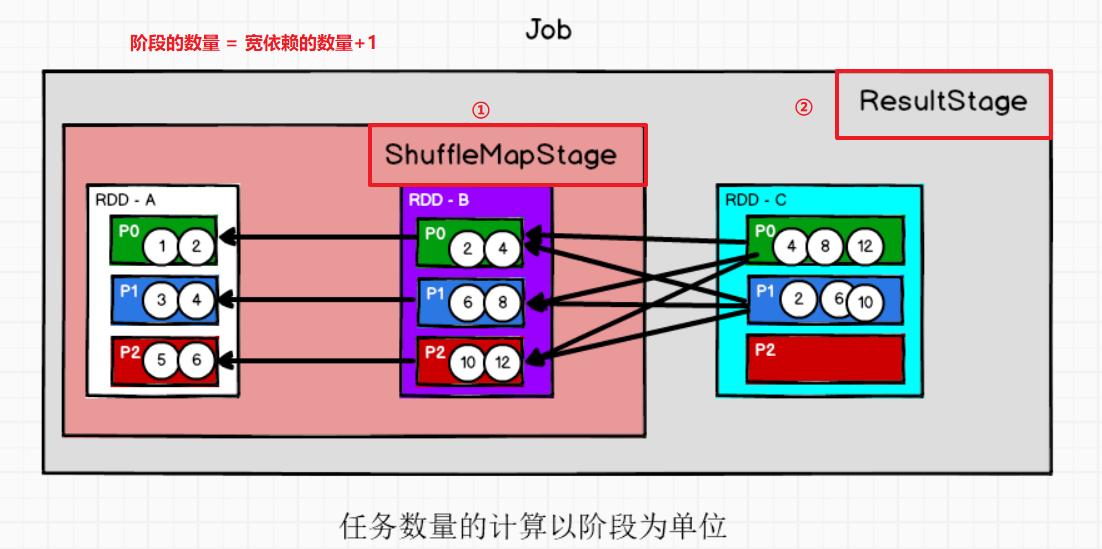
- 如果Spark计算过程中存在落盘的操作,那么就应该划分阶段。
- 如果执行过程中没有落盘的操作,那么就应该是一个完整的阶段。
- 如果执行过程有shuffle那么就一定会有落盘,那么stage就会加1
spark中阶段的数量取决于shuffle依赖的个数:阶段数 = shuffle依赖数 + 1
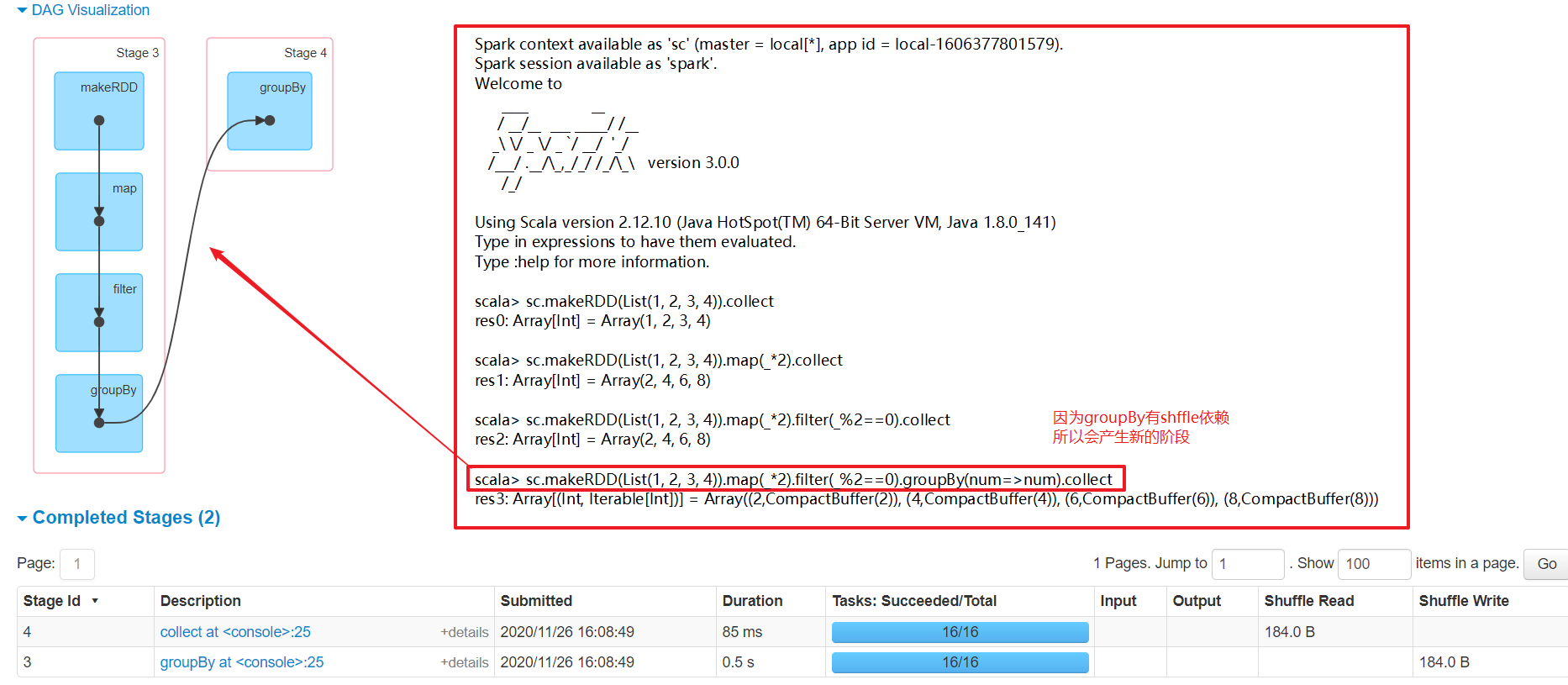
5.9 任务划分
-- Application:初始化一个SparkContext,即生成一个Application
new SparkConf().setMaster("local[*]").setAppName("MyApp")
-- Job:一个Action算子就会生成一个Job
-- Stage:Stage等于宽依赖(ShuffleDependency)的个数加1
-- Task:一个Stage阶段中,最后一个RDD的分区个数就是Task的个数
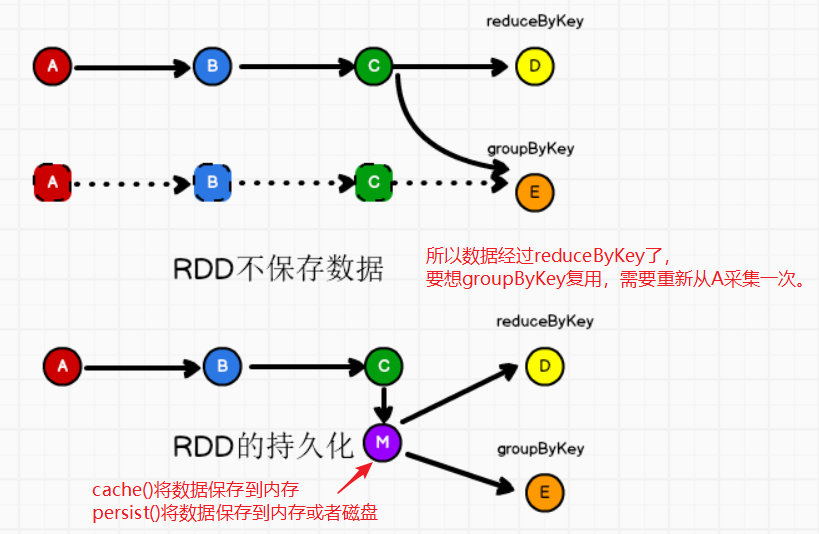
5.10 RDD的持久化
①RDD持久化
持久化 – 缓存:cache(),只能将数据保存到内存中
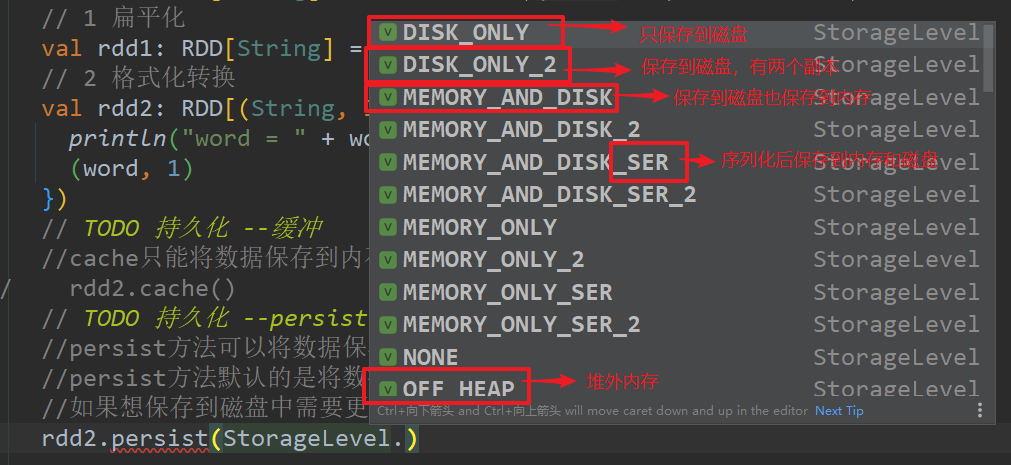
持久化 --persist(),既可以将数据保存到内存,也可以保存到磁盘
persist()方法默认是将数据保存到内存中StorageLevel.MEMORY_ONLY
如果想保存到磁盘中,需要更改存储级别。
cache缓存和persist持久化都是以app为单位,当app执行完毕后,落盘或内存中的数据会删除。
缓存的目的:多个rdd重复使用前面的数据的时候。
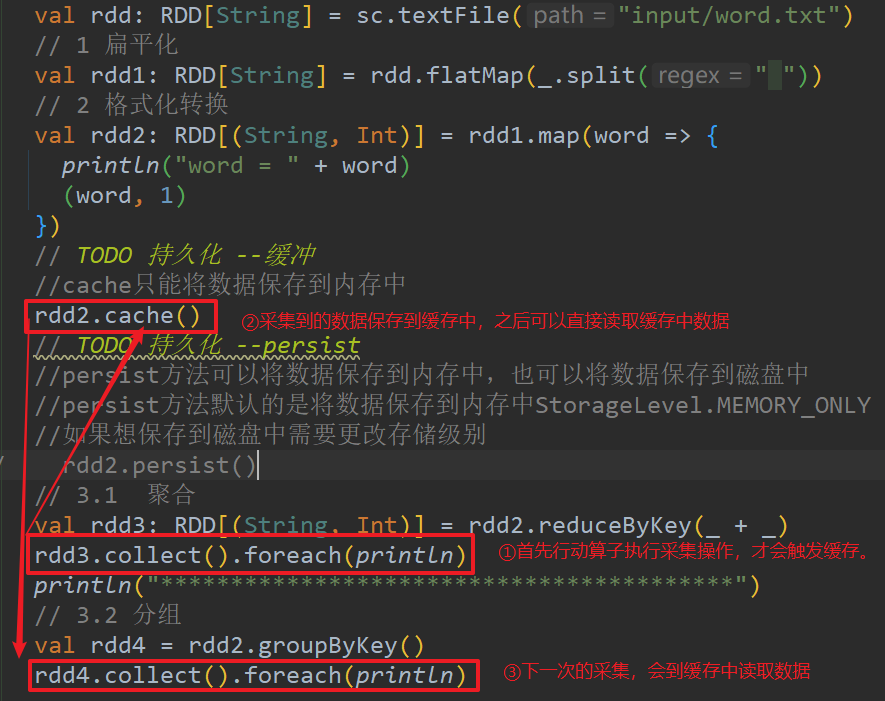
