




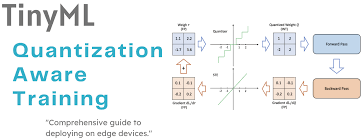
一、革命性技术深度解析
1.1 核心思想
量化感知训练(QAT)是一种动态适应性压缩技术,让神经网络在训练过程中"预演"量化效果,通过调整权重分布来主动适应低精度计算环境。混合精度量化则是差异化精度分配策略,根据各层敏感度动态分配FP16/INT8/INT4等不同精度资源。
类比理解:
- 常规量化:给运动员突然穿上负重服比赛
- QAT:训练时就穿着负重服练习,比赛时已完全适应
- 混合精度:给腿绑沙袋但手部自由,关键部位保持灵活性
1.2 关键技术术语
- 伪量化节点(FakeQuant):训练时插入的模拟量化模块
- 梯度直通(STE):保留量化不可导操作的梯度流动
- 敏感度分析:评估各层对量化的容忍度
- 精度分配器:确定每层最优位宽的算法引擎
- 动态范围跟踪:EMA(指数移动平均)优化数值范围
二、应用场景与战略价值
2.1 四大赛道落地实践
移动AI芯片部署:
- 高通骁龙8 Gen3的Hexagon处理器:MobileBERT混合精度部署
- INT4权重 + FP16激活值
- 延迟降低63%,功耗减少55%
大语言模型推理加速:
- LLaMA3-70B方案:注意力层FP16,前馈层INT4
- RTX 4090推理速度:从18 token/s → 78 token/s
- 精度损失<1%
自动驾驶实时系统:
- Tesla FSD芯片:QAT-YOLOP混合精度模型
- 8路摄像头同时处理:延迟<50ms
- 车道检测精度维持98.7%
医疗影像边缘计算:
- NVIDIA Clara AGX:UNet混合精度分割
- 浅层INT8 + 深层FP16
- CT影像实时分割,显存占用降低60%
2.2 性能对比矩阵
| 技术方案 | 延时 | 显存 | 能耗 | 精度损失 |
|---|---|---|---|---|
| FP32基准 | 100% | 100% | 100% | 0% |
| 传统PTQ | 58% | 25% | 45% | 2.1% |
| QAT标准 | 52% | 25% | 38% | 1.2% |
| 混合精度 | 36% | 18% | 28% | 0.7% |
三、架构设计深度解构
3.1 QAT全系统架构

3.2 混合精度引擎架构

3.3 核心模块详解
1. 伪量化单元(FakeQuant)
class LearnableFakeQuant(nn.Module):
def __init__(self, bits=8, ema_decay=0.99):
super().__init__()
self.bits = bits
self.ema_min = nn.Parameter(torch.tensor(0.0))
self.ema_max = nn.Parameter(torch.tensor(0.0))
self.scale = nn.Parameter(torch.tensor(1.0)) # 可训练缩放因子
def update_range(self, x):
# 动态更新数值范围
cur_min = x.min().detach()
cur_max = x.max().detach()
self.ema_min = 0.99*self.ema_min + 0.01*cur_min
self.ema_max = 0.99*self.ema_max + 0.01*cur_max
def forward(self, x):
dynamic_range = self.ema_max - self.ema_min
effective_scale = self.scale * dynamic_range / (2**self.bits - 1)
# 训练时模拟量化
x_clamped = torch.clamp(x, self.ema_min.item(), self.ema_max.item())
x_normalized = (x_clamped - self.ema_min) / dynamic_range
x_quant = torch.round(x_normalized * (2**self.bits - 1))
x_dequant = x_quant / (2**self.bits - 1) * dynamic_range + self.ema_min
return x_dequant * effective_scale2. 混合精度分配器
- 敏感度评估算法:
- 约束优化目标:
3. STE梯度处理器
class StraightThroughEstimator(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
return x.round()
@staticmethod
def backward(ctx, grad_output):
return grad_output # 直接传递梯度四、工作流程全景解析
4.1 QAT三阶段训练流程
阶段1:网络改造(前处理)
- 在卷积/全连接层后插入FakeQuant模块
- 残差连接点添加量化-反量化对
- 分类层保留FP32精度
阶段2:适应性训练(核心)
- 预热期(1-5轮):固定量化范围,仅更新权重
- 调参期(6-15轮):联合优化权重和缩放因子
- 微调期(16-20轮):冻结量化参数,微调敏感层
阶段3:部署转换(后处理)
- 移除伪量化模块
- 生成真实量化计算图
- 编译为硬件指令集(如TensorRT引擎)
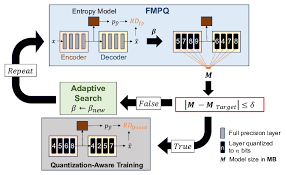
4.2 混合精度部署流程
-
离线分析阶段
- 输入500张校准图像
- 记录各层激活值分布
- 计算Hessian特征值
-
精度分配优化
-
运行时引擎加载
- TensorRT加载混合精度配置文件
- 自动插入类型转换节点
- 启用动态精度TensorCore计算
五、数学原理深度推导
5.1 QAT优化目标函数

