






 文章讲述了普通Spark用户在尝试通过client更新Ranger策略时遇到403错误,原因在于Ranger的官方配置仅支持通配符*或指定用户列表。管理员权限用户可以直接下载策略。解决方法是检查并调整Ranger配置以允许特定用户访问。
文章讲述了普通Spark用户在尝试通过client更新Ranger策略时遇到403错误,原因在于Ranger的官方配置仅支持通配符*或指定用户列表。管理员权限用户可以直接下载策略。解决方法是检查并调整Ranger配置以允许特定用户访问。
普通用户使用spark的client无法更新Ranger策略
报错图片:
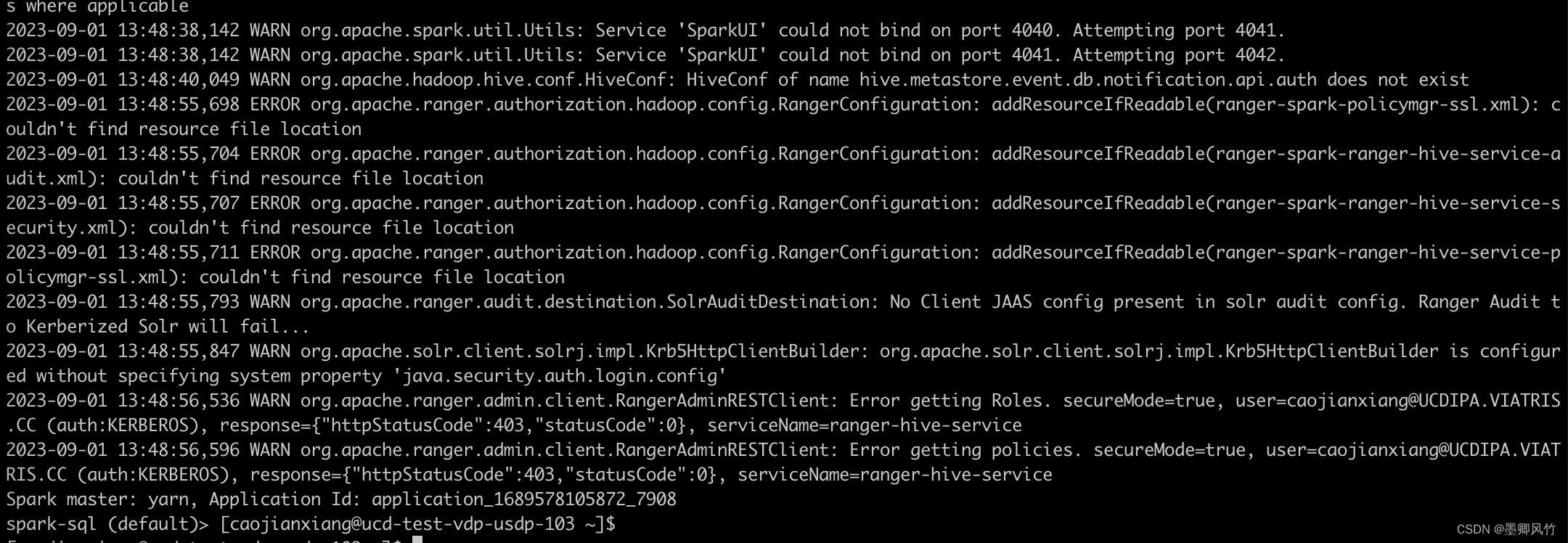
WARN org.apache.ranger.admin.client.RangerAdminRESTClient: Error getting Roles. secureMode=true, user=caojianxiang@UCDIPA.VIATRIS.CC (auth:KERBEROS),response=f"httpStatusCode":403,"statusCode":0serviceName=ranger-hive-service
解决:
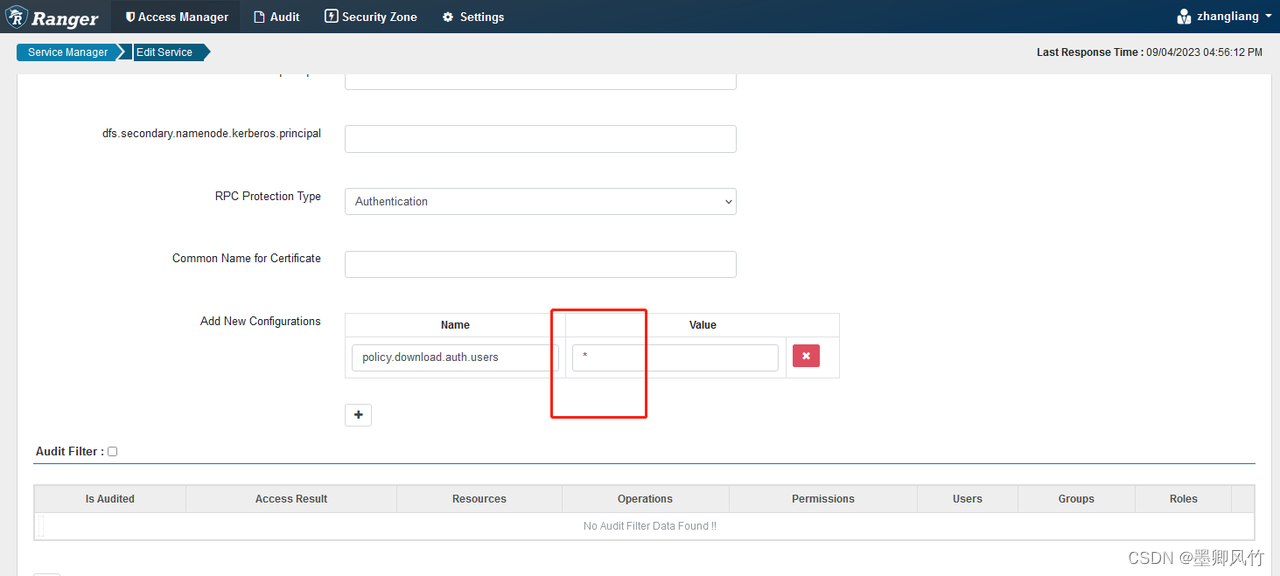
policy.download.auth.users
查看官方的配置只支持2种写法
1、设置为通配符*,允许任何用户访问和下载策略文件
2、设置用户列表,例如:user1,user2,user3…
PS:admin 权限可以直接下载策略
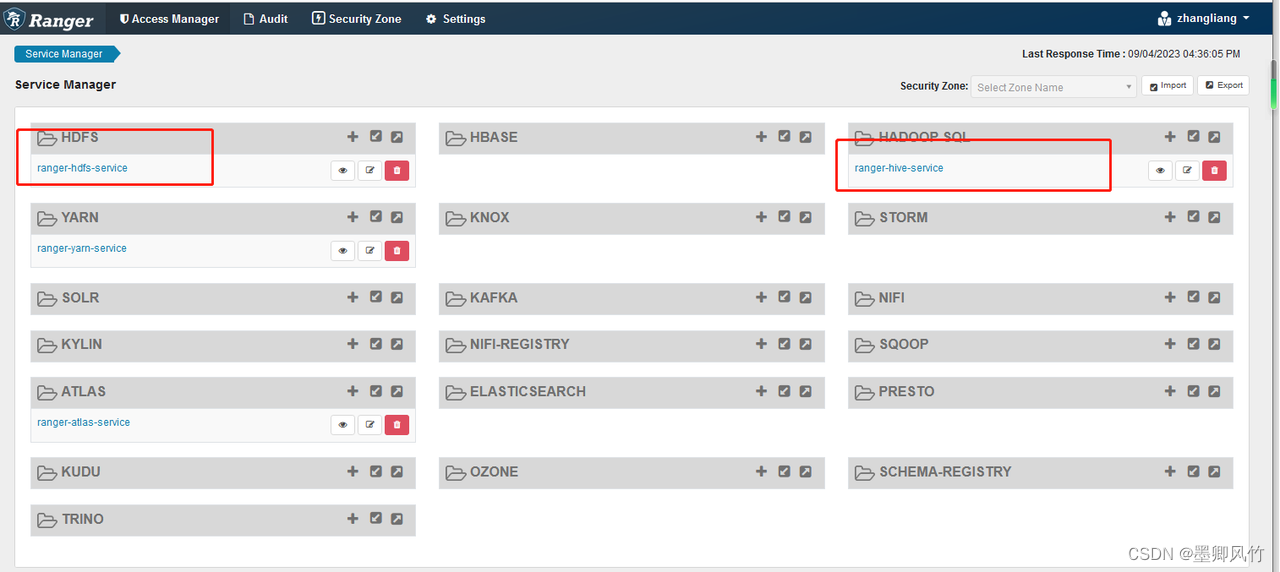
操作:(采用了官方配置1)
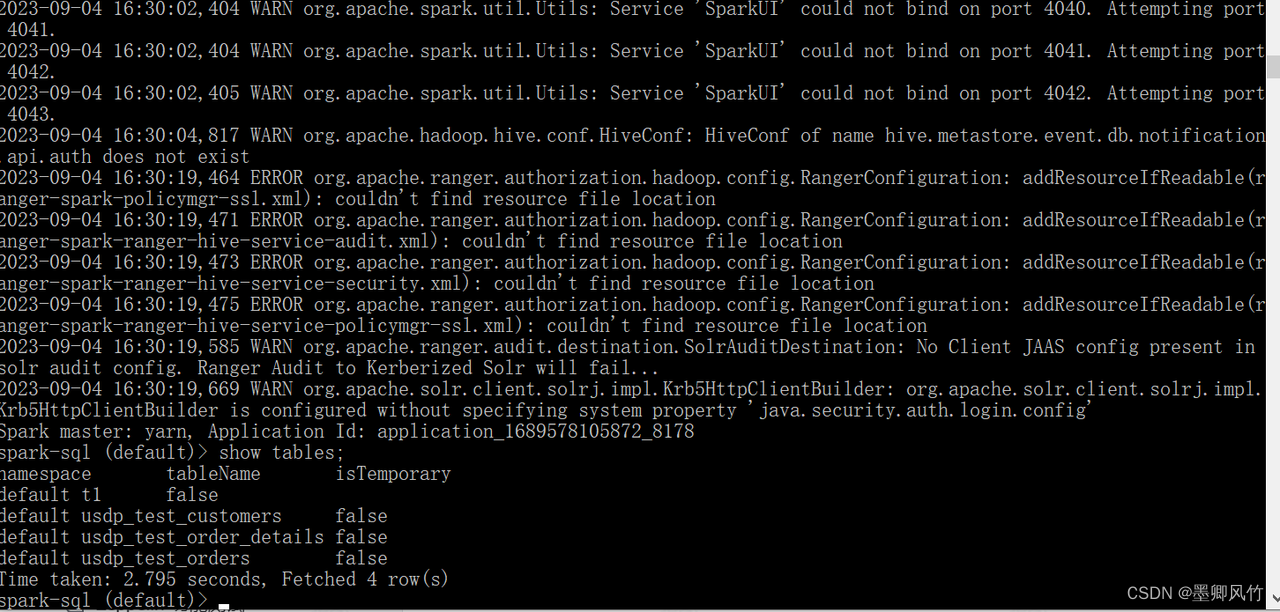
验证:

















 1353
1353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