object Spark01_Persist {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.textFile("input/word.txt")
// 1 扁平化
val rdd1: RDD[String] = rdd.flatMap(_.split(" "))
// 2 格式化转换
val rdd2: RDD[(String, Int)] = rdd1.map(word => {
println("word = " + word)
(word, 1)
})
// TODO 持久化 --缓存
//cache只能将数据保存到内存中
rdd2.cache()
// TODO 持久化 --persist
//persist方法可以将数据保存到内存中,也可以将数据保存到磁盘中
//persist方法默认的是将数据保存到内存中StorageLevel.MEMORY_ONLY
//如果想保存到磁盘中需要更改存储级别
rdd2.persist()
// 3.1 聚合
val rdd3: RDD[(String, Int)] = rdd2.reduceByKey(_ + _)
rdd3.collect().foreach(println)
println("*****************************************")
// 3.2 分组
val rdd4 = rdd2.groupByKey()
rdd4.collect().foreach(println)
}
}
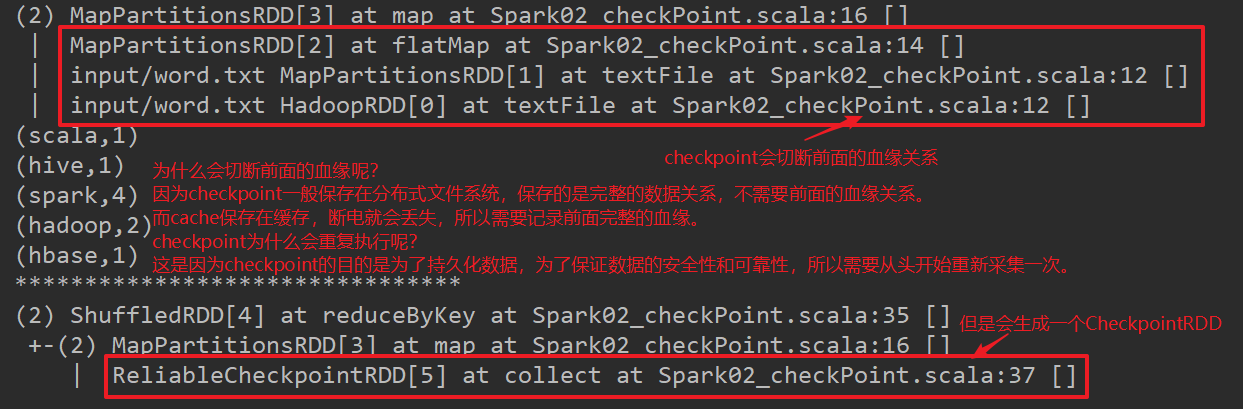
②检查点checkPoint
checkpoint和cache,persist的区别是:
