









本篇文章结合这代码和图片进行多方面的讲解和呈现,细节的标识都以注释的形式展现,同样的,重点往往也是注释,有对比记忆点,也有一些理解的代换操作,目的是提高代码的健壮性和可读性。
引入
用汉尼塔引入栈的概念,做算法题的时候,三个ABC木桩就是栈的存放形式,拿取和放回根据入栈的顺序有关。
- 在三个ABC中,我们设定算法,hanita(A,B,C)从A转向B借用了C;
那么实现最大的盘子放置到C的前提是,将依次小的用B存放,那么就是首先让C是空的,B作为存放点。 - 那么第一句算法就是,hanita(A,C,B)借用C,将A中导向B,然后将第n个盘子放入C,执行移动操作move(a,n, c),
- 之后发现此时的B变成第一次操作前的A,那么第二次变换目的地是C,出发点是B。
- 那么就是hanita(B,A,C)借用空余的A.
在此基础上如果将柱子变成四个,hanita算法是没有问题的,主要是如何做到更少的迭代,那么就要使用

初始化:f[1] = 1(一个盘子在4塔模式下移动到D柱需要1步)
先把i个盘子在4塔模式下移动到B柱,
然后把n-i个盘子在3塔模式下移动到D柱(因为不能覆盖到B柱上,就等于只剩下A、C、D柱可以用)
最后把i个盘子在4塔模式下移动到D柱
考虑所有可能的i取最小值,即得到上述递推公式
int main() {
d[1] = 1;
for (int i = 2; i <= 12; i++)
d[i] = 2 * d[i - 1] + 1;
memset(f, 0x3f, sizeof(f));
f[1] = 1;
for (int i = 2; i <= 12; i++)
for (int j = 1; j < i; j++)
f[i] = min(f[i], 2 * f[j] + d[i - j]);
for (int i = 1; i <= 12; i++)
cout << f[i] << endl;
return 0;
}
#include <iostream>
#define maxsize 10
typedef int elemtype;
using namespace std;
typedef struct {
elemtype data[maxsize];
int top;
}sqstack;
void initstack(sqstack& s) {
s.top = -1;
}
void teststack() {
sqstack s;
initstack(s);
}
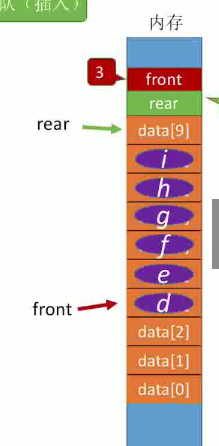
下面是对应功能的实现,重点是培养逻辑
//元素进站顺序栈的,top的初始化大小和maxsize
bool pushstack(sqstack& s, elemtype x) {
if (s.top == maxsize - 1) {
return false;
}
s.top = s.top + 1;
s.data[s.top] = x;
return true;//压进去,top往上移动一组s.data[++s.top]=x;
}
bool popstack(sqstack& s, elemtype& x) {
if (s.top == -1) {
return false;
}
x = s.data[s.top];//问题是只知道弹出的数据是多少,但是并没有清理
s.top = s.top - 1;
return true;
}
//共享栈
/*top0和top1 两个栈共享一片内存空间,两个栈从两边往中间增长
而且初始化的时候,只要top0=-1,1号栈在栈顶top1=maxsize;
当top0+1==top1的时候就满了*/
//在实际操作中stack的操作都可以直接使用库函数
//push pop gettop
//n个不同元素进出栈,元素的不同排列的个数为1/n+1Cn~2n,公式称为卡特兰数,可采用数学归纳法证明
栈和队列相比,因为是线性的,先进先出,先进后出,要对比记忆,在做题的时候可以直接在代码头带上#includeor其实就可以直接使用函数,但为了清楚内部的逻辑和一些特殊的情况,需要做到心里有底。
queue的优势是,它可以变成循环队列,就像在上篇文章中提到的循环链表,头尾结点链接在一起,相比如栈的固守成规,队列的循环效果往往更加动态。
//队列queue
typedef struct {
elemtype data[maxsize];
int front, rear;
int size;//rear=front=0,size=0;
}sqqueue;
void initqueue(sqqueue& q) {
q.front = q.rear=0;
q.size = 0;//delete size--;insert size++;
}
void testqueue() {
sqqueue q;
initqueue(q);
}
//队列单插
bool insertqueue(sqqueue& q, elemtype x) {
if ((q.rear+1)%maxsize==q.front) {
return false;
}
q.data[q.rear] = x;
q.rear = (q.rear + 1) % maxsize;//在
return true;
