









TensorFlow
一、TensorFlow基础
TensorFlow 使用 张量(Tensor) 作为基本数据单位。
相当于多维数组,可描述数学中的 标量 (0维数组), 向量(1维数组) , 矩阵(2维数组)
# 定义一个随机数(标量)
random_float = tf.random.uniform(shape=())
# 定义一个有2个元素的零向量
zero_vector = tf.zeros(shape=(2))
# 定义两个2×2的常量矩阵
A = tf.constant([[1., 2.], [3., 4.]])
B = tf.constant([[5., 6.], [7., 8.]])
- 张量 中的重要属性
- shape(): 形状
- dtpye(): 类型, 一般默认tf.float32
- numpy(): 值
# 查看矩阵A的形状、类型和值
print(A.shape) # 输出(2, 2),即矩阵的长和宽均为2
print(A.dtype) # 输出<dtype: 'float32'>
print(A.numpy()) # 输出[[1. 2.]
# [3. 4.]]
自动求导
引入tf.GradientTape()可实现自动求导
TensorFlow 的图像数据表示
在 TensorFlow 中,图像数据集的一种典型表示是[图像数目,长,宽,色彩通道数] 的四维张量。灰度图片色彩通道数为 1(可用np.expand_dims() 函数为图像数据手动在最后添加一维通道。),彩色 RGB 图像色彩通道数为 3.
二、TensorFlow模型建立与训练
- 模型构建:
tf.keras.Model和tf.kears.layers - 模型的损失函数:
tf.keras/losses - 模型的优化器:
tf.keras.optimizer - 模型的评估:
tf.keras.metrics
1. 模型(Model)与层(Layer)
构造模型时, 一般使用Keras,Keras :是基于 Python 的深度学习库,有两个重要的概念模型(Model)与层(Layer), 层封装了各种计算流程和变量, 如:全连接层, 卷积层,池化层; 模型则将各层连接起来, 描述了如何将输入数据通过各种层以及运算而得到输出。
自定义模型
可以通过继承tf.keras.Model类来定义自己的模型, 需要重写__init__()和call(input)两个方法。
class MyModel(tf.keras.Model):
def __init__(self):
super().__init__()
# 此处添加初始化代码(包含 call 方法中会用到的层),例如
# layer1 = tf.keras.layers.BuiltInLayer(...)
# layer2 = MyCustomLayer(...)
def call(self, input):
# 此处添加模型调用的代码(处理输入并返回输出),例如
# x = layer1(input)
# output = layer2(x)
return output
# 还可以添加自定义的方法

三、卷积神经网络(CNN)
卷积神经网络(Convolutional Neural Network)是一种结构类似于动物视觉系统的人工神经网络,包括一个或多个卷积层(Convolutional Layer), 池化层(Pooling Layer)和全连接层(Fully-connected Layer)
卷积层(Convolutional Layer)
tf.keras.layers.Conv2D
卷积层用卷积核来提取特征, 卷积核是一个矩阵。
从左上角开始,卷积核就对应着数据的3*3的矩阵范围,然后相乘再相加得出一个值。按照这种顺序,每隔一个像素就操作一次,我们就可以得出9个值。这九个值形成的矩阵被我们称作激活映射(Activation map)。