cache和persist当前app执行结束,缓存数据会删除。cache会将数据保存到内存,断电可能会丢失,persist会将数据保存到磁盘,但是app结束还是会将缓存数据删除。
checkpoint:需要指定一个checkpointDir(“dir”),就算app结束也会产生本地的缓存文件。
(但是一般不会使用checkpoint,因为可能会产生大量的小文件)
checkpoint会重复执行
cache & persist不会重复执行
的目的是为了数据的重复使用,所以会在指定collect的时候,触发cache或persist将数据保存,下一个使用可以直接在缓存中取。
checkpoint会重复执行
这样的目的:为了长久保存,为了保证数据的完整和安全,所以要再启动一个job从头再走一遍。所以会重复。
一般checkpoint会和cache或persist联合使用,这样就不会重复执行了~(在checkpoint前cache)
checkpoint的血缘关系
- checkpoint会切断RDD的血缘关系
- checkpoint是在血缘关系中添加了一个缓存依赖
checkpoint为什么会切断前面的血缘关系呢?
因为checkpoint一般保存在分布式文件系统,记录了完整的数据关系,所以不需要前面的血缘关系;而cache保存在内存中,断电会丢失,所以需要记录前面完整的血缘。
object Spark02_checkPoint {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
sc.setCheckpointDir("cp")
val rdd: RDD[String] = sc.textFile("input/word.txt")
val rdd1: RDD[String] = rdd.flatMap(_.split(" "))
val rdd2: RDD[(String, Int)] = rdd1.map((_, 1))
