




经典卷积神经网络
LeNet-5 60k参数。网络基本架构为:conv1 (6) -> pool1 -> conv2 (16) -> pool2 -> fc3 (120) -> fc4 (84) -> fc5 (10) -> softmax。括号中的数字代表通道数,网络名称中有5表示它有5层conv/fc层。当时,LeNet-5被成功用于ATM以对支票中的手写数字进行识别。LeNet取名源自其作者姓LeCun。
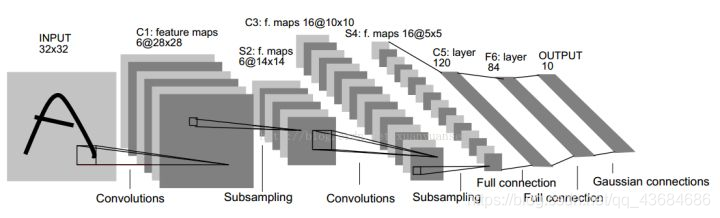
AlexNet 60M参数,ILSVRC 2012的冠军网络。网络基本架构为:conv1 (96) -> pool1 -> conv2 (256) -> pool2 -> conv3 (384) -> conv4 (384) -> conv5 (256) -> pool5 -> fc6 (4096) -> fc7 (4096) -> fc8 (1000) -> softmax。AlexNet有着和LeNet-5相似网络结构,但更深、有更多参数。conv1使用11×11的滤波器、步长为4使空间大小迅速减小(227×227 -> 55×55)。AlexNet的关键点是:(1). 使用了ReLU激活函数,使之有更好的梯度特性、训练更快。(2). 使用了随机失活(dropout)。(3). 大量使用数据扩充技术。AlexNet的意义在于它以高出第二名10%的性能取得了当年ILSVRC竞赛的冠军,这使人们意识到卷积神经网络的优势。此外,AlexNet也使人们意识到可以利用GPU加速卷积神经网络训练。AlexNet取名源自其作者名Alex。
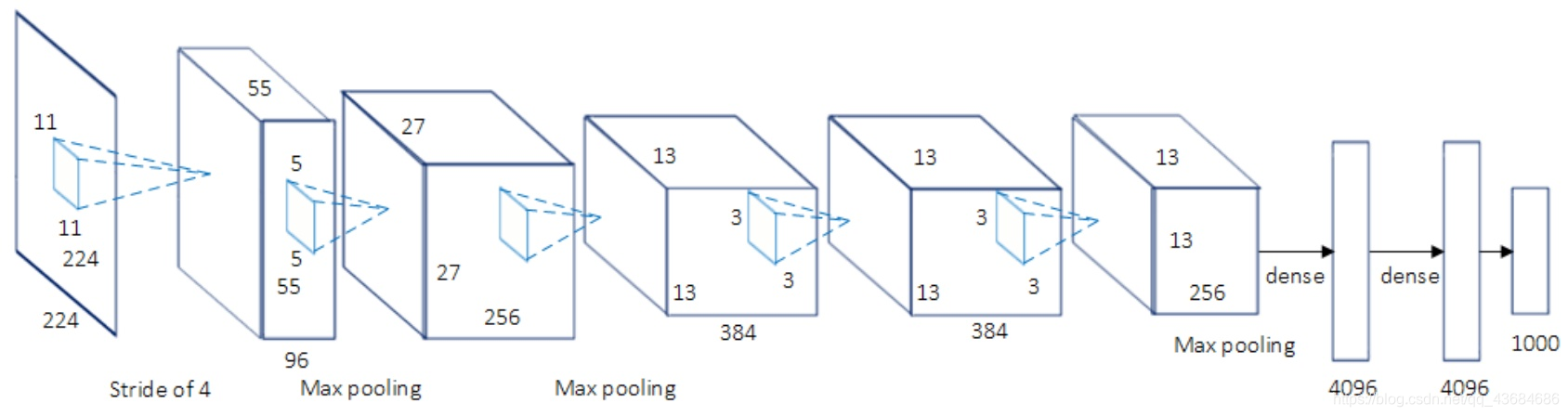
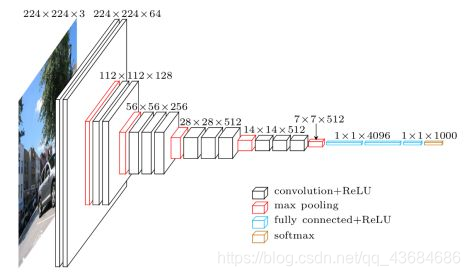
VGG-16/VGG-19 138M参数,ILSVRC 2014的亚军网络。VGG-16的基本架构为:conv1^2 (64) -> pool1 -> conv2^2 (128) -> pool2 -> conv3^3 (256) -> pool3 -> conv4^3 (512) -> pool4 -> conv5^3 (512) -> pool5 -> fc6 (4096) -> fc7 (4096) -> fc8 (1000) -> softmax。 ^3代表重复3次。VGG网络的关键点是:(1). 结构简单,只有3×3卷积和2×2汇合两种配置,并且重复堆叠相同的模块组合。卷积层不改变空间大小,每经过一次汇合层,空间大小减半。(2). 参数量大,而且大部分的参数集中在全连接层中。网络名称中有16表示它有16层conv/fc层。(3). 合适的网络初始化和使用批量归一(batch normalization)层对训练深层网络很重要。在原论文中无法直接训练深层VGG网络,因此先训练浅层网络,并使用浅层网络对深层网络进行初始化。在BN出现之后,伴随其他技术,后续提出的深层网络可以直接得以训练。VGG-19结构类似于VGG-16,有略好于VGG-16的性能,但VGG-19需要消耗更大的资源,因此实际中VGG-16使用得更多。由于VGG-16网络结构十分简单,并且很适合迁移学习,因此至今VGG-16仍在广泛使用。VGG-16和VGG-19取名源自作者所处研究组名(Visual Geometry Group)。
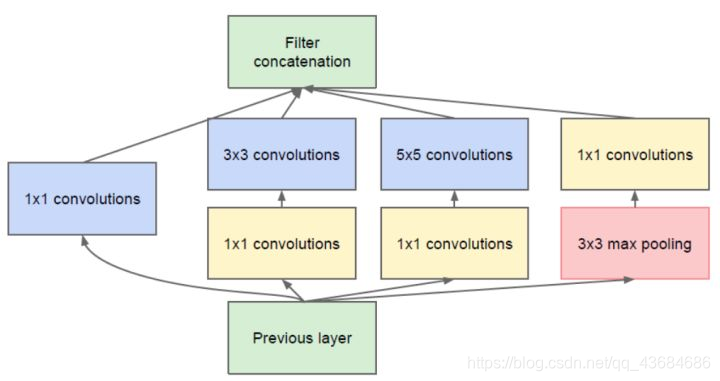
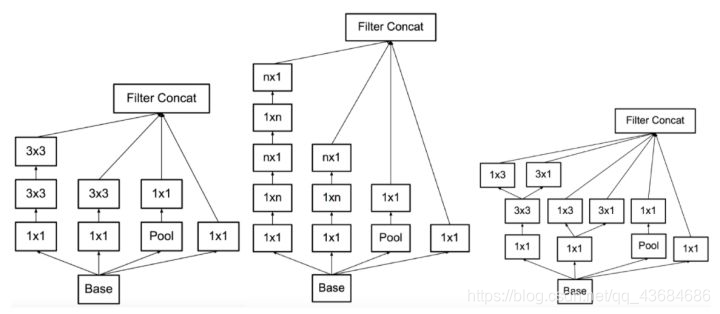
GoogLeNet 5M参数,ILSVRC 2014的冠军网络。GoogLeNet试图回答在设计网络时究竟应该选多大尺寸的卷积、或者应该选汇合层。其提出了Inception模块,同时用1×1、3×3、5×5卷积和3×3汇合,并保留所有结果。网络基本架构为:conv1 (64) -> pool1 -> conv2^2 (64, 192) -> pool2 -> inc3 (256, 480) -> pool3 -> inc4^5 (512, 512, 512, 528, 832) -> pool4 -> inc5^2 (832, 1024) -> pool5 -> fc (1000)。GoogLeNet的关键点是:(1). 多分支分别处理,并级联结果。(2). 为了降低计算量,用了1×1卷积降维。GoogLeNet使用了全局平均汇合替代全连接层,使网络参数大幅减少。GoogLeNet取名源自作者所处单位(Google),其中L大写是为了向LeNet致敬,而Inception的名字来源于盗梦空间中的"we need to go deeper"梗。
