




 本文提出半监督语义分割框架U2PL,利用不可靠伪标签训练模型。通过预测熵分离可靠和不可靠像素,将不可靠像素视为负样本,自适应调整分区阈值。在PASCAL VOC 2012和Cityscapes数据集上实验,结果显示U2PL优于现有方法,尤其在标记数据有限时效果显著。
本文提出半监督语义分割框架U2PL,利用不可靠伪标签训练模型。通过预测熵分离可靠和不可靠像素,将不可靠像素视为负样本,自适应调整分区阈值。在PASCAL VOC 2012和Cityscapes数据集上实验,结果显示U2PL优于现有方法,尤其在标记数据有限时效果显著。
Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
使用不可靠的伪标签的半监督语义分割
Paper:https://openaccess.thecvf.com/content/CVPR2022/html/Wang_Semi-Supervised_Semantic_Segmentation_Using_Unreliable_Pseudo-Labels_CVPR_2022_paper.html
Code:https://github.com/Haochen-Wang409/U2PL/
Blog:https://haochen-wang409.github.io/U2PL/
Abstract
半监督语义分割的关键是为未标记图像的像素分配足够的伪标签。
常见的做法是选择高度置信的预测作为伪真实值,但这会导致大多数像素由于不可靠而可能未被使用的问题。我们认为每个像素对模型训练都很重要,即使它的预测是模糊的。直观上,不可靠的预测可能会在顶级类别(即具有最高概率的类别)之间混淆,但是,它应该对不属于其余类别的像素充满信心。