//TODO RDD的检查点
// Checkpoint directory has not been set in the SparkContext
// 检查点保存的数据可以给其他app使用
// 1.cache & persist不会重复使用
// 2.checkpoint会重复执行,当调用检查点操作时,会额外启动一个Job执行
// 一般情况下,checkpoint应该和cache联合使用
// 血缘关系
//1. checkpoint会切断一切RDD的血缘关系
//2. cache是在血缘关系中添加了一个缓存依赖
//checkpoint使用的其实不多,因为可能会产生大量的小文件
// rdd2.cache()
rdd2.checkpoint()
println(rdd2.toDebugString) //checkpoint之前的血缘关系(因为是collect之后才会checkpoint)
val rdd3: RDD[(String, Int)] = rdd2.reduceByKey(_ + _)
rdd3.collect().foreach(println)
println("********************************")
println(rdd3.toDebugString) //checkpoint之后的血缘关系
sc.stop()
}
}
5.11 RDD的分区器
spark分区器的目的是什么?
是指明数据保存在哪个分区。
Spark分区器的种类有:
Hash分区器:根据给定的key,计算hashCode,并除以分区个数取余数
reduceByKey是用的Hash
Range分区器:将一定范围内的数据映射到一个分区内,尽量保证每个分区数据均匀。
sortByKey就是用的Range
用户自定义分区器
如何实现一个自定义分区器呢?
