







这是算法第四版第一章第五节的内容,关于连通图的问题。我没有对算法进行问题描述,所以不适合不了解UF算法所解决的问题的读者。
另外如果你是,从预测程序运行时间那一篇来的。下面的内容会帮你,了解时间预测的具体步骤,算法的内容你可以忽略,只看估测过程。
文章目录
union-find 算法
API
| 方法 | 作用 |
|---|---|
| public ClassName(int N) | 接收总触点数并初始化连通标识符和连通分量数 |
| public boolean connected(int p, int q) | 检测两个触点是否属于同一个分量 |
| public int size() | 返回连通分量总数 |
| public int find(int dot) | 查找一个触点的连通分量标识符 |
| public void union(int p, int q) | 将p,q所属的分量合并(合并于p或者q) |
Quick-find算法
时间复杂度分析
每次find() 访问数组次数是 一次
每次union() 访问数组的次数是 N次
将规模为N的触点完全连通成一个分量 需要的访问次数是
lim
N
→
∞
N
∗
(
N
−
1
)
=
N
2
\lim_{N\rightarrow\infty}N*(N-1) = N^2
N→∞limN∗(N−1)=N2
public class QuickFind {
private int[] id;
private int count;
public QuickFind(int N)
{
count = N;
id = new int[N];
for(int i = 0;i<N;i++)
{
id[i] = i;
}
}
public int size()
{
return count;
}
public boolean connected(int p, int q)
{
return find(p) == find(q);
}
public int find(int dot)
{
return id[dot];
}
public void union(int p, int q)
{
int pId = find(p);
int qId = find(q);
for(int i = 0;i<id.length;i++)
{
if(id[i] == pId) id[i] = qId;
}
count--;
}
}
一般预测
根据(N,T)数据对描绘出来
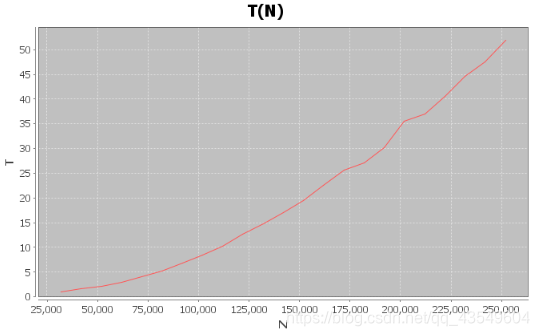
根据访问数组总次数的分析,可以知道这个算法的时间复杂度是平方级别的
这个图像也像是二次函数的右边部分
倍率实验
实验数据格式
数据规模—运行时间—倍率(与上一次运行时间之比)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bKcNAeP1-1593251570462)(C:\Users\肖沫\AppData\Roaming\Typora\typora-user-images\image-20200626225417217.png)]](https://img-blog.csdnimg.cn/20200627175422325.png)
(
预
测
起
点
)
N
0
=
64000
(预测起点)N_0=64000
(预测起点)N0=64000
( 预 测 起 点 的 实 验 耗 时 ) b a s e T i m e = 3.5 s (预测起点的实验耗时)baseTime = 3.5s (预测起点的实验耗时)baseTime=3.5s
( 倍 率 ) 2 b = 3.7 (倍率)2^b = 3.7 (倍率)2b=3.7
- 为什么预测起点选择 64000 ? 看实验数据倍率趋近于3.7,而64000处于倍率趋近于3.7的数据项的较中间位置。
- 为什么倍率选3.7?数据规模越大,倍率越趋近于理论倍率。
- 为什么只需要一组实验数据就能够进行预测?当我们尝试用更多组数据来进行求平均或者怎么样,这都是不准确的,我们预测的理论本身就是估计的所以没有必要多组求平均。
预测
-
N =256,000 time ≈ 47.915 s (偏低)
-
N = 512,000 time ≈ 177.2855 s (偏低)
-
N = 1,000,000 time ≈ 655.95 (11分钟左右)
-
N = 10,000,000 time ≈ 122936.78 (34小时左右)
幂次法则
数据格式
数据规模 N-----运行时间 s
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ELHs6pH9-1593251570477)(C:\Users\肖沫\AppData\Roaming\Typora\typora-user-images\image-20200627163435784.png)]](https://img-blog.csdnimg.cn/202006271754434.png)
纵坐标是,lg(T)
横坐标是,lg(N)
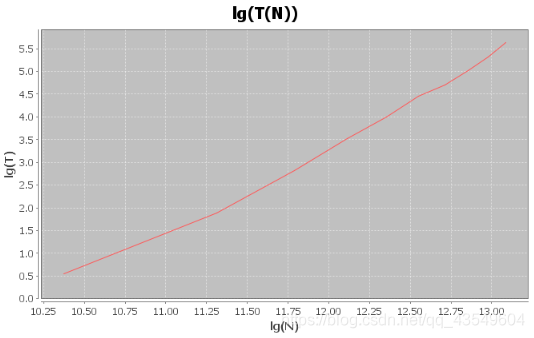
计算
数学模型
l
g
(
T
(
N
)
)
=
k
l
g
(
N
)
+
l
g
(
a
)
①
lg(T(N)) = klg(N) + lg(a)①
lg(T(N))=klg(N)+lg(a)①
T = T ( N ) T = T(N) T=T(N)
k就是斜率,根据图像估算
k