因此,这样的像素可以令人信服地被视为那些最不可能的类别的负样本。 基于这一见解,我们开发了一个有效的管道来充分利用未标记的数据。具体来说,我们通过预测熵分离可靠和不可靠的像素,将每个不可靠的像素推送到由负样本组成的按类别队列,并设法使用所有候选像素来训练模型。
考虑到训练的演变,预测变得越来越准确,我们自适应地调整可靠-不可靠分区的阈值。各种基准和训练设置的实验结果证明了我们的方法相对于最先进的替代方案的优越性。
1 Introduction
语义分割是计算机视觉领域的一项基本任务,并且随着深度神经网络的兴起而得到了显着的进步[7,30,36,47]。现有的监督方法依赖于大规模注释数据,而在实践中获取这些数据的成本可能太高。为了缓解这个问题,人们对半监督语义分割进行了许多尝试[1,4,11,17,23,34,44,49],它学习只有少量标记样本和大量未标记样本的模型。在这样的背景下,如何充分利用未标记的数据就变得至关重要。
典型的解决方案是为没有注释的像素分配伪标签。具体来说,给定未标记的图像,现有技术[28,42]借用基于标记数据训练的模型的预测,并使用像素级预测作为 “Ground Truth” 来反过来增强监督模型。为了减轻模型可能遭受不正确的伪标签的确认偏差问题 [2],现有方法建议使用其置信度分数来过滤预测 [43,44,51,52]。换句话说,只有高度置信的预测才被用作伪标签,而模糊的预测则被丢弃。
然而,仅使用可靠预测带来的一个潜在问题是,某些像素可能在整个训练过程中永远不会被学习到。 例如,如果模型不能令人满意地预测某些特定类别(例如 图 1 中的椅子),则很难为此类类别的像素分配准确的伪标签,这可能会导致训练不足且类别不平衡。从这个角度来看,我们认为,为了充分利用未标记的数据,每个像素都应该得到合理利用。
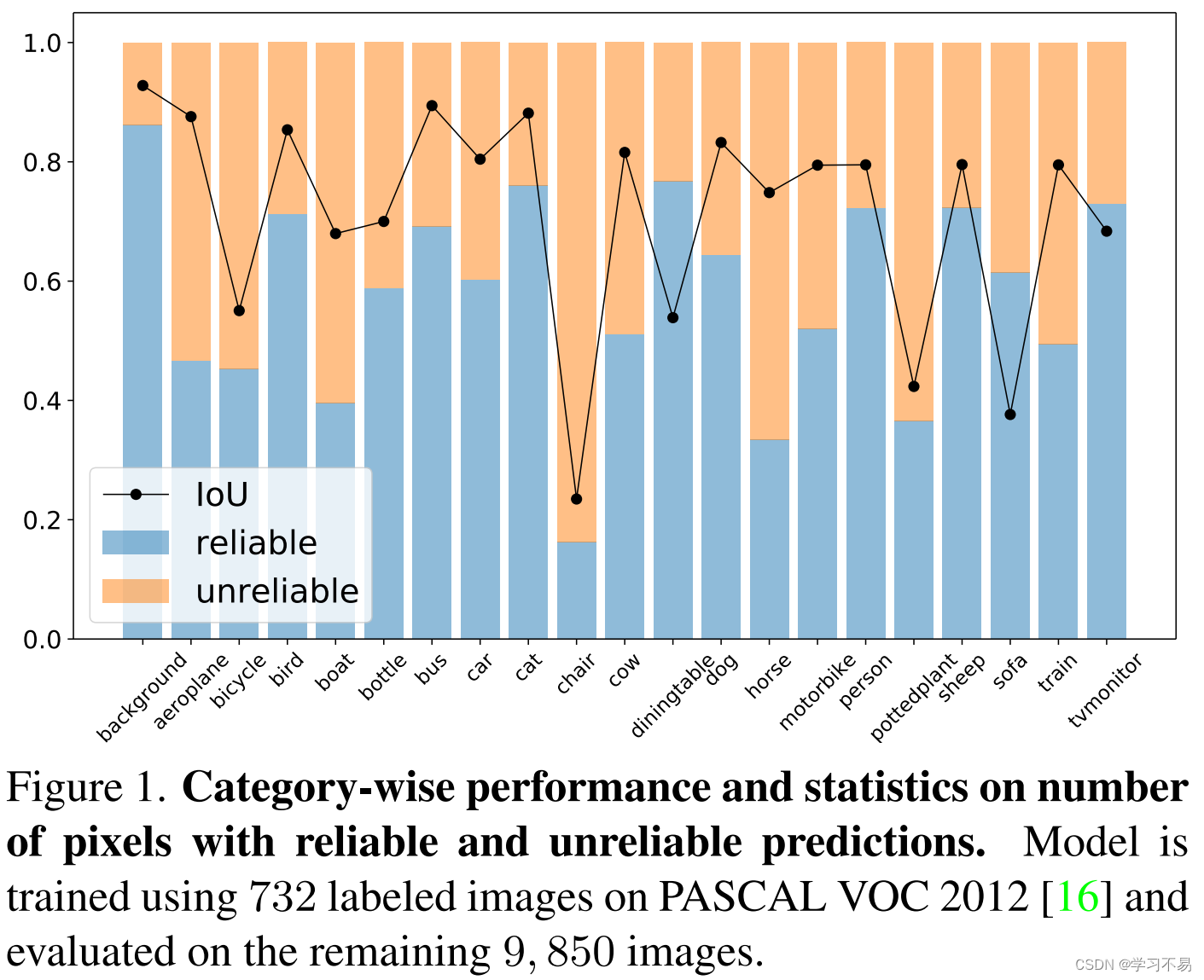
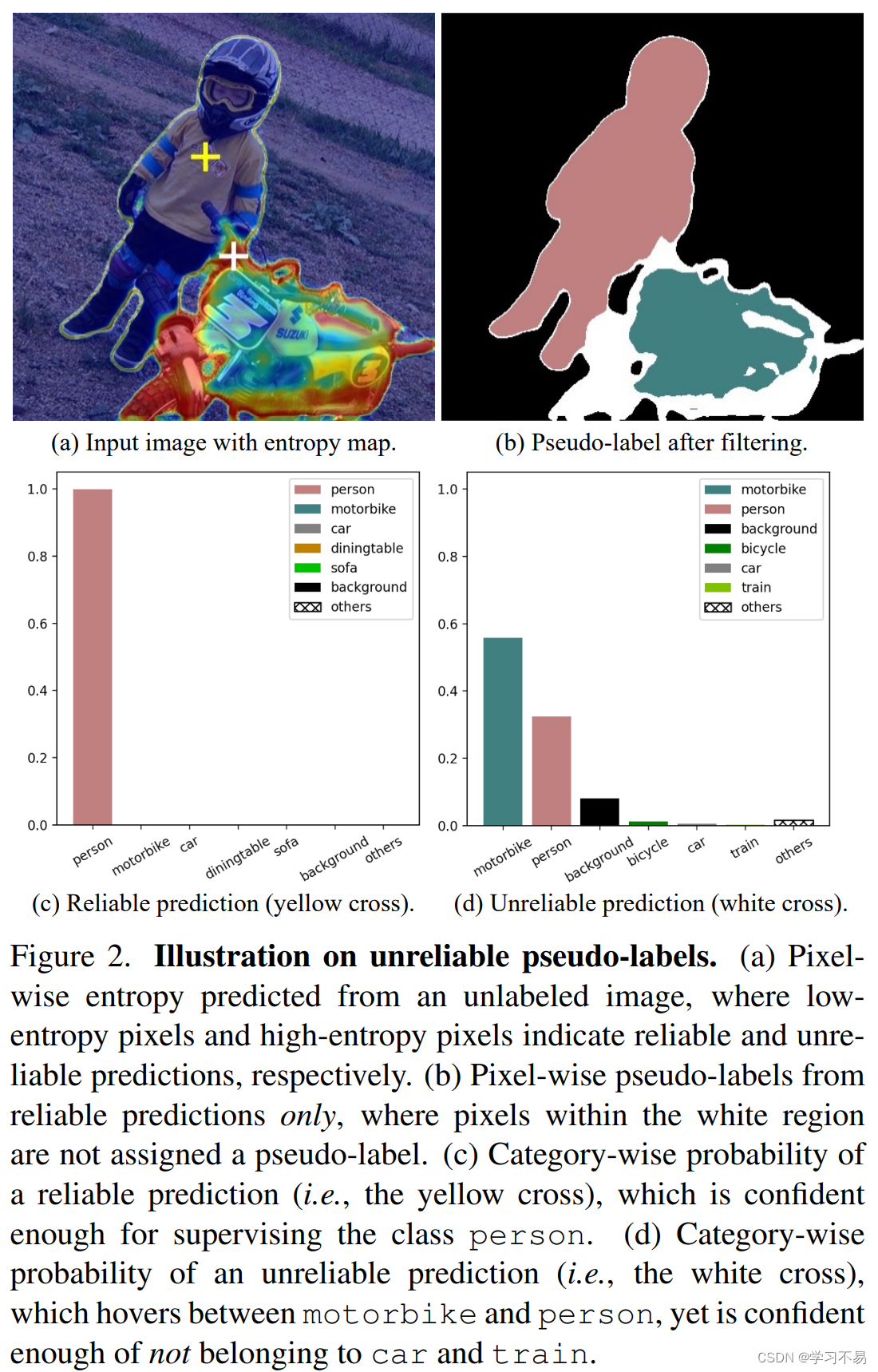
