






实习学习模型、算法总结1---MMOE算法模型
原文链接
KDD 2018 | Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
仅自己学习,谈一下宏观理解,更具体以及公示推导请看原文或以下:
详解谷歌之多任务学习模型MMoE(KDD 2018) - 知乎 (zhihu.com)
(2条消息) 多任务学习模型详解:Multi-gate Mixture-of-Experts(MMoE ,Google,KDD2018)_ty44111144ty的博客-CSDN博客
(2条消息) 多目标MMOE_serenysdfg的博客-CSDN博客_mmoe
本质是与Shared-Bottom底层网络共享加深了专业领域程度,同时融入了注意力机制(信息融合)。首先需要学习一下基础知识。
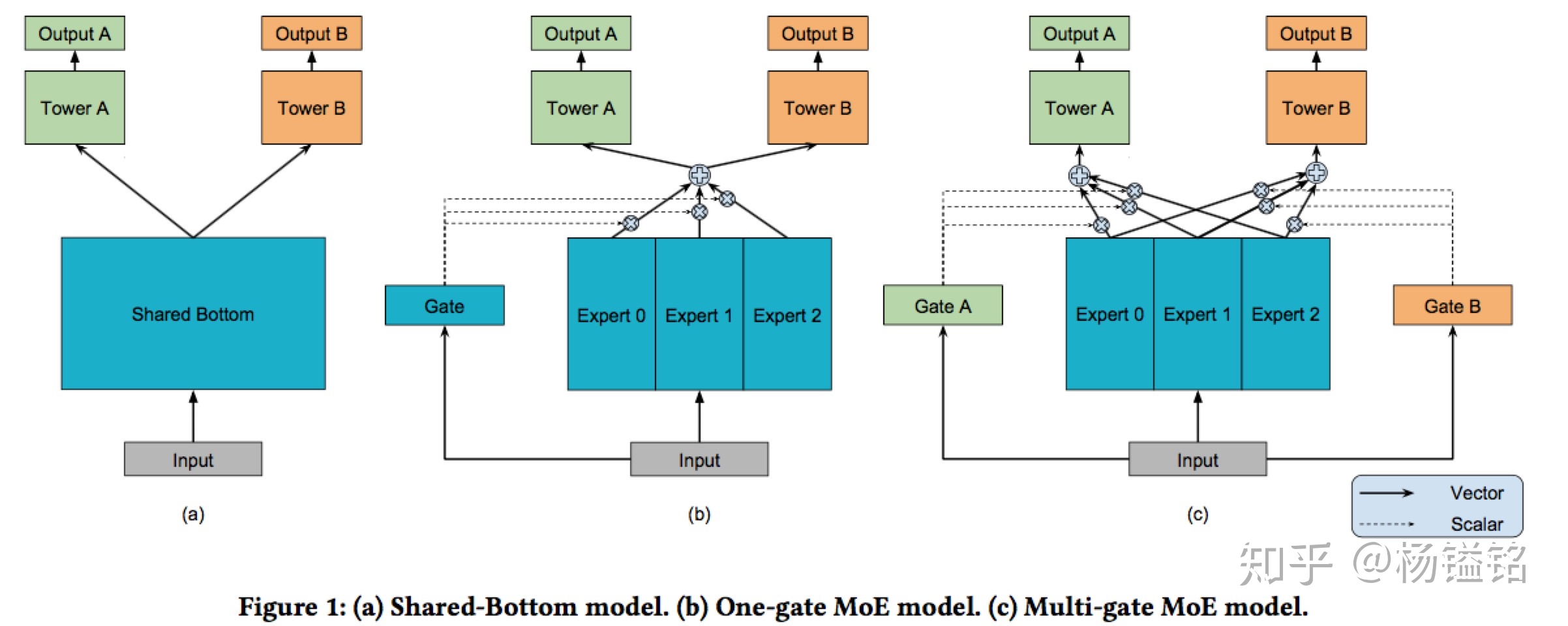
上面是share-bottom和moe的结构,expert0,1,2,3其实就是网络,应该是三个独立的网络目前我的理解,gate也是网络用于产生一组权重来对expert进行加权组合。其实我觉得别人说的蛮清楚的,就抄了下来.