=
2
k = 2
k=2
变化一下上面的①公式
T
(
N
)
=
a
∗
N
k
②
T(N) = a*N^k②
T(N)=a∗Nk②
从上面的实验数据取(382000,150.152)再加上 已知的 k代入公式② ;
计算出:
a
=
1.0
∗
1
0
−
9
a = 1.0*10^{-9}
a=1.0∗10−9
最终得到函数:
T ( N ) = 1.0 ∗ 1 0 − 9 ∗ N 2 T(N) = 1.0*10^{-9}*N^{2} T(N)=1.0∗10−9∗N2
- 为什么选(382000,150.152)?位置在中间靠后的数据项都行。
- k怎么算的? 图像的线性性不是很强,所以k只能是一种估计,我的计算用的是靠后的坐标,为了好算取了整数。
预测
-
N =256,000 T ≈ 65.536 s (差不多)
-
N = 512,000 T ≈ 262.144 s (偏低)
-
N = 1,000,000 T ≈ 1,000 s (16分钟左右)
-
N = 10,000,000 time ≈ 100,000(27.7小时左右)
对比
| 倍率实验 | 幂次法则 |
|---|---|
| N =256,000 time ≈ 47.915 s (偏低) | N =256,000 T ≈ 65.536 s (差不多) |
| N = 512,000 time ≈ 177.2855 s (偏低) | N = 512,000 T ≈ 262.144 s (偏低) |
| N = 1,000,000 time ≈ 655.95 (11分钟左右) | N = 1,000,000 T ≈ 1,000 s (16分钟左右) |
| N = 10,000,000 time ≈ 122936.78 (34小时左右) | N = 10,000,000 time ≈ 100,000(27.7小时左右) |
这两种预测方式,对于这个算法的时间预测都是适用的。
Quick-Union算法
时间复杂度分析
find() 访问数组的次数是 1+访问触点所在深度的两倍
一个union() 有两个 find()+1
一个connected() 有两个find()
对于一组触点的连通最坏的访问次数是
N
2
N^2
N2
public class QuickUnion {
private int[] id;
private int count;
public QuickUnion(int N)
{
count = N;
id = new int[N];
for(int i = 0;i<N;i++)
{
id[i] = i;
}
}
public int size()
{
return count;
}
public boolean connected(int p, int q)
{
return find(p) == find(q);
}
public int find(int dot)
{
while(dot != id[dot]) dot = id[dot];
return dot;
}
public void union(int p, int q)
{
int pId = find(p);
int qId = find(q);
id[pId] = qId;
count--;
}
}
一般预测
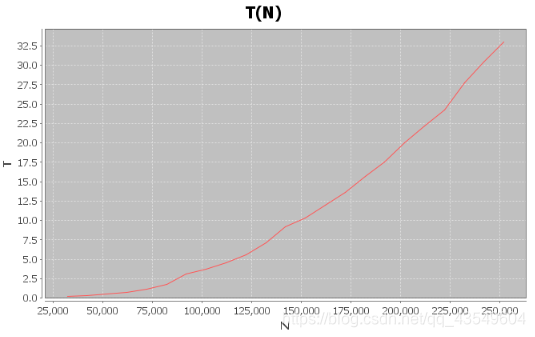
也差不多是二次函数的右边部分。
倍率实验
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DGBuqt9j-1593251570482)(C:\Users\肖沫\AppData\Roaming\Typora\typora-user-images\image-20200627142935308.png)]](https://img-blog.csdnimg.cn/20200627175548166.png)
N 0 = 64000 N_0=64000 N0=64000
b a s e T i m e = 1.3 s baseTime = 1.3s baseTime=1.3s
2 b = 5.1 2^b = 5.1 2b=5.1
预测
-
N = 256000 time ≈ 33.81 s(偏低)
-
N = 512000 time ≈ 172.44 s (偏低)
-
N = 1,000,000 time ≈ 879.47 s (15分钟左右)
-
N = 10,000,000 time ≈ 594983.27 s (7天左右)
幂次法则
实验数据
数据规模起点是132000 每次递增50000
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OLVzEouD-1593251570488)(C:\Users\肖沫\AppData\Roaming\Typora\typora-user-images\image-20200627161317222.png)]](https://img-blog.csdnimg.cn/20200627175559209.png)
对数图像
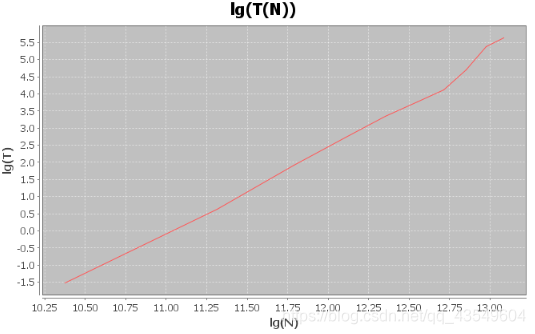
计算
l
g
(
T
(
N
)
)
=
k
l
g
(
N
)
+
l
g
(
a
)
①
lg(T(N)) = klg(N) + lg(a)①
lg(T(N))=klg(N)+lg(a)①
T = T ( N ) T = T(N) T=T(N)
看公式,我们的任务是算出 k 和 a.