如上所述,直接使用不可靠的预测作为伪标签将导致性能下降[2]。在本文中,我们提出了一种使用不可靠伪标签的替代方法。我们将我们的框架称为 U 2 P L U^2PL U2PL。首先,我们观察到,不可靠的预测通常只会在少数类别而不是所有类别之间产生混淆。以图 2为例,带有白色十字的像素在摩托车和人类上获得相似的概率,但模型非常确定该像素不属于汽车和火车类。基于这一观察,我们重新将令人困惑的像素视为那些不太可能的类别的负样本。 具体来说,在从未标记的图像中获得预测后,我们采用每像素熵作为度量(见图 2)将所有像素分为两组,即可靠组和不可靠组。所有可靠的预测都用于导出正伪标签,而具有不可靠预测的像素则被推入充满负样本的内存库中。为了避免所有负面伪标签仅来自类别的子集,我们为每个类别使用一个队列。这样的设计保证了每个类的负样本数量是平衡的。 同时,考虑到随着模型越来越准确,伪标签的质量也越来越高,我们提出了一种自适应调整可靠和不可靠像素划分阈值的策略。
我们在广泛的训练环境下评估了 PASCAL VOC 2012 [16] 和 Cityscapes [12] 上提出的 U 2 P L U^2PL U2PL,我们的方法超越了最先进的竞争对手。此外,通过可视化分割结果,我们发现由于我们充分使用了不可靠的伪标签,我们的方法在那些模糊区域(例如不同对象之间的边界)上取得了更好的性能。
2 Related Work
半监督学习有两种典型范式:一致性正则化[3,17,34,37,43]和熵最小化[4,18]。最近,一种更直观但有效的框架:自我训练[28],已成为主流。几种方法[17,44,45]利用强大的数据增强,例如基于自训练的CutOut[15]、CutMix[46]和ClassMix[32]。然而,这些方法并没有过多关注语义分割的特征,而我们的方法则关注那些不可靠的像素,这些像素将被大多数基于自训练的方法过滤掉[35,44,45]。
