







目录
前言
在大数据领域,Hive作为Hadoop生态系统中的数据仓库工具,其数据组织方式直接影响查询性能。除了常见的分区技术外,分桶(Bucketing)是一种更细粒度的数据组织方式。本文将全面剖析Hive分桶机制,包括其核心概念、与分区的区别、设计原则、使用场景以及性能优化策略。
1 分桶基础概念
1.1 什么是分桶?
分桶(Bucketing)是Hive中将表数据按照哈希值分散到固定数量文件中的技术。与分区不同,分桶是在每个分区内进一步细分数据。
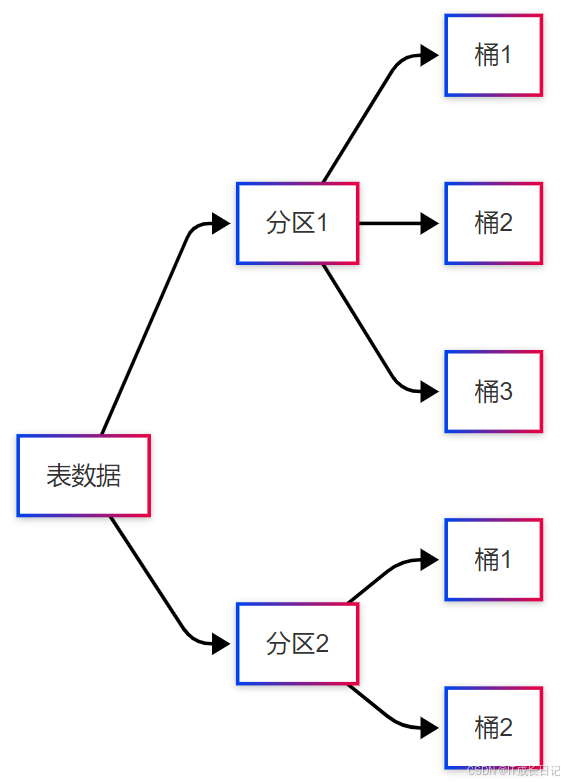
核心特征:
- 基于哈希算法分配数据到桶
- 建表时指定桶数且不可轻易更改
- 每个桶对应一个物理文件
- 支持高效的桶与桶连接(Map-side join)
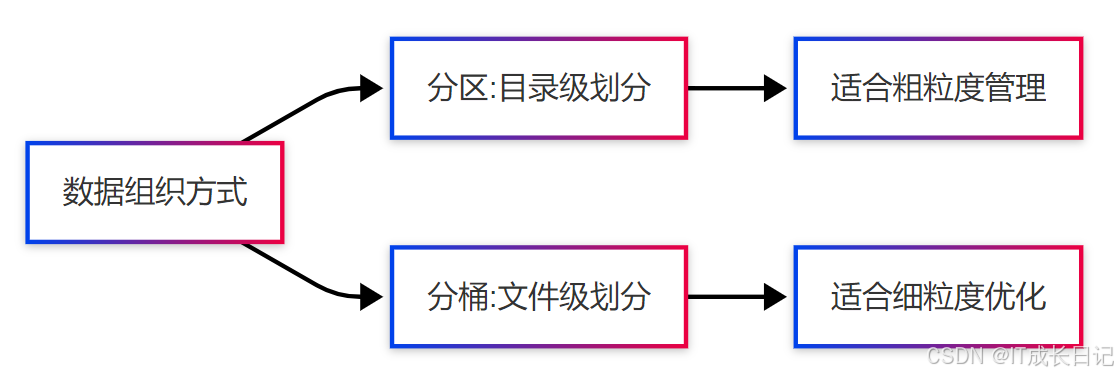
1.2 分桶与分区的区别
| 特性 | 分桶(Bucketing) | 分区(Partitioning) |
| 数据组织 | 哈希分配到固定数量桶 | 按列值划分到不同目录 |
| 存储结构 | 分区内的文件细分 | 不同子目录 |
| 主要目的 | 优化连接和采样 | 加速查询过滤 |
| 数量控制 | 固定桶数 | 动态增长的分区数 |
| 字段要求 | 高基数字段 | 低基数字段 |
| 修改成本 | 高(需重建表) | 低(可动态添加) |
2 分桶实现原理
2.1 分桶工作机制
