







目录
0. 前言
本篇博客的代码来源于蘑菇书《Easy RL》Q学习部分的悬崖行走实战部分,本人在学习的同时对代码进行完整的解读,如有错误之处,烦请指正。
Easy-RL github :https://github.com/datawhalechina/easy-rl
注意,此为v.1.0.3分支
这部分代码有两个核心文件:
- qlearning.py
- task0.py
首先学习 task0 部分
1. 超参数
机器学习模型中一般有两类参数:一类需要从数据中学习和估计得到,称为模型参数(Parameter),即模型本身的参数。还有一类则是机器学习算法中的调优参数(tuning parameters),需要人为设定,称为超参数(Hyperparameter)。
class Config:
"""超参数
"""
def __init__(self):
################################## 环境超参数 ###################################
self.algo_name = 'Q-learning' # 算法名称,我们使用Q学习算法
self.env_name = 'CliffWalking-v0' # 环境名称,悬崖行走
self.device = torch.device(
"cuda" if torch.cuda.is_available() else "cpu") # 检测GPU,如果没装CUDA的话默认为CPU
self.seed = 10 # 随机种子,置0则不设置随机种子。我们学习过程中的随机值都对应着一个随机种子,方便我们复现学习结果
self.train_eps = 400 # 训练的回合数
self.test_eps = 30 # 测试的回合数
################################################################################
################################## 算法超参数 ###################################
self.gamma = 0.90 # 强化学习中的折扣因子
self.epsilon_start = 0.95 # ε-贪心策略中的初始epsilon,减小此值可减少学习开始时的随机探索几率
self.epsilon_end = 0.01 # ε-贪心策略中的终止epsilon,越小学习结果越逼近
self.epsilon_decay = 300 # e-greedy策略中epsilon的衰减率,此值越大衰减的速度越快
self.lr = 0.1 # 学习率
################################################################################
################################# 保存结果相关参数 ################################
self.result_path = curr_path + "/outputs/" + self.env_name + \
'/' + curr_time + '/results/' # 保存结果的路径
self.model_path = curr_path + "/outputs/" + self.env_name + \
'/' + curr_time + '/models/' # 保存模型的路径
self.save_fig = True # 是否保存图片,注意这里改为 save_fig
################################################################################
2. 训练
def train(cfg, env, agent):
print('开始训练!')
print(f'环境:{cfg.env_name}, 算法:{cfg.algo_name}, 设备:{cfg.device}')
rewards = [] # 记录每回合的奖励,用来记录并分析奖励的变化
ma_rewards = [] # 由于得到的奖励可能会产生振荡,使用一个滑动平均的量来反映奖励变化的趋势
# 开始回合训练
for i_ep in range(cfg.train_eps):
ep_reward = 0 # 记录每个回合的奖励
state = env.reset() # 重置环境,开始新的回合
# 开始当前回合的行走,直至走到终点
while True:
action = agent.choose_action(state) # 根据算法选择一个动作
next_state, reward, done, _ = env.step(action) # 与环境进行一次动作交互
agent.update(state, action, reward, next_state, done) # Q学习算法更新
state = next_state # 更新状态
ep_reward += reward
if done:
break
rewards.append(ep_reward)
if ma_rewards:
ma_rewards.append(ma_rewards[-1] * 0.9 + ep_reward * 0.1)
else:
ma_rewards.append(ep_reward)
print("回合数:{}/{},奖励{:.1f}".format(i_ep + 1, cfg.train_eps, ep_reward))
print('完成训练!')
return rewards, ma_rewards
2.1 初始化环境和智能体
def env_agent_config(cfg, seed=1):
"""创建环境和智能体
Args:
cfg ([type]): [description]
seed (int, optional): 随机种子. Defaults to 1.
Returns:
env [type]: 环境
agent : 智能体
"""
env = gym.make(cfg.env_name)
env = CliffWalkingWapper(env) # 使用自定义装饰器装饰环境
env.seed(seed) # 设置随机种子,每个种子对应一个随机结果,只是为了让结果可以精确复现,一般情况下可删去
n_states = env.observation_space.n # 状态维度,即 48 个状态
n_actions = env.action_space.n # 动作维度, 即 4 个动作
agent = QLearning(n_states, n_actions, cfg) # 为智能体设置参数
return env, agent
2.2 智能体选择动作
对于上述代码中的action = agent.choose_action(state)
其方法实现如下:
def choose_action(self, state):
self.sample_count += 1
self.epsilon = self.epsilon_end + (self.epsilon_start - self.epsilon_end) * \
math.exp(-1. * self.sample_count / self.epsilon_decay) # epsilon是会递减的,这里选择指数递减
# e-greedy 策略
if np.random.uniform(0, 1) > self.epsilon:
action = np.argmax(self.Q_table[str(state)]) # 选择Q(s,a)最大对应的动作
else:
action = np.random.choice(self.n_actions) # 随机选择动作
return action
此处使用的ε-贪心算法公式:

