




3D物体
一、Objaverse 1.0
Objaverse 1.0: a large dataset of objects with 800K+ (and growing) 3D models with descriptive captions, tags and animations. Assets not only belong to varied categories like animals, humans, and vehicles, but also include interiors and exteriors of large spaces that can be used, e.g., to train embodied agents(具身智能是Embodied Intelligence,这个应该可以理解为机器人)
Objaverse 1.0 includes 818K 3D objects. There are >2.35M tags on the objects, with >170K of them being unique. We estimate that the objects have coverage for nearly 21K WordNet entities. Objects were uploaded between 2012 and 2022, with over 200K objects uploaded just in 2021. 下图是Objaverse数据集的一些数据展示,包括物体所属的Sketchfab categories、tags的词云、tags的频率图、Objaverse-LVIS categories中的object数量
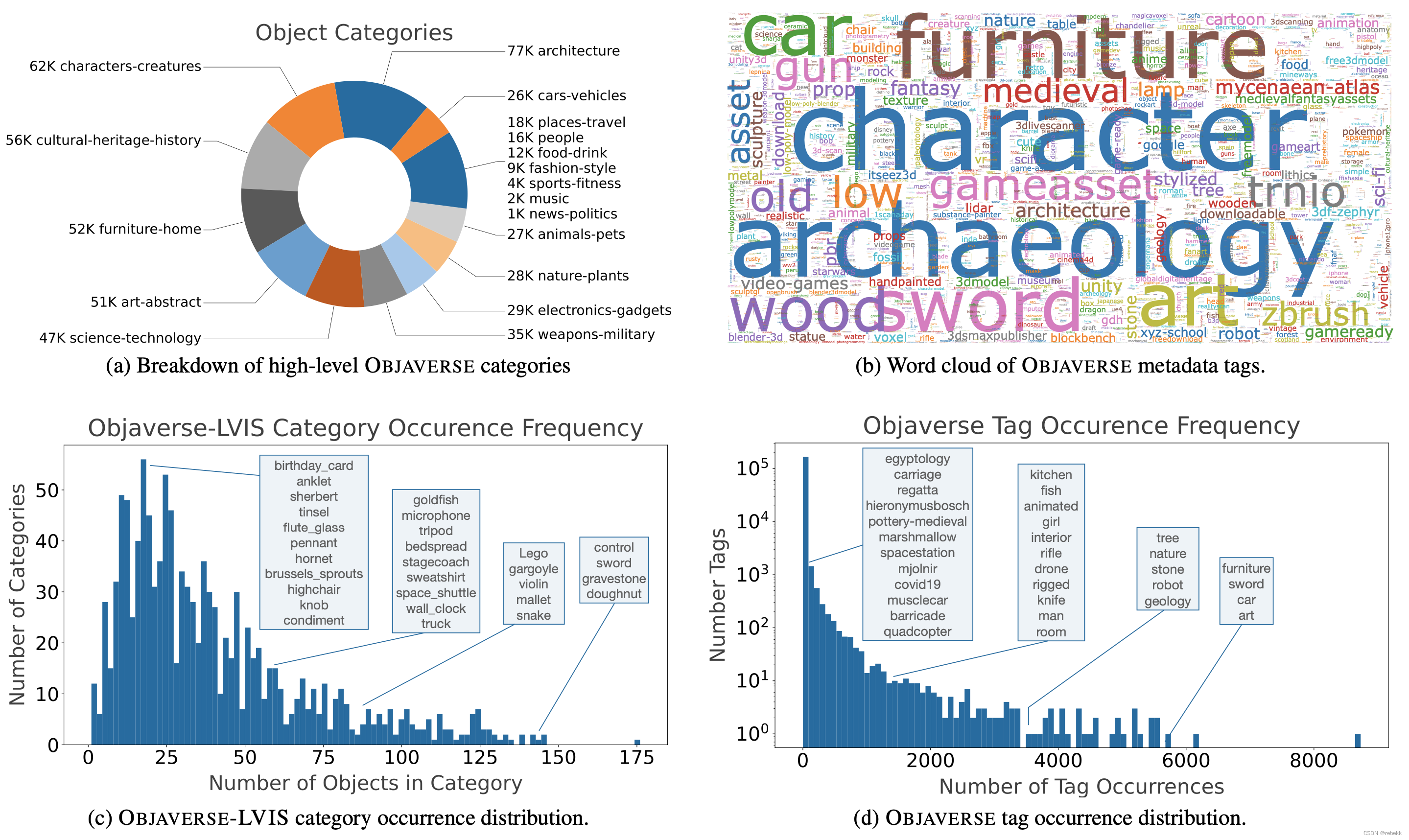
Objaverse contains 3D models for many diverse categories including tail categories which are not represented in other datasets. It also contains diverse and realistic object instances per category. Qualitatively, the 3D-meshes generated by the Objaverse-trained models are high-quality and diverse, especially when compared to the generations from the ShapeNet-trained model.