Inception v3/v4 在GoogLeNet的基础上进一步降低参数。其和GoogLeNet有相似的Inception模块,但将7×7和5×5卷积分解成若干等效3×3卷积,并在网络中后部分把3×3卷积分解为1×3和3×1卷积。这使得在相似的网络参数下网络可以部署到42层。此外,Inception v3使用了批量归一层。Inception v3是GoogLeNet计算量的2.5倍,而错误率较后者下降了3%。Inception v4在Inception模块基础上结合了residual模块(见下文),进一步降低了0.4%的错误率。
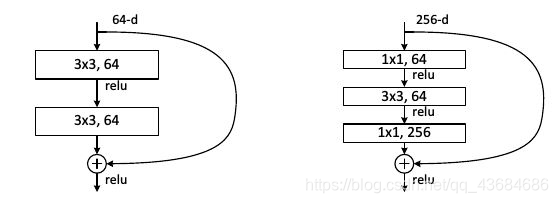
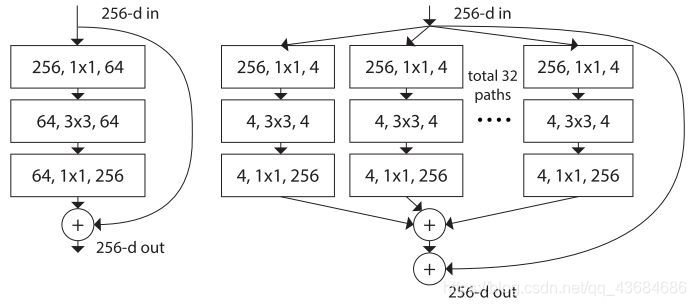
ResNet ILSVRC 2015的冠军网络。ResNet旨在解决网络加深后训练难度增大的现象。其提出了residual模块,包含两个3×3卷积和一个短路连接(左图)。短路连接可以有效缓解反向传播时由于深度过深导致的梯度消失现象,这使得网络加深之后性能不会变差。短路连接是深度学习又一重要思想,除计算机视觉外,短路连接也被用到了机器翻译、语音识别/合成领域。此外,具有短路连接的ResNet可以看作是许多不同深度而共享参数的网络的集成,网络数目随层数指数增加。ResNet的关键点是:(1). 使用短路连接,使训练深层网络更容易,并且重复堆叠相同的模块组合。(2). ResNet大量使用了批量归一层。(3). 对于很深的网络(超过50层),ResNet使用了更高效的瓶颈(bottleneck)结构(右图)。ResNet在ImageNet上取得了超过人的准确率。
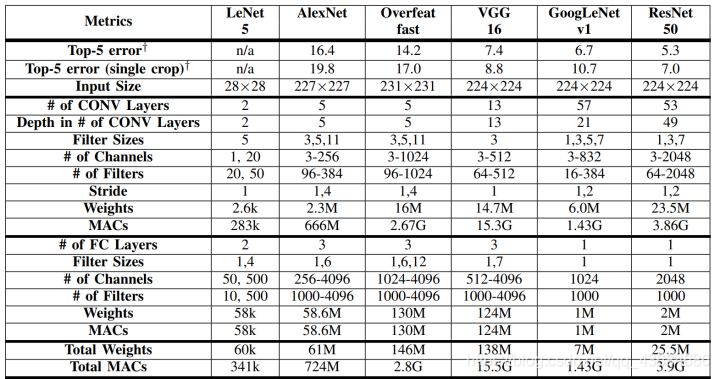
下图对比了上述几种网络结构。
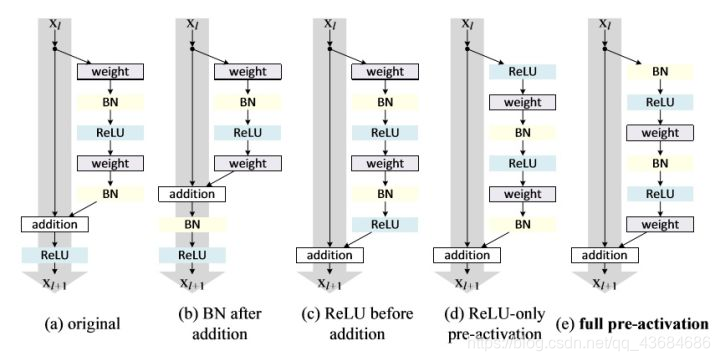
preResNet ResNet的改进。preResNet整了residual模块中各层的顺序。相比经典residual模块(a),(b)将BN共享会更加影响信息的短路传播,使网络更难训练、性能也更差;©直接将ReLU移到BN后会使该分支的输出始终非负,使网络表示能力下降;(d)将ReLU提前解决了(e)的非负问题,但ReLU无法享受BN的效果;(e)将ReLU和BN都提前解决了(d)的问题。preResNet的短路连接(e)能更加直接的传递信息,进而取得了比ResNet更好的性能。