随着学习过程的增加,epsilon 会进行指数级衰减,直到逼近 epsilon_end。
在随机选择的数大于 epsilon ,即值在 1-epsilon 范围内时,选择Q(s,a)最大对应的动作。
现在,我们来尝试打印一下当前的状态:print(self.Q_table[str(state)])
输出结果为:[ -7.45800334 -78.37958986 -7.46127197 -7.48193639]
以上数组中的四个数值即为各个动作会产生的价值。
2.3 环境接收动作并反馈下一个状态和奖励
动作选择完后,我们使用此动作与环境进行一次交互:
next_state, reward, done, _ = env.step(action)
通过给定动作,我们可以从地图中得到下一个状态和奖励。
- 例如在起点格36执行动作UP=0,下一个状态为24,奖励为-1;
- 我们还需要设置地图的边界,例如在起点执行动作 LEFT=1,下一个状态还是36,奖励为−1W;
- 如果执行动作RIGHT=3,那么会掉入悬崖,下一个状态为36,奖励为 −100 。
具体的逻辑计算过程在C:\Python310\Lib\site-packages\gym\envs\toy_text\cliffwalking.py查看。
参数 done 用于判断是否抵达终点。
2.4 智能体进行策略更新(学习)
现在,我们得到了当前状态、选择的动作、奖励和下一个状态,就可以在智能体内使用Q学习算法更新Q表格:
agent.update(state, action, reward, next_state, done) # Q学习算法更新
方法实现如下:
def update(self, state, action, reward, next_state, done):
Q_predict = self.Q_table[str(state)][action] # 读取预测价值
if done: # 终止状态判断
Q_target = reward # 终止状态下获取不到下一个动作,直接将 Q_target 更新为对应的奖励
else:
Q_target = reward + self.gamma * np.max(self.Q_table[str(next_state)])
self.Q_table[str(state)][action] += self.lr * (Q_target - Q_predict)
其中涉及到的公式就是书中讲过的 Q学习的增量学习伪代码:
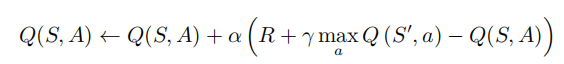
这样,就更新好了当前状态对应动作的价值,即策略更新。
3. 结果处理
在上文中,我们完成了一回合的学习,在每回合的学习结束后,我们需要将此回合的奖励记录下来,以便后续可视化使用:
rewards.append(ep_reward)
if ma_rewards:
ma_rewards.append(ma_rewards[-1] * 0.9 + ep_reward * 0.1)
else:
ma_rewards.append(ep_reward)
由于得到的奖励可能会产生振荡,我们使用一个滑动平均的量来反映奖励变化的趋势,即使用新的奖励与上一个奖励计算出一个平均的奖励加入到列表中。
3.1 模型保存
等到所有回合都执行结束后,保存这个训练好的模型:
make_dir(cfg.result_path, cfg.model_path) # 创建保存结果和模型路径的文件夹
agent.save(path=cfg.model_path) # 保存模型
save的实现:
def save(self, path):
import dill
torch.save(
obj=self.Q_table,
f=path + "Qlearning_model.pkl",
pickle_module=dill
)
print("保存模型成功!")
dill模块:https://pypi.org/project/dill/
dill extends python’s pickle module for serializing(序列化) and de-serializing(反序列化) python objects to the majority of the built-in python types. Serialization is the process of converting an object to a byte stream, and the inverse of which is converting a byte stream back to a python object hierarchy.
dill provides the user the same interface as the pickle module, and also includes some additional features. In addition to pickling python objects, dill provides the ability to save the state of an interpreter session in a single command. Hence, it would be feasable to save an interpreter session, close the interpreter, ship the pickled file to another computer, open a new interpreter, unpickle the session and thus continue from the ‘saved’ state of the original interpreter session.
我们用 pkl 文件(该存储方式,可以将python项目过程中用到的一些暂时变量、或者需要提取、暂存的字符串、列表、字典等数据保存起来)来保存这个训练好的模型,即 Q表格。打包的模块使用 dill模块。
torch.save()
保存一个序列化(serialized)的目标到磁盘。函数使用了Python的pickle程序用于序列化。模型(models),张量(tensors)和文件夹(dictionaries)都是可以用这个函数保存的目标类型。
3.2 模型读取
def load(self, path):
import dill
self.Q_table = torch.load(f=path + 'Qlearning_model.pkl', pickle_module=dill)
print("加载模型成功!")
与模型保存类似,使用torch.load()进行模型的读取操作,从而加载训练好的 Q表格。
3.3 模型测试
模型测试与训练的方法基本一致,唯一的区别只是不用再进行 Q表格的更新,即没有下面这行代码:
agent.update(state, action, reward, next_state, done) # Q学习算法更新














 4474
4474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