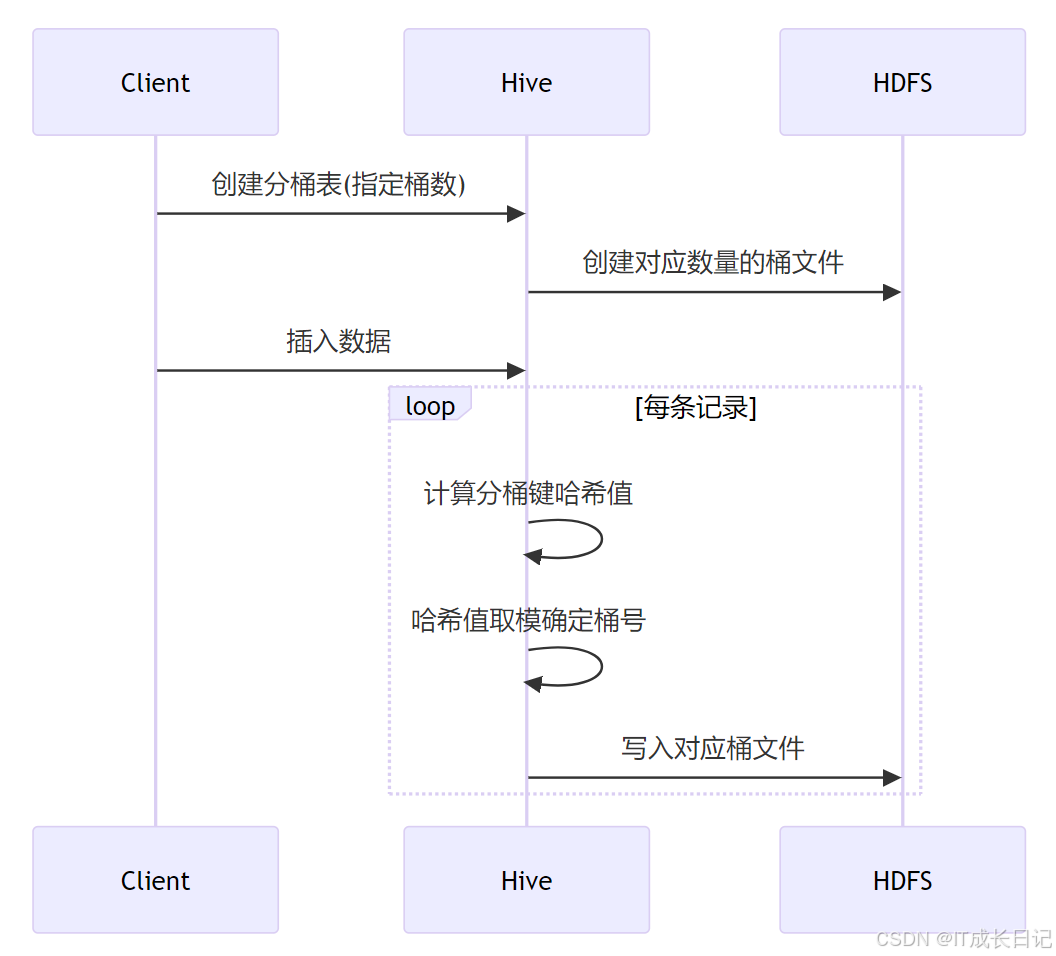
关键步骤:
- 对分桶键值计算哈希(默认Java的hashCode)
- 哈希值对桶数取模得到桶编号(0到N-1)
- 数据写入对应编号的桶文件
2.2 分桶键选择原则
理想分桶键特征:
- 高基数:不同值数量多(如用户ID而非性别)
- 均匀分布:避免数据倾斜
- 常用连接键:JOIN操作频繁使用的字段
- 稳定性:值不频繁变更
3 分桶表设计与创建
3.1 创建分桶表语法
CREATE TABLE bucketed_table (
col1 data_type,
col2 data_type,
...
)
CLUSTERED BY (bucket_key) INTO num_buckets BUCKETS
[STORED AS file_format];3.2 完整创建示例
CREATE TABLE user_activities (
user_id BIGINT,
activity_time TIMESTAMP,
page_url STRING,
duration INT
)
CLUSTERED BY (user_id) INTO 32 BUCKETS
STORED AS ORC
TBLPROPERTIES ("orc.compress"="SNAPPY");3.3 分桶数确定原则
黄金法则:
- 每个桶文件大小接近HDFS块大小(128MB/256MB)
- 通常为2的幂次方(16,32,64,...)