输入的图像一般为三维,即含有R、G、B三个通道。但其实经过一个卷积核之后,三维会变成一维。它在一整个屏幕滑动的时候,其实会把三个通道的值都累加起来,最终只是输出一个一维矩阵。
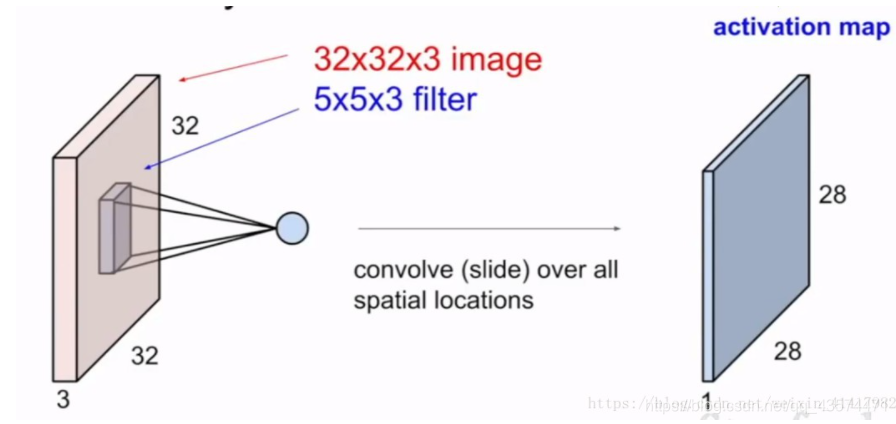
而多个卷积核(一个卷积层的卷积核数目是自己确定的)滑动之后形成的Activation Map堆叠起来,再经过一个激活函数就是一个卷积层的输出了。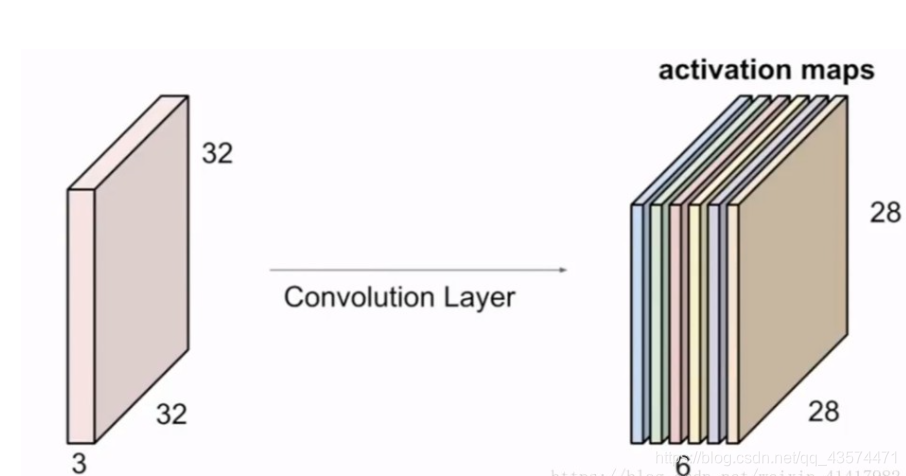
池化层 (pooling layer)
池化层的目的是降低参数,而降低参数的方法当然也只有删除参数了。
一般我们有最大池化和平均池化。池化层一般放在卷积层后面。所以池化层池化的是卷积层的输出!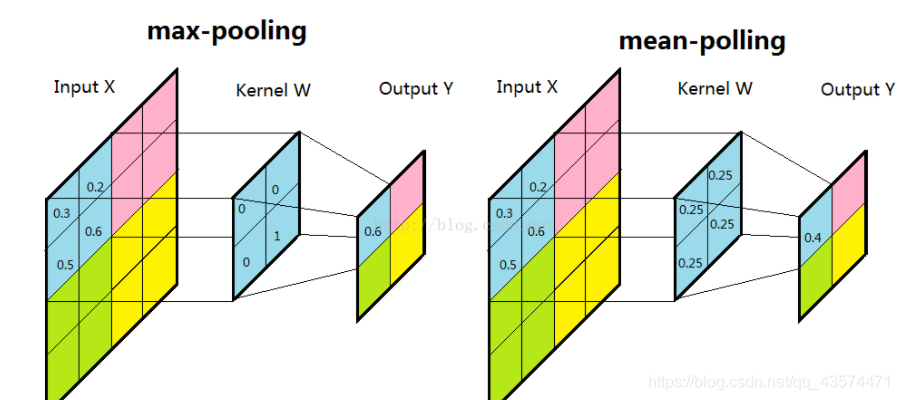
全连接层(Fully-connected Layer)
tf.keras.layer.Dense
全连接层是Keras 中最基础和最常用的层,其作用是对输入矩阵A 进行f(WA+b) 的线性变换+激活函数的操作(W*A+b为线性变换, f(x) 为激活函数)。若不指定激活函数,则视为只对输入矩阵进行线性变换。
对于输入张量input = [batch_size, input_dim], (batch_size:一次训练所选取的样本数; input_dim: 输入数据的维度), 全连接层首先对输入的张量进行tf.matmul(input, kernel) + bias的线性变换(kernel和bias是层中可训练的变量,kernel是权重矩阵, bias是偏置向量), 然后将变换后的张量的每个元素通过激活函数activation, 从而输出形状为
[batch_size, units]的二维张量(units输出张量的维度)。
四、简单网络
1、数据预处理
将数据图片数据输入到神经网络中,需要将数据格式化为经过处理的浮点数张量。已输入为JPEG格式的图片为例,处理步骤为:
1、读取图片文件
2、将图片解码为RGB像素网络或灰度网络
3、将像素网络转换为浮点数张量
4、将像素(0~255)缩放到[0, 1],便于神经网络处理
(1)读取图片文件
def read_image(paths):
filelist = []
for root, dirs, files in os.walk(paths):
for file in files:
if os.path.splitext(file)[1] == ".jpg":
filelist.append(os.path.join(root, file)) #路径拼接
return filelist
(2)将图片解码为RGB像素网络或灰度网络
from PIL import Image
im=Image.open(filename) #加载图片
im = im.resize((128, 128))# 修改图像大小为128*128
im_L=im.convert("RGB") # 模式RGB
用PIL中的Image对图片进行处理,
convert()方法是图像实例对象的一个方法,接受一个 mode 参数,用以指定一种色彩模式
mode的可选的值及其意义