伪标签用于防止在从教师网络生成输入图像的预测时过度拟合不正确的伪标签 [2, 28]。 FixMatch [38]利用置信度阈值来选择可靠的伪标签。 UPS[35]是一种基于FixMatch[38]的方法,考虑了模型不确定性和数据不确定性。然而,在半监督语义分割中,我们的实验表明,将不可靠的像素纳入训练中可以提高性能。
计算机视觉中的模型不确定性主要通过贝叶斯深度学习方法来测量[14,25,31]。在我们的设置中,我们并不关注如何衡量不确定性。我们简单地使用像素概率分布的熵作为度量。
对比学习被许多成功的自监督学习作品所应用[9,10,19]。在语义分割中,对比学习已成为一种有前途的新范式[1,29,41,48,50]。然而,这些方法忽略了半监督分割中常见的假阴性样本,并且不可靠的像素可能在对比损失中被错误地推开。区分不太可能的不可靠像素类别可以解决这个问题。
负学习旨在通过降低负样本的概率来降低错误信息的风险[26,27,35,40],但这些负样本的选择具有很高的置信度。换句话说,这些方法仍然利用具有可靠预测的像素。相比之下,我们建议充分利用那些不可靠的预测来进行学习,而不是过滤掉它们。
3 Method
在本节中,我们以数学方式建立我们的问题,并概述我们在第 2 节中提出的方法。 3.1
首先。我们关于过滤可靠伪标签的策略在第二节中介绍。 3.2.
最后,我们在第二节中描述了如何使用不可靠的伪标签。 3.3.
3.1 Overview
给定一个标记集 D l = { ( x i l , y i l ) } i = 1 N l \mathcal{D}_l = \left\{ (x^l_i,y^l_i) \right\}^{N_l}_{i=1} Dl={ (xil,yil)}i=1Nl 和一个更大的未标记集 D u = { x i u } i = 1 N u \mathcal{D}_u = \left\{ x^u_i \right\}^{N_u}_{i=1} Du={ xiu}i=1Nu,我们的目标是通过利用大量未标记集来训练语义分割模型数据和较小的一组标记数据。