第一步:创建一个自定义的分区器类
第二步:继承Partitioner类
第三步:重写两个抽象方法:
- numPartitions:分区的数量 - getPartition:根据数据的key,判断数据 进入哪个分区
object Spark01_Partition {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd: RDD[(String, Int)] = sc.makeRDD(List(
("nba", 132),
("cba", 22),
("nba", 2),
("wnba", 89)
), 2)
//通过分区器决定数据所在的分区
val rdd1: RDD[(String, Int)] = rdd.partitionBy(new BasketBallPartitioner(2))
rdd1.saveAsTextFile("output")
sc.stop()
}
//自定义数据分区器
//1 继承Partition
//2 重写抽象方法:
// - numPartitions 返回分区的数量
// - getPartition 根据数据的key值来判断数据进入哪个分区
class BasketBallPartitioner(num: Int) extends Partitioner{
//分区的数量
override def numPartitions: Int = num
//根据数据的key来获取所在分区的位置
override def getPartition(key: Any): Int = {
key match {
case "nba" => 0
case _ => 1
}
}
}
}
5.12 RDD文件读取与保存
RDD的文件格式有:TextFile;SequenceFile;ObjectFile
- 读取文件的时候需要注意:
- 读取SequenceFile,因为保存的是K-V类型的文件,所以读取的时候需要指定[K,V]的泛型
- 读取ObjectFile,因为保存的是object类型的文件,所以读取时候需要指定[(K,V)]的泛型
①保存到文件
object Spark01_SaveFile {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd: RDD[(String, Int)] = sc.makeRDD(List(
("a", 1), ("b", 2), ("c", 3),
("aa", 2), ("bb", 9), ("cc", 6)
), 2)
rdd.saveAsTextFile("out_TextFile")
rdd.saveAsSequenceFile("out_SequenceFile")
rdd.saveAsObjectFile("out_ObjectFile")
sc.stop()
}
}
②读取文件
object Spark02_SaveFile {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.textFile("out_TextFile")
val rdd1: RDD[(String, Int)] = sc.sequenceFile[String, Int]("out_SequenceFile")
val rdd2: RDD[(String, Int)] = sc.objectFile[(String, Int)]("out_ObjectFile")
rdd.collect().foreach(println)
println("********************************")
rdd1.collect().foreach(println)
println("********************************")
rdd2.collect().foreach(println)
sc.stop()
}
}
5.13 累加器
分布式共享只写变量
累加器有什么好处?
累加器没有shuffle落盘,性能会好一点
累加器和collect有什么区别?
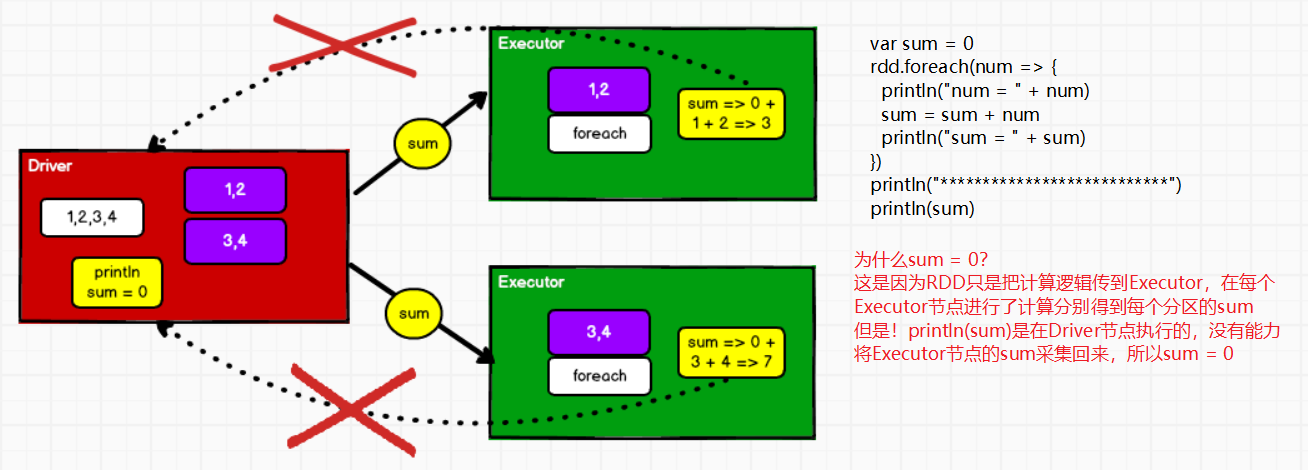
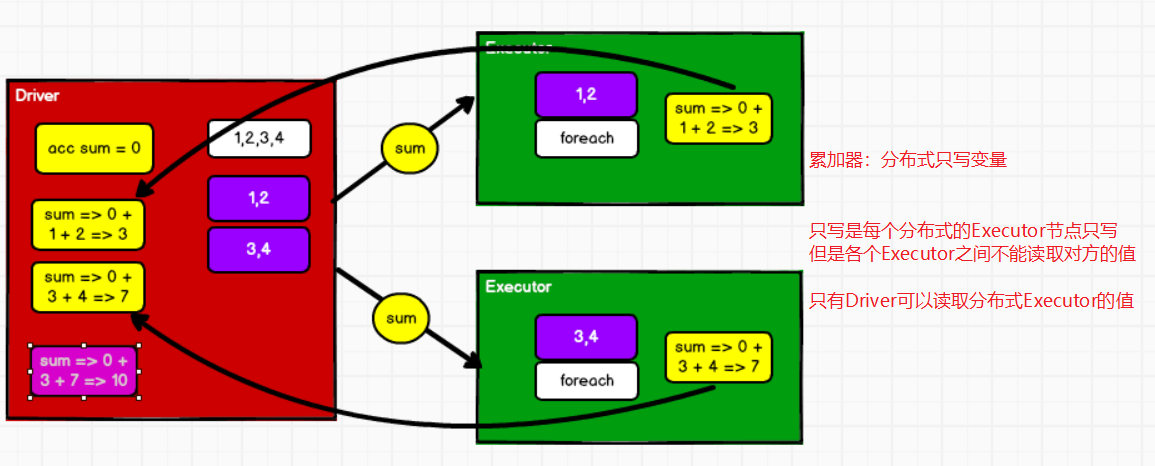
①系统累加器
累加器:用来把Executor端变量的信息聚合到Driver端。
//TODO Spark默认提供的累加器有3种类型
// 1. LongAccumulator:整型