}
//判断是否pop干净 q.front==q.rear
//队列元素个数 (rear+maxsize-front)%maxsize;
//判断队列是否为空的另一种方法是通过struct 的特殊性
/*typedef struct {
elemtype data[maxsize];
int front, rear;
int tag;//每次删除成功的时候tag=0,插入成功之后为tag=1;
}sqqueue;
//所以结合队满队空的情况。front=rear&&tag==1是队伍满,且原因是插入了最后一个元素空间
//front=rear&&tag==0队伍空了,因为刚才删除了最后一个元素。
*/
//根据题目要求进行初始化的地方(n-1 0),(1 ,n )
根据链表和队列的相似点,我们可以整合出,队列的链式实现
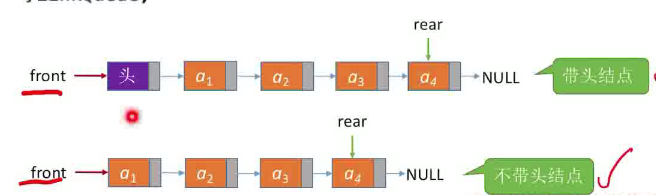
//队列的链式实现
typedef struct LinkNode {
elemtype data;
struct LinkNode* next;
}LinkNode;//还是建立的结点这次是叫链式的队列结点
typedef struct {
LinkNode* front, * rear;
}LinkQueue;//队列的队头和队尾
void initnodequeue(LinkQueue &q){
q.front = q.rear = (LinkNode*)malloc(sizeof(LinkNode));
q.front->next = NULL;
}
//讨论是否有头结点的问题,没有头结点的时候需要考虑入队的时候都是null的问题,它的next就会受到影响
void insertnodequeue(LinkQueue& q, elemtype x) {
LinkNode *s = (LinkNode*)malloc(sizeof(LinkNode));
s->data = x;
s->next = NULL;
if (q.front == NULL) {
q.front = s;
q.rear = s;//填补了之前的缺少
}
else {
q.rear->next = s;
q.rear = s;
}
//有头结点的话
s->data = x;
s->next = NULL;
q.front->next = s;
q.rear = s;//因为是模仿队列的链表所以都是前插。
}
bool dequeue(LinkQueue& q, elemtype& x) {
if (q.front == q.rear)
return false;
LinkNode* p = q.front->next;
x = p->data;
q.front->next = p->next;
if (q.rear == p) {
q.rear = q.front;//如果删除完就剩下一个,那么就移动rear和front
}
free(p);
return true;
//不带头结点
if (q.front == NULL) {
return false;
}
LinkNode* s = q.front;
x = s->data;
q.front = s->next;
if (q.rear == s) {
q.front = NULL;
q.rear = NULL;
}
free(s);
return true;
}
比较上面提到的三种储存方式,并且引入双端队列这里定义,它的发散性更强,对于数据的处理也就更方便
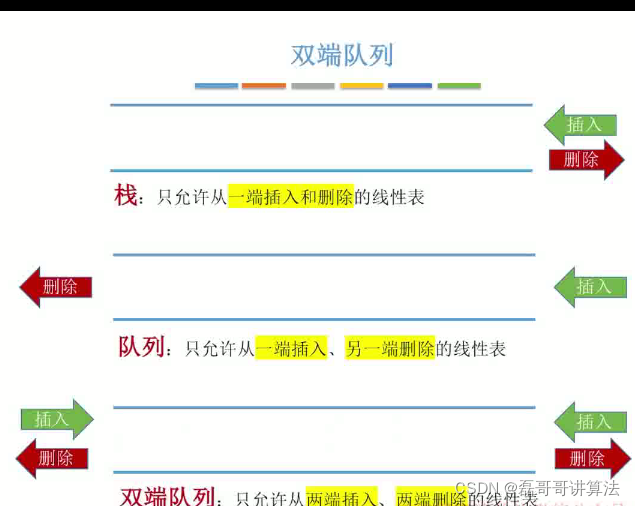
//普通队列会堆满,但是链式队列,可以无限加,只要是有next',下面引入双端队列
//括号匹配的问题用栈进行解决,遇到左括号就入栈,遇到右括号就消耗出栈
//运算表达式,更像是编译原理中的文法,通常用栈来进行这样的操作,逆波兰就是后缀表达式
//递归在某种程度上也是栈的原理
//数的层次遍历,也遵循了栈的原理,下面进行代码的操作实现。
//压缩存储,多维变成一维,矩阵通过三角矩阵减少空值的存储,散装矩阵,通过行列值,三项一维数组也可以存储
代码实现用栈的方法实现简单的表达式计算
使用的方法是将给的中缀表达式转换成后缀表达式,再进行计算
#include <iostream>
#include <string>
#include <cmath>
using namespace std;
//定义优先级: +,- ,* ,/ ,(,),#
//第一维表示栈内
char operate[7] = { '+','-','*','/','(',')','#' };
char prior[7][7] = {
{'>','>','<','<','<','>','>'}
,{'>','>','<','<','<','>','>'}
,{'>','>','>','>','<','>','>'}
,{'>','>','>','>','<','>','>'}
,{'<','<','<','<','<','=',' '}
,{'>','>','>','>',' ','>','>'}
,{'<','<','<','<','<',' ','!'}
};
//顺序栈
#define MAXSIZE 100
#define ERROR 0