、到这里,其实应该就能解释为什么说moe加深了专业领域,我画了一幅图帮助理解
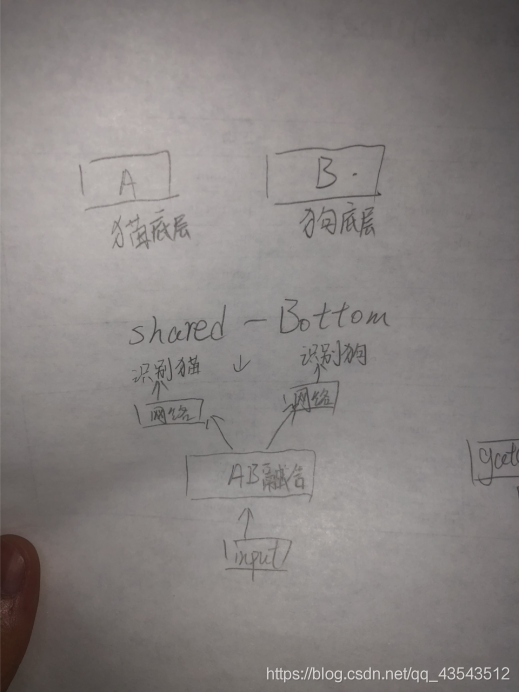
可以看出,A,B在moe是expert1,2.在shared-bottom中因为只存在一个底层网络,那么只能把两个专家网络融合,这样势必降低了专业领域的程度.其实很好理解,术业有专攻,shared-bottom的底层要为多个任务同时提供底层时,就需要对任何一个任务都偏向也就是对任何一个都不完全偏向。
那么在moe中
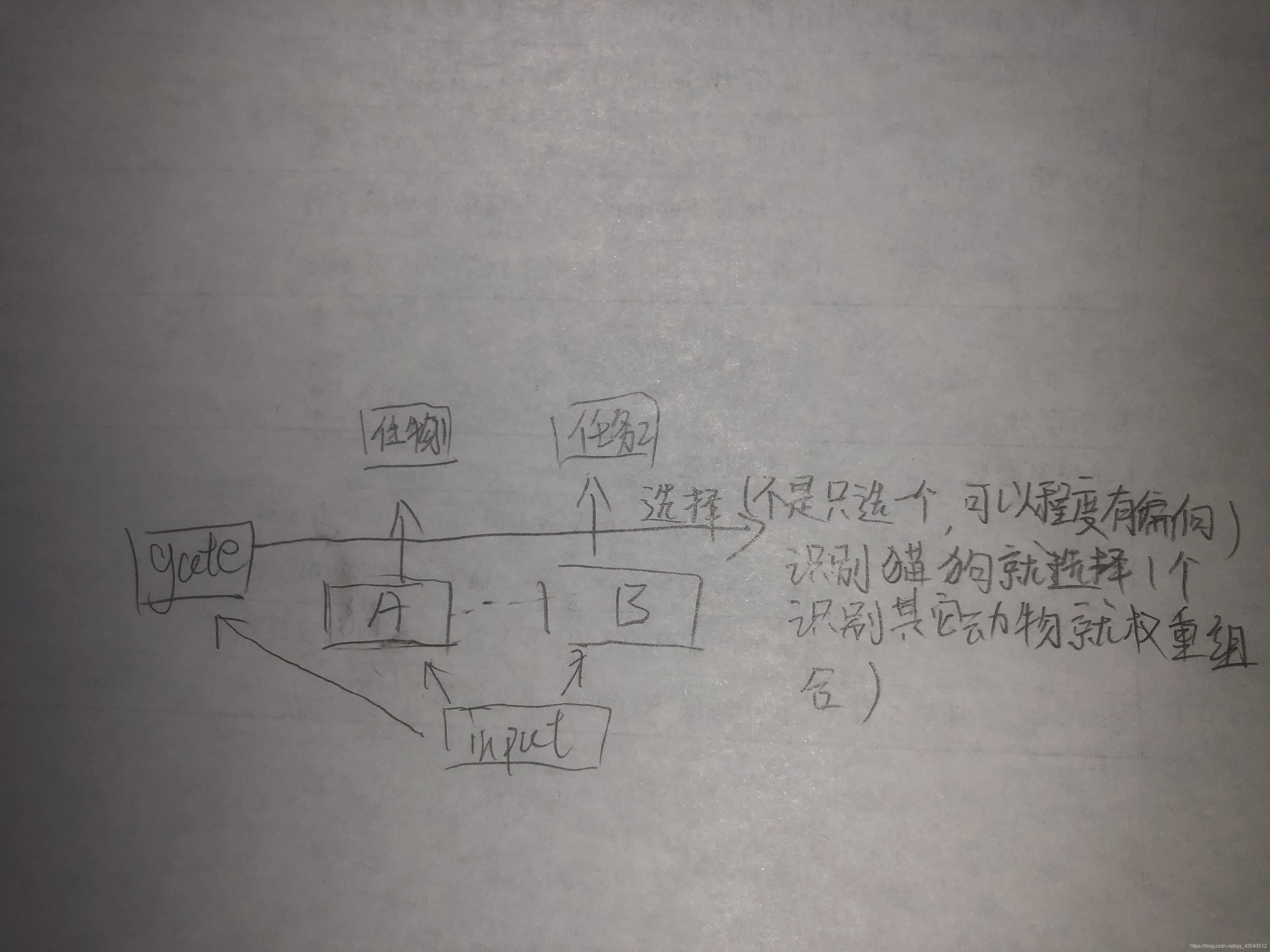
底层网络被拆成更具体的expert网络,每一个expert都有自己擅长的领域,当做任务时,通过gate网络进行选择expert网络,那么gate时如何选择的呢,其实这个可以理解成bert模型里的自注意力机制,gate网路的作用是生成一组权重,将expert加权求和输出,当权重为0,那么就不选择这部分expert,也就是说这部分expert不擅长他。
假如我任务1是识别猫,任务2是识别狗。gate分别会输出1 0和0 1两组权重,用更擅长更专业的底层去做这件事情,当我们要识别老虎时,老虎跟猫更相似可能gate就会输出 0.9 0.1这样对任务的区分度就更好效果肯定也更好。到这里就是mmoe的宏观理解
下面是mmoe的具体结构















 2668
2668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