// 2. DoubleAccumulator:浮点型
// 3. CollectionAccumulator:List集合类型
object Spark01_Acc {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
//TODO Spark提供了一种特殊的数据结构,用于通知Executor在计算完成后的数据返回到Driver
// Driver会将多个Executor计算的结果合并在一起,获得最终的结果
// 这种数据结构称之为数据采集器(累加器)
//longAccumulator(变量名,用于监控时显示)
//1 声明累加
val sum = sc.longAccumulator("sum")
rdd.foreach(num => {
//2 使用累加器
sum.add(num)
})
//3 获取累加器结果
println(sum.value)
sc.stop()
}
}
②自定义累加器 - wordcount
自定义累加器的步骤:
步骤1:继承AccumulatorV2类AccumulatorV2[IN, OUT]
步骤2:定义泛型:[IN, OUT]
- IN:(String, Int);累加器需要将什么类型的数据相加
- OUT:mutable.Map[String, Int];累加器返回结果的类型
步骤3:重写(3定义),(3计算)的方法
isZero();判断累加器是否是初始状态;判断条件是:自己定义的wcmap是否为空
copy():复制一个累加器; Executor传回Driver需要复制传回去一个新的累加器
累加器copy方法的调用次数和分区数量无关,而是和序列化的次数有关
reset():重置累加器;万一累加器不是初始状态,那么里面就会有值,那么清空一下
add():向累加器中添加数据;在Executor端执行
merge:合并多个累加器的值,Driver端执行
value:返回累加器的计算结果;Executor端执行
注意:先调用copy --> reset --> isZero
步骤4:自定义累加器的使用:
- 1 创建累加器:new WordCountAccumulator()
- 2 向Spark进行注册:sc.register(acc, “WordCount”)
- 3 向累加器中增加数据acc.add()
- 4 获取累加器的累加结果acc.value()
object Spark03_Acc_wordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val lines: RDD[String] = sc.textFile("input/word.txt")
val wordToOne: RDD[(String, Int)] = lines.flatMap(_.split(" ")).map((_, 1))
//TODO 声明自定义累加器
// 可以看到 class LongAccumulator extends AccumulatorV2[jl.Long, jl.Long] {
// TODO 1. 创建累计器
val acc = new WordCountAccumulator()
// TODO 2. 向Spark进行注册
sc.register(acc, "WordCount")
wordToOne.foreach(kv => {
//TODO 3. 向累加器中增加数据
acc.add(kv) //闭包检测
})
//TODO 4. 获取累加器的累加结果
println(acc.value)
sc.stop()
}
//自定义累加器(WordCount)
//TODO 1 继承AccumulatorV2[IN, OUT]
// 2 定义泛型【IN,OUT】
// IN:(String,Int),定义什么类型的数据增加到累加器中
// OUT:mutable.Map[String,Int],累加器将什么类型的数据返回
class WordCountAccumulator extends AccumulatorV2[(String, Int), mutable.Map[String, Int]]{
//var wcmap = mutable.Map[String, Int],这表示生成一个单例对象 => Map$
//var wcmap = mutable.Map[String, Int](),Map.apply() => Map
var wcmap = mutable.Map[String, Int]()