根据上图 估算出斜率
k
=
3
k = 3
k=3
变化一下上面的①公式我们得到,书上也写的很明白,不难!
T
(
N
)
=
a
∗
N
k
②
T(N) = a*N^k②
T(N)=a∗Nk②
将实验数据里的(382000,110.83)和 k = 3代入②得
a
=
1.99
∗
1
0
−
15
a = 1.99*10^{-15}
a=1.99∗10−15
得到函数
T
=
1.99
∗
1
0
−
15
∗
N
3
T = 1.99*10^{-15}*N^3
T=1.99∗10−15∗N3
预测:
-
N = 256,000 time ≈ 33.3 s (差不多)
-
N = 512,000 time ≈267.09 s (偏低)
-
N = 1,000,000 time ≈1,988.2 s (33分钟左右)
-
N = 10,000,000 time ≈ 1,990,000 s (23天左右)
对比
| 倍率试验 | 幂次法则 |
|---|---|
| N = 256000 time ≈ 33.81 s(偏低) | N = 256,000 time ≈ 33.3 s (差不多) |
| N = 512000 time ≈ 172.44 s (偏低) | 512,000 time ≈267.09 s (偏低) |
| N = 1,000,000 time ≈ 879.47 s (15分钟左右) | 1,000,000 time ≈1,988.2 s (33分钟左右) |
| N = 10,000,000 time ≈ 594983.27 s (7天左右) | N = 10,000,000 time ≈ 1,990,000 s (23天左右) |
对于这个算法,倍率试验会比较合适。
而幂次法则得出的关于T,N的函数是立方级别的关系,这与最坏情况下的时间复杂度不符,所以偏差会很大!
加权Quick-Union算法
时间复杂度分析
find()访问数组的次数是 1+访问触点所在深度的两倍
一个union() 有两个 find()+1
一个connected() 有两个find()
这个加权union()机制保证了 含有N个结点的树的高度小于等于lg(N)
因为树的平均高度明显下降,所以保证了每次find() 访问数组的次数在一个较低的水平
所以整体的访问次数控制在了lg(N)
这样一下就将 平方级别降到了对数级别
public class WeightedQuickUnion {
private int[] id;
private int[] w;
private int count;
public WeightedQuickUnion(int N)
{
count = N;
id = new int[N];
w = new int[N];
for(int i = 0;i<N;i++)
{
id[i] = i;
w[i] = 1;
}
}
public int size()
{
return count;
}
public boolean connected(int p, int q)
{
return find(p) == find(q);
}
public int find(int dot)
{
while(dot != id[dot]) dot = id[dot];
return dot;
}
public void union(int p, int q)
{
int pId = find(p);
int qId = find(q);
if(w[qId]>w[pId])
{
id[pId] = qId;
w[qId] += w[pId];
}
else
{
id[qId] = pId;
w[pId] += w[qId];
}
count--;
}
}
数据图像
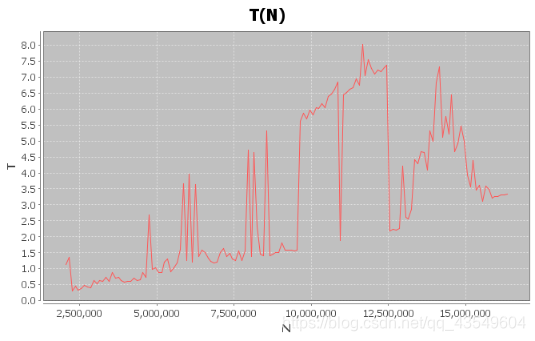
倍率实验
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fqSDnRVo-1593251570493)(C:\Users\肖沫\AppData\Roaming\Typora\typora-user-images\image-20200627143739239.png)]](https://img-blog.csdnimg.cn/20200627175657670.png)
读取
- N = 1,000,000 time ≈ 0.6 s
- N = 10,000,000 1.6 s< time < 3.3 s
问题
描述: 不管是用倍率试验还是幂次法则,算法一在处理大的数量级的数据的时候效率总是高于算法二。但是算法一的时间复杂度明显是平方级别,而算法二是在最坏的情况下时间复杂度才是平方级别。从实际的处理效率来看,算法二基本上都是优于算法一的。就从实验数据来看,这样的现象是符合时间复杂度关系的。
问题: 为什么,预测的结果不是算法二优于算法一呢?
小结
- 倍率实验对于算法的时间预测是比较可靠的
- 幂次法则的预测时间参考要和算法的时间复杂进行比较,如果幂次法则偏离时间复杂度很多,那么预测的结果同样存在很大的偏差,特别是在数据级很高的时候。
- 好的算法是如此的伟大
如果你想知道程序时间预测的理论分析,请看程序时间预测理论














 23万+
23万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