上图是Objaverse的作者,分别基于Objaverse的Bag分类和ShapeNet的bag分类,训练了一个模型,生成的3D物体效果。结果就是前者质量更高一点,然后说是91%的情况下Objaverse训练的模型生成的物体在外观上更具多样化
The objects are sourced from Sketchfab, an online 3D marketplace where users can upload and share models for both free and commercial use. Objects selected for Objaverse have a distributable Creative Commons license and were obtained using Sketchfab’s public API.
Objaverse objects inherit a set of foundational annotations supplied by their creator when uploaded to Sketchfab. 下图展示了每个model的可用metadata示例,metadata包括一个名字、一些固定属性、一些tags、和一个自然语言描述


上图是Objaverse和ShapeNet数据集关于车辆、床铺、花瓶和书包这四类的物体模型对比,可见ShapeNet的模型相比起来就非常简单,因为Objaverse的对象来自许多3D内容创建平台,而ShapeNet都来自SketchUp(一个为简单的建筑建模而构建的3D建模平台)。91%的情况下Objaverse训练的模型生成的物体在外观上更具多样化
二、Objaverse-XL: 2023.7.11
Objaverse-XL is 12x larger than Objaverse 1.0 and 100x larger than all other 3D datasets combined.
Objaverse-XL comprises of over 10 million 3D objects, representing an order of magnitude more data than the recently proposed Objaverse 1.0 and is two orders of magnitude larger than ShapeNet.
Objaverse-XL is comprised of 10.2M 3D assets.
Objaverse-XL is composed of 3D objects coming from several sources, including GitHub, Thingiverse, Sketchfab, Polycom, and the Smithsonian Institution. While the data sourced from Sketchfab for our project is specifically from Objaverse 1.0, a dataset of 800K objects consisting of Creative Commons-licensed 3D models. Each model is distributed as a standardized GLB file.
Objaverse-XL评Objaverse 1.0:Objaverse 1.0 introduced a 3D dataset of 800K 3D models with high quality and diverse textures, geometry and object types, making it 15× larger than prior 3D datasets. While impressive and a step toward a large-scale 3D dataset, Objaverse 1.0 remains several magnitudes smaller than dominant datasets in vision and language. As seen in Figure 2 and Table 1, Objaverse-XL extends Objaverse 1.0 to an even larger 3D dataset of 10.2M unique objects from a diverse set of sources, object shapes, and categories.

三、ShapeNet: 2015.12.9
Objaverse-XL评ShapeNet:ShapeNet has served as the tesetbed for modeling, representing and predicting 3D shapes in the era of deep learning. Notwithstanding its impact, ShapeNet objects are of low resolution and textures are often overly simplistic. Other datasets such as ABO, GSO, and OmniObjects3D improve on the texture quality of their CAD models but are significantly smaller in size.
Objaverse-XL评ShapeNet:3D datasets such as ShapeNet rely on professional 3D designers using expensive software to create assets, making the process tremendously difficult to crowdsource and scale.
ShapeNet has indexed more than 3,000,000 models, 220,000 models of these models are classified into 3,135 categories (WordNet sunsets).
In order for the dataset to be easily usable by researchers it should contain clean and high quality 3D models. We identify and group 3D models into the following categories: single 3D models, 3D scenes, billboards, and big ground plane. We currently include the single 3D models in the ShapeNetCore subset of ShapeNet.
ShapeNetCore is a subset of the full ShapeNet dataset with single clean 3D models and manually verified category and alignment annotations. It covers 55 common object categories with about 51,300 unique 3D models.

