






内容: 记录Nginx解决惊群的方式
惊群:
如果多个工作进程同时拥有某个监听套接口,那么一旦该套接口出现某客户端请求,此时就将引发所有拥有该套接口的
工作进程去争抢这个请求,能争抢到的肯定只有某一个工作进程,其它进程的这一次上下文切换就白作了,这种现象即为“惊群”。
解决惊群方法一:上锁
//上锁的判断条件:
//必须满足两个条件:worker进程大于1,且配置文件中打开了这个选项
if (ccf->master && ccf->worker_processes > 1 && ecf->accept_mutex) {
ngx_use_accept_mutex = 1;
ngx_accept_mutex_held = 0;
ngx_accept_mutex_delay = ecf->accept_mutex_delay;
} else {
ngx_use_accept_mutex = 0;
}
void ngx_process_events_and_timers(ngx_cycle_t *cycle)
{
//ngx_use_accept_mutex表示是否需要通过对accept加锁来解决惊群问题。
//当nginx worker进程数>1时且配置文件中打开 accept_mutex时,这个标志置为1
if (ngx_use_accept_mutex) {
//我们在nginx.conf曾经配置了每一个nginx worker进程能够处理的最大连接数,当达到最大数的7/8时;
//ngx_accept_disabled为正,说明本nginx worker进程非常繁忙,将不再去处理新连接
if (ngx_accept_disabled > 0) {
ngx_accept_disabled--; //而是开始做ngx_accept_disabled--
} else {
//获得accept锁,多个worker仅有一个可以得到这把锁。获得锁不是阻塞过程,都是立刻返回,获取成功的话
//ngx_accept_mutex_held被置为1,拿到锁;意味着监听句柄被放到本进程的epoll中了,如果没有拿到锁,
//则监听句柄会被从epoll中取出。
if (ngx_trylock_accept_mutex(cycle) == NGX_ERROR) {
return;
}
//拿到锁的话,置flag为NGX_POST_EVENTS,这意味着ngx_process_events函数中,任何事件都将延后处理;
//会把accept事件都放到ngx_posted_accept_events链表中,epollin|epollout事件都放到
//ngx_posted_events链表中
if (ngx_accept_mutex_held) {
flags |= NGX_POST_EVENTS;
} else {
//拿不到锁,也就不会处理监听的句柄,这个timer实际是传给epoll_wait的超时时间,修改为最大
//ngx_accept_mutex_delay意味着epoll_wait更短的超时返回,以免新连接长时间没有得到处理
if (timer == NGX_TIMER_INFINITE
|| timer > ngx_accept_mutex_delay)
{
timer = ngx_accept_mutex_delay;
}
}
}
}
//linux下,调用ngx_epoll_process_events函数开始处理,延迟处理队列元素也是在这里加入的
(void) ngx_process_events(cycle, timer, flags);
//如果ngx_posted_accept_events链表有数据,就开始accept建立新连接
if (ngx_posted_accept_events) {
ngx_event_process_posted(cycle, &ngx_posted_accept_events);
}
//释放锁后再处理下面的EPOLLIN EPOLLOUT请求
if (ngx_accept_mutex_held) {
ngx_shmtx_unlock(&ngx_accept_mutex);
}
if (delta) {
ngx_event_expire_timers();
}
ngx_log_debug1(NGX_LOG_DEBUG_EVENT, cycle->log, 0,
"posted events %p", ngx_posted_events);
//然后再处理正常的数据读写请求。因为这些请求耗时久,所以在ngx_process_events里
//NGX_POST_EVENTS标志将事件都放入ngx_posted_events链表中,延迟到锁释放了再处理。
//这里也是为了优化锁的占用,如果等所有事件循环处理完后,那么明显对锁占用时间太长了,影响其它