#define OK 1
typedef double ElemTypeDouble;
typedef char ElemTypeChar;
//数字栈的结构
typedef struct {
ElemTypeDouble elem[MAXSIZE];
int top;
int stackSize;
}OPND;
//运算符栈的结构
typedef struct {
ElemTypeChar elem[MAXSIZE];
int top;
int stackSize;
}OPTR;
//初始化栈
int initStack(OPND& S) {
S.top = 0;
S.stackSize = MAXSIZE;
return OK;
}
int initStack(OPTR& S) {
S.top = 0;
S.stackSize = MAXSIZE;
return OK;
}
//压栈
int Push(OPND& S, ElemTypeDouble e) {
if (S.top >= S.stackSize) return ERROR;
S.elem[S.top++] = e;
return OK;
}
int Push(OPTR& S, ElemTypeChar e) {
if (S.top >= S.stackSize) return ERROR;
S.elem[S.top++] = e;
return OK;
}
//获取栈顶元素
int getTop(OPND& S, ElemTypeDouble& e) {
if (S.top == 0) return ERROR;
e = S.elem[S.top - 1];
return OK;
}
int getTop(OPTR& S, ElemTypeChar& e) {
if (S.top == 0) return ERROR;
e = S.elem[S.top - 1];
return OK;
}
//出栈
int Pop(OPND& S, ElemTypeDouble& e) {
if (S.top == 0) return ERROR;
e = S.elem[S.top - 1];
S.top--;
return OK;
}
int Pop(OPTR& S, ElemTypeChar& e) {
if (S.top == 0) return ERROR;
e = S.elem[S.top - 1];
S.top--;
return OK;
}
//获取表达式中的一个数字
double ex1(string str, int i, int& j) {
int num = 0;
int counter = 0;
while (str[i] >= '0' && str[i] <= '9' || str[i] == '.') {
if (str[i] == '.') counter = -1;
if (counter == 1) {
num = num * 10 + str[i] - '0';
counter = 1;
}
else if (counter == 0) {
num = str[i] - '0';
counter++;
}
else {
double t = str[i] - '0';
num = num + t * pow(10, counter);
counter--;
}
i++;
}
j = i;
return num;
}
//计算
double count(char ch, ElemTypeDouble eL, ElemTypeDouble eR) {
switch (ch) {
case '+':return eL + eR; break;
case '-':return eL - eR; break;
case '*':return eL * eR; break;
case '/':if (eR == 0)return 0;
else return eL / eR; break;
default: return 0; break;
}
}
//获取字符对应下标
int getIndex(char ch) {
for (int i = 0; i < 7; i++) {
if (ch == operate[i])
return i;
}return ERROR;
}
//判断字符是否为运算符
int IsOperate(char ch) {
for (int j = 0; j < 7; j++) {
if (ch == operate[j])return OK;
}
return ERROR;
}
//表达式求值
int EvalutionExpression(string str, ElemTypeDouble& result) {
int i;
ElemTypeChar ch;
ElemTypeDouble eR, eL;
int m, n;
OPTR S1;
OPND S2; //S1:运算符,S2:操作数
initStack(S1); //初始化
initStack(S2);
Push(S1, '#');
for (i = 0; str[i] != '\0'; i++);
str[i] = '#';
str[i + 1] = '\0';
i = 0;
getTop(S1, ch);