(3)、(4)将像素网络转换为浮点数张量并缩放到[0, 1]
Core=im_L.getdata() # 返回图像模式
arr1=np.array(Core,dtype='float32')/255.0 # 缩放到【0,1】
2、数据增强
在进行学习的时候,如果样本数量过少,则会出现过拟合,导致无法训练出能够泛化到新数据的模型。
数据增强是从现有的训练样本中生成更多的训练数据,其方法是利用多种能够生成可信图像的随机变换(旋转,加入噪声,仿射变换)来增加(augment)样本。其目标是,模型在训练时不会两次查看完全相同的图像。这让模型能够观察到数据的更多内容,从而具有更好的泛化能力。
但是在深度学习的模型训练中,数据增强不能喧宾夺主,如果对每一张图片都加入高斯模糊的话实际上是毁坏了原来数据的特征。
python中常见的数据增强库,imgaug
首先读取二维的图像数据,记为images,images应该有四个维度,分别为(N,height,weidth,channels)就是图像数量,图像高度,图像宽度,图像的通道(RGB)。如果是灰度图的话,则channels为1。数据必须是uint8类型,大小在0到255之间。有了这个准备我们就可以对images中的图像数据进行增强了。
from imgaug import augmenters as iaa #引入数据增强的包
seq = iaa.Sequential([ #建立一个名为seq的实例,定义增强方法,用于增强
iaa.Crop(px=(0, 16)), #对图像进行截取操作,随机在距离边缘的0到16像素中选择截取范围
iaa.Fliplr(0.5), #对百分之五十的图像进行做左右翻转
iaa.GaussianBlur((0, 1.0)) #在模型上使用0均值1方差进行高斯模糊
])
images_aug = seq.augment_images(images) #应用数据增强
如果你使用数据增强来训练一个新网络,那么网络将不会两次看到同样的输入。但网络看到的输入仍然是高度相关的,因为这些输入都来自于少量的原始图像。你无法生成新信息,而只能混合现有信息。因此,这种方法可能不足以完全消除过拟合。为了进一步降低过拟合,你还需要向模型中添加一个dropout层,添加到密集连接分类器之前。
3、构建网络
from tensorflow.keras import layers, models
model = models.Sequential()
model.add(
layers.Conv2D(filters=32, # 卷积核的数目(即输出的维度)
kernel_size=(2, 2), # 卷积核的宽度和长度。如为单个整数,则表示在各个空间维度的相同长度
strides=1, # 为卷积的步长。如为单个整数,则表示在各个空间维度的相同步长。
activation='relu', # 激活函数
padding='same', # 补0策略,为“valid”, “same” 。
input_shape=(128, 128, 3))) # 张量输入
model.add(layers.MaxPooling2D((2, 2))) # 池化层
model.add(
layers.Conv2D(64, (2, 2), 1, activation='relu', padding='same'))
model.add(layers.MaxPooling2D((2, 2))) # 池化层
model.add(
layers.Conv2D(128, (2, 2), 1, activation='relu', padding='same'))
model.add(layers.MaxPooling2D((2, 2))) # 池化层
model.add(layers.Flatten()) # 降维
model.add(layers.Dropout(0.5)) # dropout层
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(len(dict_label), activation='softmax')) # 注意这里参数,我只有两类图片,所以是2.
model.summary() # 显示模型的架构
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
4、保存模型
简单粗暴 TensorFlow 2: https://tf.wiki/zh_hans/basic/models.html
batch_size: https://blog.csdn.net/qq_34886403/article/details/82558399
卷积层与池化层:https://blog.csdn.net/weixin_41417982/article/details/81412076
Python深度学习(在小型数据集上从头开始训练一个卷积神经网络)–学习笔记(十):https://blog.csdn.net/xiekengli8279/article/details/109583035














 4006
4006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