大规模场景数据集
- 如何获得(无人机航拍、空中和地面拍摄、地面采集6个GoPro):汽车上的Lidar、radar、camera采集,如下图
- 数据集包含(照片、相机位姿、点云?):包含大约140万张相机图像、39万个激光雷达(Lidar)扫描点云、140万个雷达(Radar)扫描点云和4万个关键帧中的140万个object bounding boxes。camera原始数据大小为1600*900
- 数据集内容(别墅、塔?)
- 场景面积(GigaNVS是从1300m2~3000000m2):没有明确提到覆盖的面积
- 每个场景多少张照片、照片像素(GigaVNS每个场景1600~18000张5K/8K照片):总共注释了1000个场景,每个场景大约20秒。
- Mini:由10个场景组成,包含完整的原始数据和标注信息,主要用于数据集的熟悉
- TrainVal:训练/验证集,包含850个场景,其中700个训练场景、150个验证场景
- Test:测试集,包含150个场景,不含标注数据
- 照片描述(GigaNVS是既有远处的整体照片又有近处的细节照片,距离5m到1000m):
2020年nuScenes论文中的:
multimodal dataset
如下所示,三种sensor type各有各的缺点和长处,因此很有必要搞一个多模态数据集
- Cameras:
- Allow accurate measurements of edges, color and lighting enabling classification and localization on the image plane
- However, 3D localization from images is challenging
- Lidar pointclouds
- contain less semantic information but highly accurate localization in 3D
- but lidar data is sparse and the range is typically limited to 50-150m
- Radar sensors
- radar sensors achieve a range of 200-300m and measure the object velocity through the Doppler effect
- but the returns are even sparser than lidar and less precise in terms of localization
- 在nuScenes之前,貌似并没有任何自动驾驶数据集提供radar data
介绍
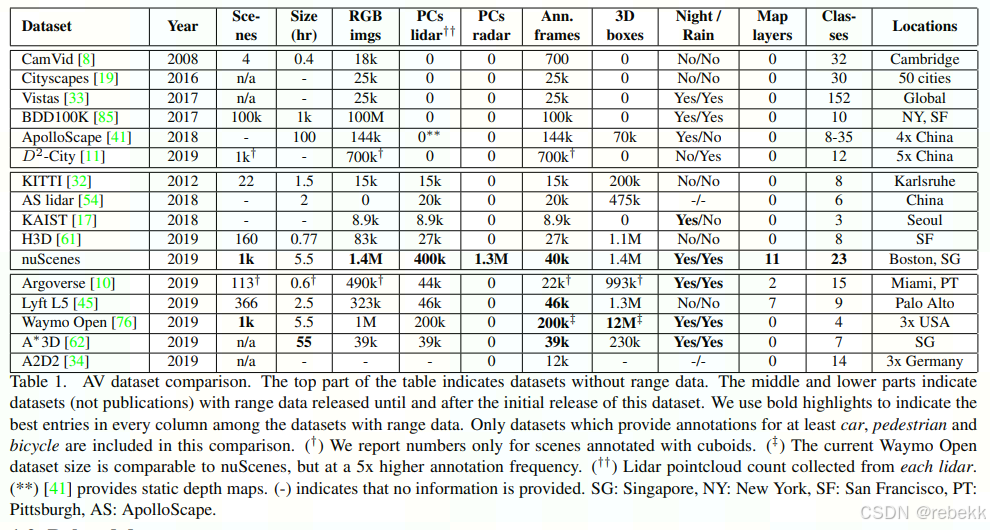
- 是一个large-scale multimodal dataset with 360° coverage across all vision and range sensors collected from diverse situations alongside map information,和其之前的数据集相比,在数据量和数据复杂度上是一个质的飞跃,也是第一个提供360° sensor coverage的,也是第一个包含自动驾驶可用的公开道路的radar data的,也是第一个包含夜晚和下雨天数据的数据集,其除了object class和location之外,还包含object attributes和scene descriptions
- related datasets
- KITTI是多模态数据集的先驱,提供稠密的点云(从一个lidar sensor获取)、front-facing stereo images和GPS/IMU data,提供200k 3D boxes over 22 scenes。只有向前视图下的物体才会被标注
- H3D数据集包含160个场景,with a total of 1.1M 3D boxes annotated over 27k frames。360°视图下的物体都会被标注
- 在最初的nuScenes数据集release后,【Waymo Open Dataset,Argoverse,A*3D Dataset,A2D2,Lyft Level 5 AV Dataset】都跟着发出了它们自己的大规模自动驾驶数据集。在这里只有Waymo Open数据集提供了显著更多的annotations;Lyft L5 dataset是最接近nuScenes的,其使用nuScenes database schema发布,因此可通过nuScenes devkit进行parse
- 采集过程
- 在波士顿和新加坡驾驶(两个城市都以交通密集和驾驶场景复杂闻名)
- manually select 84 logs with 15h of driving data (242km travelled at an average of 16km/h)
- 驾驶路线的选择保证了多样性:locations (urban/residential/nature/industrial), times (day/night), weather conditions (sun/rain/clouds)
- 汽车的传感器设置如下图
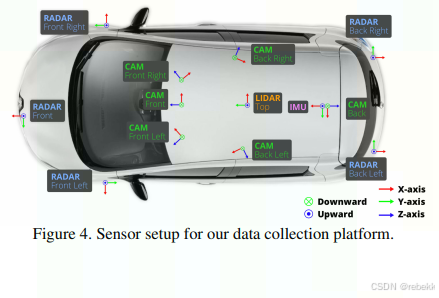
- 相机:6个摄像头,1600*900的分辨率,采用JPEG格式压缩,采样频率为12Hz
- 激光雷达(Lidar):1台32线旋转式激光雷达,20Hz采样频率,360°水平FOV,-30°-10°的垂直FOV,探测距离70m,探测精度2cm,每秒140万点云
- 毫米波雷达(Radar):5个77GHz的毫米波雷达,FMCW调频,13Hz采样频率,探测距离250m,速度精度±0.1km/h
- GPS和IMU:20mm的RTK定位精度,1000Hz采样频率
- 场景选择:采集到raw sensor data后,我们手动挑选了1000个场景(每个场景有20s),挑选根据是有high traffic density (e.g. intersections, construction sites)、rare classes (e.g. ambulances, animals)、potentially dangerous traffic situations (e.g. jay-walkers, incorrect behavior)、maneuvers (e.g. lane change, turning, stopping)、对一个自动驾驶汽车来说可能很麻烦的情况
- 数据标注:选择好场景后,以2Hz的频率来采样keyframes(image, lidar, radar)
- 标注内容:数据集中有23个类别,包含不同的车辆、行人、移动设备和其他物体


















 412
412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