//进程取锁,也影响新连接的建立
if (ngx_posted_events) {
if (ngx_threaded) {
ngx_wakeup_worker_thread(cycle);
} else {
ngx_event_process_posted(cycle, &ngx_posted_events);
}
}
}
无论有多少个nginx worker进程,同一时刻只能有一个worker进程在自己的epoll中加入监听的句柄。这个处理accept
的nginx worker进程置flag为NGX_POST_EVENTS,这样它在接下来的ngx_process_events函数(在linux中就是
ngx_epoll_process_events函数)中不会立刻处理事件,延后,先处理完所有的accept事件后,释放锁,然后再
处理正常的读写socket事件。否则的话,等你处理完了所有读写的事件,再释放锁的话,那么就有点来不及了;此时会
造成新连接的建立出现延迟,因为你占用着锁,却在处理其它fd的读写事件
static ngx_int_t
ngx_epoll_process_events(ngx_cycle_t *cycle, ngx_msec_t timer, ngx_uint_t flags)
{
events = epoll_wait(ep, event_list, (int) nevents, timer);
ngx_mutex_lock(ngx_posted_events_mutex);
for (i = 0; i < events; i++) {
c = event_list[i].data.ptr;
rev = c->read;
if ((revents & EPOLLIN) && rev->active) {
//有NGX_POST_EVENTS标志的话,就把accept事件放到ngx_posted_accept_events队列中,
//把正常的事件放到ngx_posted_events队列中延迟处理
if (flags & NGX_POST_EVENTS) {
queue = (ngx_event_t **) (rev->accept ?
&ngx_posted_accept_events : &ngx_posted_events);
ngx_locked_post_event(rev, queue);
} else {
rev->handler(rev);
}
}
wev = c->write;
if ((revents & EPOLLOUT) && wev->active) {
//同理,有NGX_POST_EVENTS标志的话,写事件延迟处理,放到ngx_posted_events队列中
if (flags & NGX_POST_EVENTS) {
ngx_locked_post_event(wev, &ngx_posted_events);
} else {
wev->handler(wev);
}
}
}
ngx_mutex_unlock(ngx_posted_events_mutex);
return NGX_OK;
}
//Nginx的上锁是非阻塞锁,看下ngx_trylock_accept_mutex实现原理:
ngx_int_t ngx_trylock_accept_mutex(ngx_cycle_t *cycle)
{
//ngx_shmtx_trylock是非阻塞取锁的,返回1表示成功,0表示没取到锁
if (ngx_shmtx_trylock(&ngx_accept_mutex)) {
//ngx_enable_accept_events会把监听的句柄都塞入到本worker进程的epoll中
if (ngx_enable_accept_events(cycle) == NGX_ERROR) {
ngx_shmtx_unlock(&ngx_accept_mutex);
return NGX_ERROR;
}
//ngx_accept_mutex_held置为1,表示拿到锁了,返回
ngx_accept_events = 0;
ngx_accept_mutex_held = 1;
return NGX_OK;
}
//处理没有拿到锁的逻辑,ngx_disable_accept_events会把监听句柄从epoll中取出
if (ngx_accept_mutex_held) {
if (ngx_disable_accept_events(cycle) == NGX_ERROR) {
return NGX_ERROR;
}
ngx_accept_mutex_held = 0;
}
return NGX_OK;
}
//保证了同一时刻只会有一个进程在监听端口
解决惊群方法二:使用reuseport
1、reuseport需要在较新的Linux系统才支持!