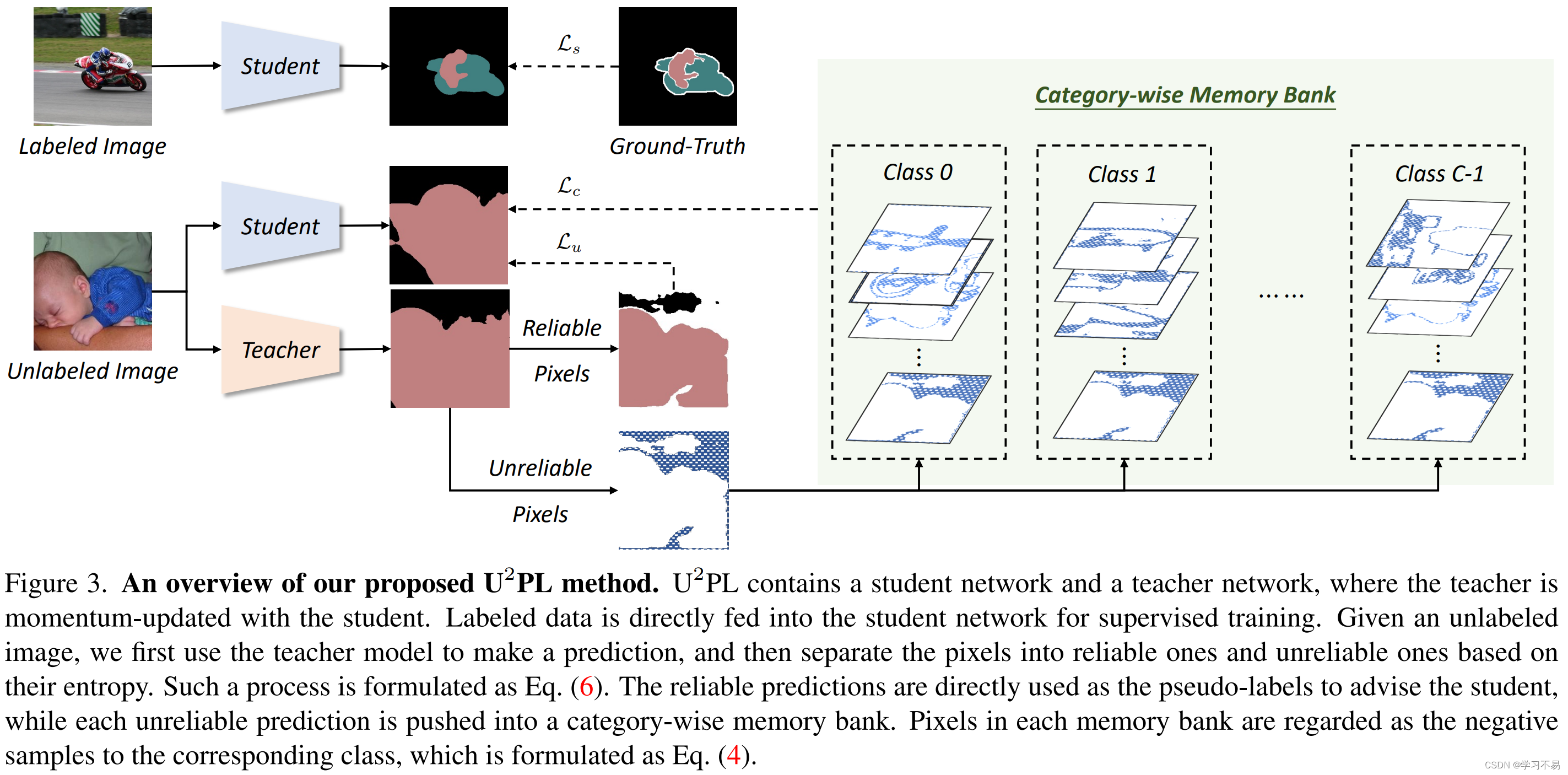
图 3 给出了 U 2 P L U^2PL U2PL 的概述,它遵循典型的自训练框架,具有相同架构的两个模型,分别称为教师和学生。这两个模型仅在更新权重时有所不同。学生模型的权重 θ s \theta_s θs 的更新与通常的做法一致,而教师模型的权重 θ t \theta_t θt 是由学生模型的权重更新的指数移动平均值 (EMA)。每个模型由一个基于 CNN 的编码器 h h h、一个带有分割头 f f f 的解码器和一个表示头 g g g 组成。在每个训练步骤中,我们对 B \mathcal{B} B 个标记图像 B l \mathcal{B}_l Bl 和 B \mathcal{B} B 个未标记图像 B u \mathcal{B}_u Bu 进行同等采样。对于每个标记图像,我们的目标是最小化等式(2)中的标准交叉熵损失。对于每张未标记的图像,我们首先将其带入教师模型并获得预测。然后,基于像素级熵,我们在计算等式(3)中的无监督损失时忽略不可靠的像素级伪标签。这部分内容将在第 3.2 节中详细介绍。最后,我们使用对比损失来充分利用无监督损失中排除的不可靠像素,这将在 Sec.3.3 中介绍。
我们的优化目标是最小化总体损失,可以表示为:
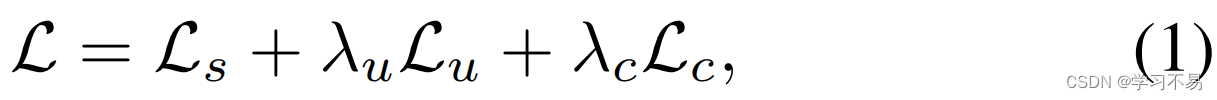
其中 L s \mathcal{L}_s Ls
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1672
1672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