//判断累加器是不是初始状态;wcmap为空那就是初始的
override def isZero: Boolean = {
wcmap.isEmpty
}
//TODO 复制累加器
override def copy(): AccumulatorV2[(String, Int), mutable.Map[String, Int]] = {
new WordCountAccumulator()
}
//TODO 重置累加器
override def reset(): Unit = {
wcmap.clear()
}
//TODO 向累加器中增加数据;Executor端执行
override def add(t: (String, Int)): Unit = {
val k = t._1
val v = t._2
// wcmap.updated(k, wcmap.getOrElse(k, 0) + v)
// updated()会产生一个新的结果,这里我们需要对wcmap这个map更新操作,如果产生新的wcmap不会变
wcmap.update(k, wcmap.getOrElse(k, 0) + v)
}
//TODO 合并多个累加器的值;Driver端执行
override def merge(other: AccumulatorV2[(String, Int), mutable.Map[String, Int]]): Unit = {
var map1 = this.wcmap
var map2 = other.value
//不断更新这个wcmap
this.wcmap = map1.foldLeft(map2) {
case (map, (key, value)) => {
map.updated(key, map.getOrElse(key, 0) + value)
}
}
}
//TODO 返回累加器的计算结果;Executor端执行
override def value: mutable.Map[String, Int] = {
wcmap
}
}
}
TODO 累加器在转换算子中使用时,当遇到了多个执行算子,累加器会重复执行。
一般推荐在行动算子中使用累加器,如果非要在转换算子中使用累加器,需要保证行动算子只会使用一次。
object Spark04_Acc {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(1 to 10, 2)
//TODO 累加器在多次行动算子执行时,数据可能计算有问题,这是因为RDD不保存数据,如果有多个执行算子,
// 会导致从头开始再执行一次。
// 一般推荐累加器在行动算子中执行,如果非要在转换算子中使用,需要保证行动算子只会执行一次
val sum = sc.longAccumulator("avg")
// var sum = 0
//filter是转换算子,当有多个执行算子时,会累加器会重复执行
val rdd1: RDD[Int] = rdd.filter(num => {
var flg = num % 2 != 0
if (!flg) {
// sum += 1
sum.add(1)
}
flg
})
rdd1.collect()
rdd1.foreach(println)
println("*******************")
println(sum.value)
sc.stop()
}
}
5.14 广播变量
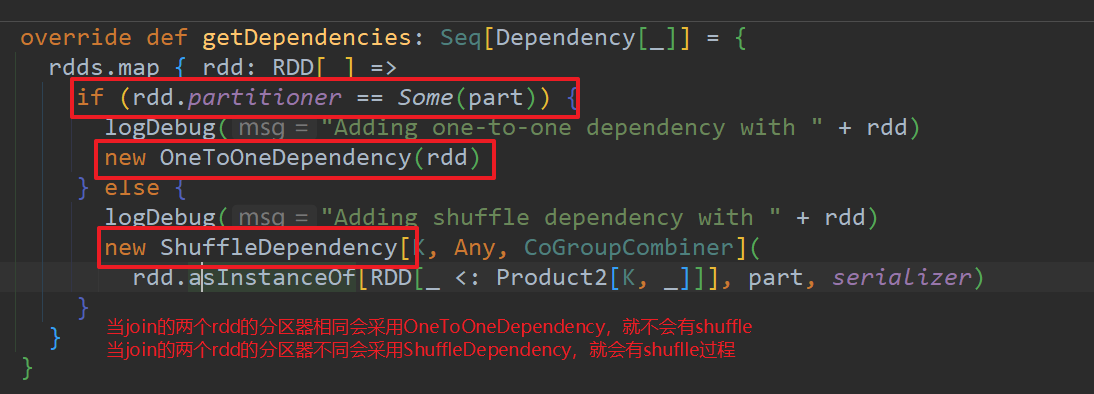
产生问题1:当使用join连接两个rdd的时候,因为会产生笛卡尔积,数据量会成几何式增长;并且join算子有可能有shuffle过程,就会有落盘操作,效率低。
object Spark01_BroadCast {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("BroadCast")
val sc = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = sc.makeRDD(List(
("a", 1), ("b", 2)
))
val rdd2: RDD[(String, Int)] = sc.makeRDD(List(
("a", 3), ("b", 4)
))
//1 join算子不推荐使用,因为会产生笛卡尔积,数据量成几何式增长
//2 join算子有shuffle过程,会有落盘操作,效率更是很低!