ResNeXt ResNet的另一改进。传统的方法通常是靠加深或加宽网络来提升性能,但计算开销也会随之增加。ResNeXt旨在不改变模型复杂度的情况下提升性能。受精简而高效的Inception模块启发,ResNeXt将ResNet中非短路那一分支变为多个分支。和Inception不同的是,每个分支的结构都相同。ResNeXt的关键点是:(1). 沿用ResNet的短路连接,并且重复堆叠相同的模块组合。(2). 多分支分别处理。(3). 使用1×1卷积降低计算量。其综合了ResNet和Inception的优点。此外,ResNeXt巧妙地利用分组卷积进行实现。ResNeXt发现,增加分支数是比加深或加宽更有效地提升网络性能的方式。ResNeXt的命名旨在说明这是下一代(next)的ResNet。
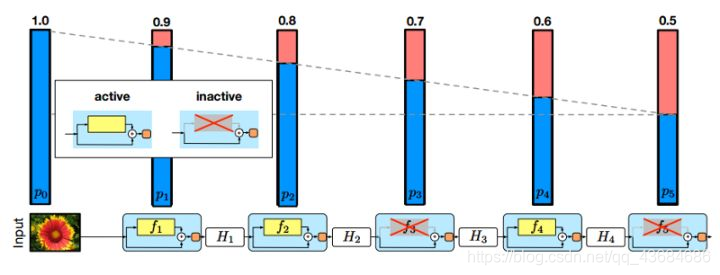
随机深度 ResNet的改进。旨在缓解梯度消失和加速训练。类似于随机失活(dropout),其以一定概率随机将residual模块失活。失活的模块直接由短路分支输出,而不经过有参数的分支。在测试时,前馈经过全部模块。随机深度说明residual模块是有信息冗余的。
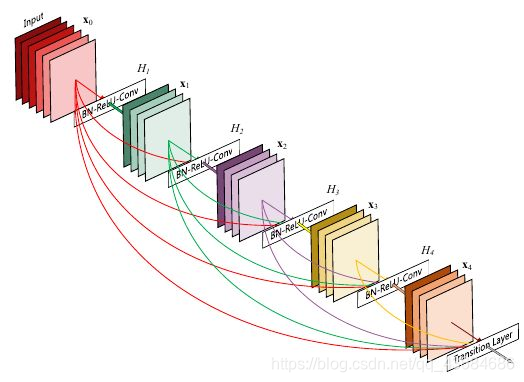
DenseNet 其目的也是避免梯度消失。和residual模块不同,dense模块中任意两层之间均有短路连接。也就是说,每一层的输入通过级联(concatenation)包含了之前所有层的结果,即包含由低到高所有层次的特征。和之前方法不同的是,DenseNet中卷积层的滤波器数很少。DenseNet只用ResNet一半的参数即可达到ResNet的性能。实现方面,作者在大会报告指出,直接将输出级联会占用很大GPU存储。后来,通过共享存储,可以在相同的GPU存储资源下训练更深的DenseNet。但由于有些中间结果需要重复计算,该实现会增加训练时间。
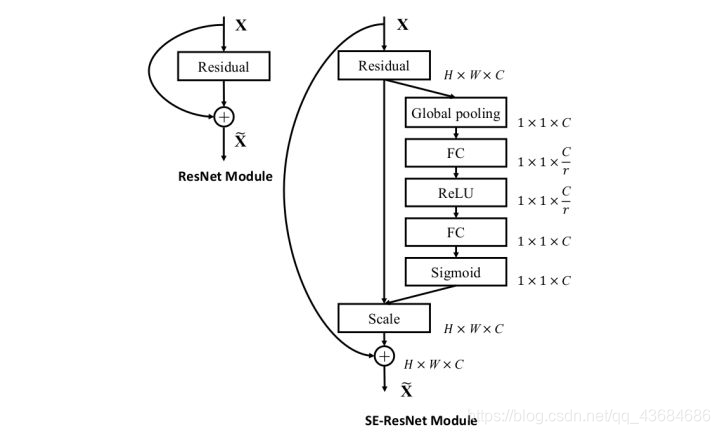
SENet ILSVRC 2017的冠军网络。SENet通过额外的分支(gap-fc-fc-sigm)来得到每个通道的[0, 1]权重,自适应地校正原各通道激活值响应。以提升有用的通道响应并抑制对当前任务用处不大的通道响应。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