while (ch != '#' || str[i] != '#') {
//自左向右扫描str
if (IsOperate(str[i])) //判断str[i]是运算符
{ //是运算符 :与运算符栈的栈顶元素比较优先级
m = getIndex(ch);
n = getIndex(str[i]);
switch (prior[m][n])
{
case '>'://栈内的更高
if (!Pop(S2, eR)) return ERROR;
if (!Pop(S2, eL)) return ERROR;
Pop(S1, ch);
result = count(ch, eL, eR);
Push(S2, result);
getTop(S1, ch);
break;
case '<':
Push(S1, str[i]);
i++;
getTop(S1, ch);
break;
case '='://栈内是(,栈外是)
Pop(S1, ch);//(出栈
i++;
getTop(S1, ch);
break;
default: break;
}
}
else {//是操作数
ElemTypeDouble num;
int j = i;
double temp = ex1(str, i, j); //取出一个完整数字
Push(S2, temp);
getTop(S2, num);
i = j;
}
}
getTop(S1, ch);
if (ch == '#' && str[i] == '#') {
Push(S2, result);
}
return OK;
}
int main() {
string str;
ElemTypeDouble result = 0;
cout << "请输入表达式:" << endl;
cin >> str;
EvalutionExpression(str, result);
cout << "表达式的值为:" << endl;
cout << result << endl;
return 0;
}
上面的代码是表达式计算的实现比较繁琐,但是在逆波兰的转化和计算中,都可以逐条呈现出来
下面加入一个简单的算法实现,
当栈里没有运算符的时候,直接对栈顶和字符串读取到的运算符进行比较会出错,因此这里在一开始就往栈里压入了一个我们设计的符号'#'
当我们遍历字符串的时候,遇到数字要格外注意,因为此时一切都是字符形式了,比如说输入11就会变成两个字符1,因此我们在读取的时候要进行判断,确保所有连在一起的数字字符都读到了,而不是只读到了第一个字符。
当我们遍历完字符串的时候,很有可能栈里还留有没处理的运算符,因此我们需要继续处理栈里的操作符,这里在字符串后面加入了符号
//$是很巧妙的,\$的优先级比'#'高,比其他符号低,因此这保证了当读到字符\$时,它一定比栈顶出现的所有字符优先级高(除了它自己和'#'),这样就可以让栈里剩下的运算符一个一个弹出来,至到处理结束,栈顶为'\#',压入\$。
前提是同样要设定运算符的优先级,在压入栈中,数字直接进,遇到运算符,Leftnum Rightnum与operate计算,之后把三个数据的计算结果再压入栈。思路很简单,同时也缺少了对括号的判断和使用
就是简单压入弹出操作罢了
#include<bits/stdc++.h>
using namespace std;
const int N = 1e5+10;
stack<char> op;
stack<int> num;
void eval(){
auto b=num.top();num.pop();
auto a=num.top();num.pop();
auto c=op.top();op.pop();
int x;
if(c=='+')x=a+b;
else if(c=='-')x=a-b;
else if(c=='*')x=a*b;
else x=a/b;
num.push(x);
}
int main()
{
string s;cin>>s;
unordered_map<char,int> p{{'+',1},{'-',1},{'*',2},{'/',2}};
for(int i=0;i<s.size();i++){
if(isdigit(s[i])){
int j=i,x=0;
while(j<s.size()&&isdigit(s[j])){
x=x*10+s[j++]-'0';
}
num.push(x);
i=j-1;
}
else if (s[i]=='(')op.push(s[i]);
else if(s[i]==')'){
while(op.top()!='(')eval();
op.pop();
}
else{
while(op.size()&&op.top()!='('&&p[op.top()]>=p[s[i]])eval();
op.push(s[i]);
}
}
while(op.size())eval();
cout<<num.top()<<endl;
return 0;
}
本篇知识理论基础和两个实战应用结束了。come on















 1910
1910











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