(Linux内核的3.9版本带来了SO_REUSEPORT特性,该特性支持多个进程或者线程绑定到同一端口,
提高服务器程序的性能,允许多个套接字bind()以及listen()同一个TCP或UDP端口,并且在内核层面实现负载均衡。)
2、如果配置了reuseport的监听套接字,每个worker进程拥有一个独立的fd,worker进程间互不干扰;
在内核层面实现负载均衡,效率更高。
reuseport的具体介绍见上一篇博客:
【博客316】网络编程:REUSERADDR与REUSEPORT
性能比较:
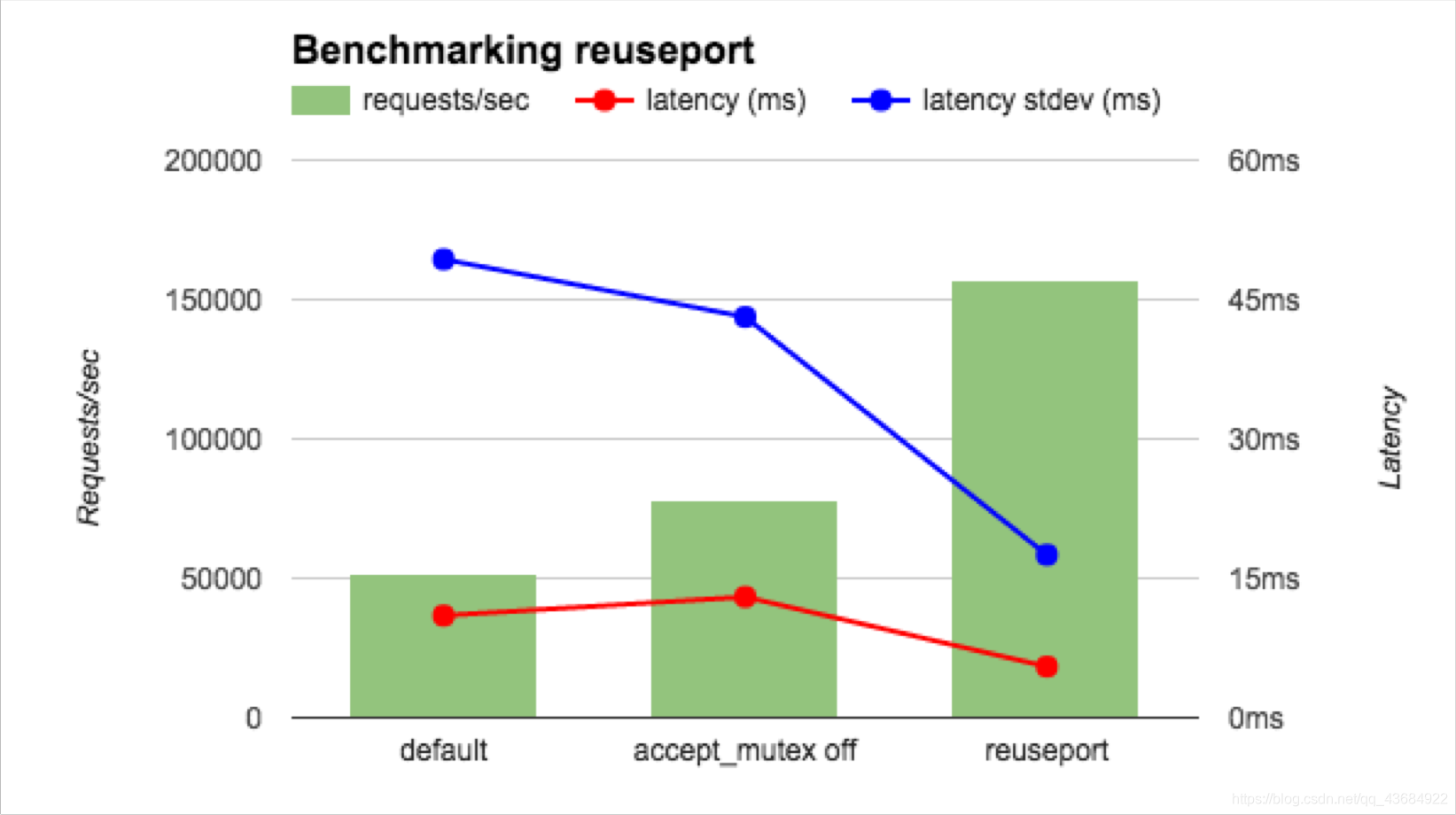
分析:
可以看到在使用reuseport之后,在时延的降低和连接数的提高都有很大的改善














 1248
1248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