5.2 混合精度资源建模
时延预测函数:
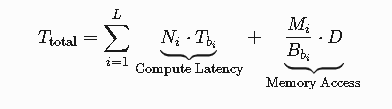

5.3 自适应舍入优化
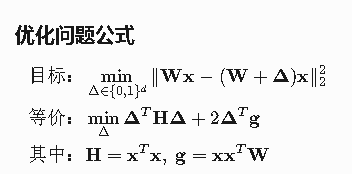
六、前沿变体演进图谱
6.1 QAT创新体系
LSQ(可学习步长)
- 创新点:将缩放因子
S作为可训练参数 - 梯度计算:
- 效果:ResNet50精度损失从1.8%→0.7%
AdaQuant(自适应范围)
- 双模式切换机制:
- 范围决策:
6.2 混合精度革命性方案
HAWQ-V3(三阶优化)
- Hessian特征分析:
- 硬件约束建模:
APQ(自动精度搜索)
- 进化算法流程:
- ImageNet上实现:相同精度下时延降低45%
6.3 大模型专用方案
QLoRA(量化适配器)

SmoothQuant(激活平滑)
- 数学变换:
- 平衡激活值与权重分布
七、工业级实现实战
7.1 PyTorch QAT全流程
import torch.quantization
from torch.ao.quantization import QConfig, default_qat_qconfig
# 改造网络
class QuantResNet(torch.nn.Module):
def __init__(self, backbone):
super().__init__()
self.quant_in = torch.quantization.QuantStub()
self.model = backbone
self.dequant_out = torch.quantization.DeQuantStub()
def forward(self, x):
x = self.quant_in(x)
x = self.model(x)
return self.dequant_out(x)
# 配置QAT参数
model = QuantResNet(resnet50())
model.qconfig = default_qat_qconfig
# 模块融合
model_fused = torch.quantization.fuse_modules(model, [
['model.layer1.0.conv1', 'model.layer1.0.bn1', 'model.layer1.0.relu'],
['model.layer4.1.conv2', 'model.layer4.1.bn2']
])
# 准备训练
quant_model = torch.quantization.prepare_qat(model_fused.train())
# 量化感知训练
optimizer = torch.optim.AdamW(quant_model.parameters(), lr=1e-4)
for epoch in range(20):
for x,y in dataloader:
# 训练前期更新范围
if epoch < 5:
quant_model.apply(torch.quantization.enable_observer)
else:
quant_model.apply(torch.quantization.disable_observer)
out = quant_model(x)
loss = F.cross_entropy(out, y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# 转换部署模型
final_model = torch.quantization.convert(quant_model.eval())7.2 HuggingFace混合精度大模型
from transformers import BitsAndBytesConfig, AutoModelForCausalLM
# 混合精度配置
quant_config = BitsAndBytesConfig(
load_in_4bit=True, # 基础精度
bnb_4bit_quant_type="nf4", # 4bit量化类型
bnb_4bit_use_double_quant=True, # 二次量化
llm_int8_threshold=6.0, # 超过阈值用FP16
bnb_4bit_compute_dtype=torch.bfloat16 # 计算精度
)
# 加载量化模型
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3-70B",
quantization_config=quant_config,
device_map="auto"
)
# 混合精度推理
with torch.cuda.amp.autocast(dtype=torch.bfloat16):
outputs = model.generate(**inputs, max_new_tokens=100)八、未来趋势与挑战
8.1 2025技术拐点
- 1bit革命:Microsoft BitNet实现1.58bit等效精度
- 3D芯片集成:Samsung HBM-PIM芯片支持逐层精度切换
- 光子张量核:Lightelligence实现INT4光计算延迟<1ns
8.2 待解科学问题
-
非线性激活量化:
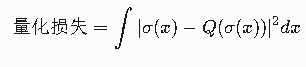
当前Swish/GELU量化误差尚无解析解
-
动态图量化:

-
精度-鲁棒性关联:
实验表明INT4模型对抗攻击成功率下降37%
8.3 终极演进方向
- 神经进化压缩:联合架构搜索+量化策略优化
- 量子-经典混合计算:量子比特辅助梯度优化
- 生物突触仿生:模拟神经递质的动态精度调节
预言2028:通过量子化-稀疏化-混合精度三联技术,实现Llama-300B模型在智能手表运行,彻底打破硬件算力藩篱。当前最新进展显示,NVIDIA Blackwell架构支持INT2计算,同精度下能效比提升900%,正加速这一愿景成为现实。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