// 如果分区器相同:OneToOneDependency
// 如果分区器不相同:ShuffleDependency,那么就会有shuffle
val result: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
result.collect().foreach(println)
}
}
解决方法:那么就不适用join算子;采用下面代码的方式:
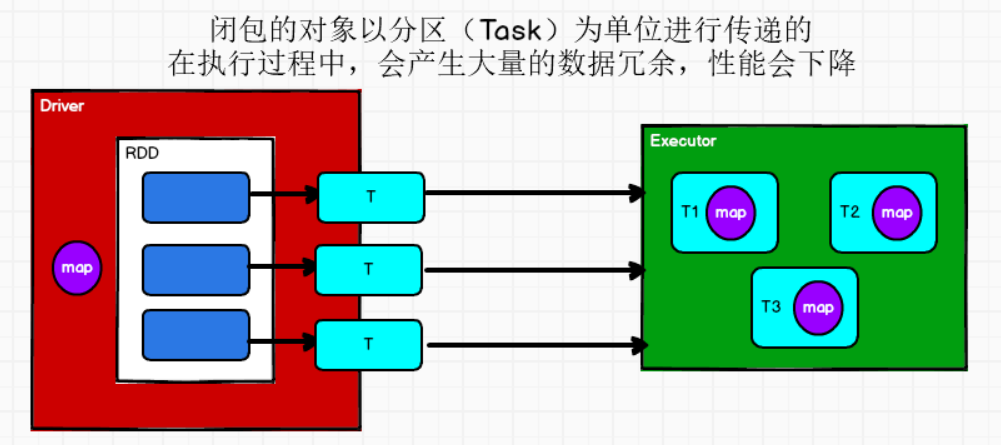
产生问题2:Stage的最后一个RDD的分区会产生分区数量的Task,所有的Task传给一个Executor执行,需要传多个重复的map(如下代码)。这样就会导致存在大量的冗余数据。占用大量内存。
object Spark02_BroadCast {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("BroadCast")
val sc = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = sc.makeRDD(List(
("a", 1), ("b", 2)
))
val map = Map(("a", 3), ("b", 4))
//不使用join就不会造成大数据量,也不会有shuffle过程
//但是因为多次使用到了map这个变量,就会造成资源的浪费!
val rdd3: RDD[(String, (Int, Int))] = rdd1.map {
case (key, value) => {
(key, (value, map.getOrElse(key, 0)))
}
}
rdd3.collect().foreach(println)
sc.stop()
}
}
解决方法:广播变量 sc.broadcast(map)
广播变量:分布式共享只读变量
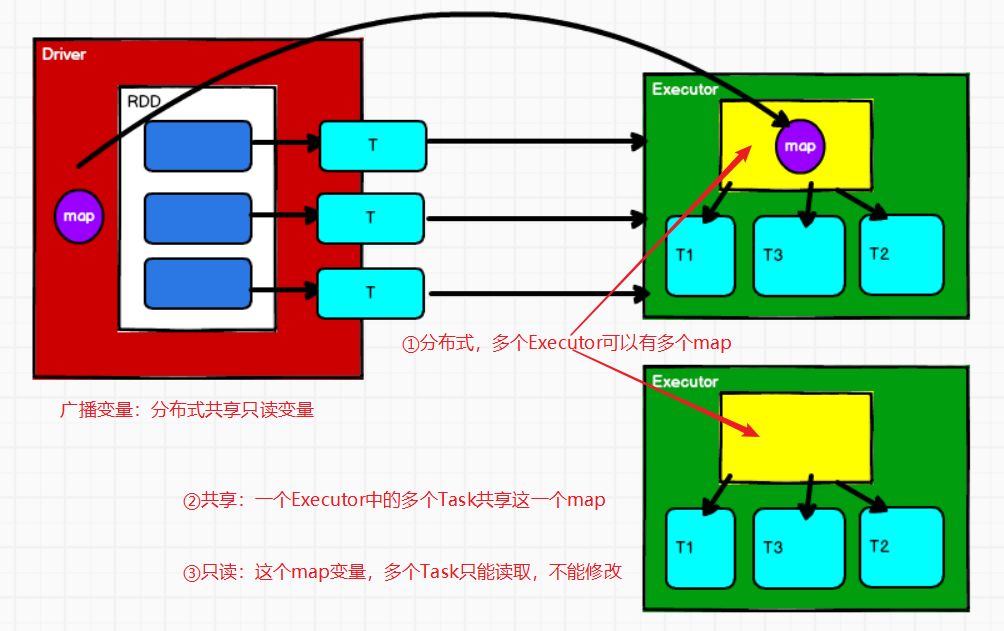
object Spark03_BroadCast {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("BroadCast")
val sc = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = sc.makeRDD(List(
("a", 1), ("b", 2)
))
val map = Map(("a", 3), ("b", 4))
//TODO 1 创建广播变量
val bc: Broadcast[Map[String, Int]] = sc.broadcast(map)
val result: RDD[(String, (Int, Int))] = rdd1.map {
case (key, value) => {
//TODO 2 使用广播变量
(key, (value, map.getOrElse(key, 0)))
}
}
result.collect().foreach(println)
sc.stop()
}
}















 2188
2188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