- 考虑集群规模和数据增长
4 分桶数据加载
4.1 分桶表数据加载要求
- 必须通过INSERT方式加载,确保数据正确分桶:
-- 启用分桶强制设置
SET hive.enforce.bucketing = true;
-- 从其他表加载
INSERT INTO TABLE bucketed_table
SELECT * FROM source_table;
-- 明确指定分桶字段(推荐)
INSERT INTO TABLE bucketed_table
SELECT user_id, activity_time, page_url, duration
FROM source_table;4.2 分桶加载过程

5 分桶核心应用场景
5.1 高效JOIN优化(Map-side Join)
- 原理:相同分桶方式的表可避免Shuffle
-- 用户表(按user_id分桶)
CREATE TABLE users_bucketed (
user_id BIGINT,
name STRING
)
CLUSTERED BY (user_id) INTO 32 BUCKETS;
-- 订单表(按user_id分桶)
CREATE TABLE orders_bucketed (
order_id BIGINT,
user_id BIGINT,
amount DECIMAL
)
CLUSTERED BY (user_id) INTO 32 BUCKETS;
-- 高效JOIN
SELECT u.name, o.order_id, o.amount
FROM users_bucketed u JOIN orders_bucketed o
ON u.user_id = o.user_id;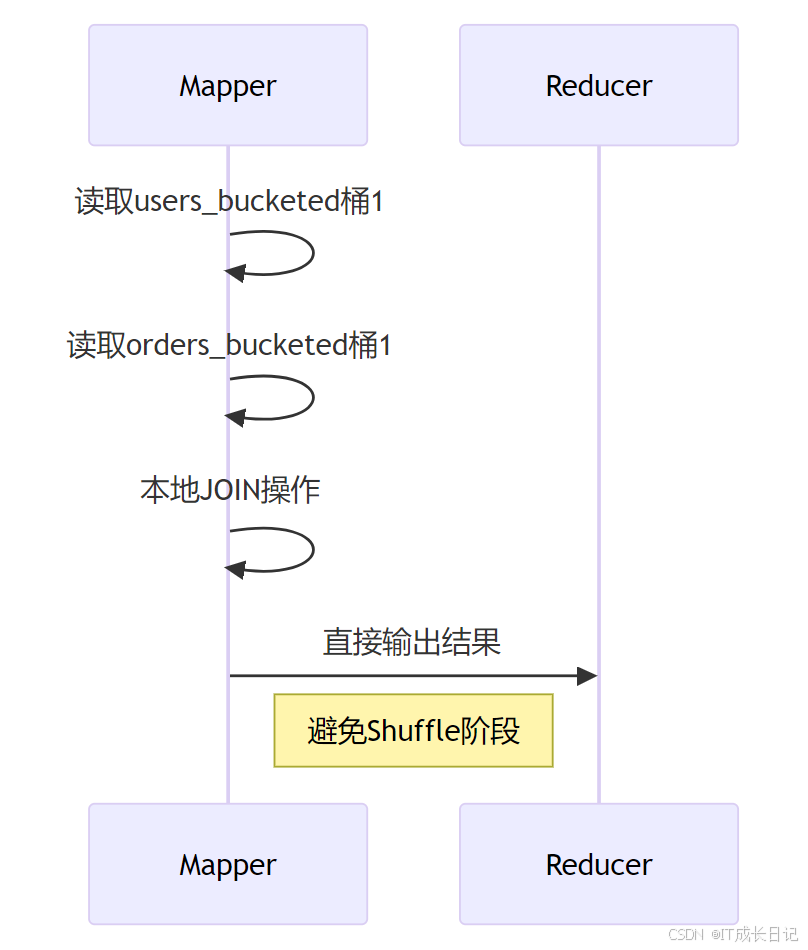
5.2 高效数据采样
-- 随机采样约10%数据
SELECT * FROM bucketed_table
TABLESAMPLE(BUCKET 1 OUT OF 10 ON user_id);
-- 采样特定桶
SELECT * FROM bucketed_table
TABLESAMPLE(BUCKET 3 OUT OF 32 ON user_id);5.3 数据倾斜优化
- 对倾斜键单独分桶处理:
-- 对倾斜的hot_user单独分桶
CREATE TABLE skewed_activities (
user_id BIGINT,
...
)
CLUSTERED BY (user_id) INTO 64 BUCKETS
SKEWED BY (user_id) ON (12345) [STORED AS DIRECTORIES];6 分桶性能优化策略
6.1 分桶与存储格式协同优化
最佳组合:
- ORC格式 + 分桶:列存+高效压缩
- Parquet格式 + 分桶:列存+谓词下推
CREATE TABLE optimized_bucketed (
id BIGINT,
...
)
CLUSTERED BY (id) INTO 64 BUCKETS
STORED AS ORC
TBLPROPERTIES (
"orc.compress"="ZLIB",
"orc.create.index"="true"
);6.2 分桶监控与维护
- 关键监控指标:
-- 检查桶文件大小分布
dfs -du -h /user/hive/warehouse/db.db/table/*;
-- 验证桶数量
DESCRIBE FORMATTED bucketed_table;- 定期维护操作:
-- 合并小文件(针对ORC)
ALTER TABLE bucketed_table CONCATENATE;
-- 重新分桶(需要重建表)
CREATE TABLE new_bucketed AS
SELECT * FROM old_bucketed;7 常见问题与解决方案
7.1 分桶倾斜问题
- 现象:某些桶远大于其他桶
- 解决方案:
-- 方案1:使用组合分桶键 CLUSTERED BY (user_id, order_id) INTO 64 BUCKETS -- 方案2:对倾斜键特殊处理 SKEWED BY (user_id) ON (12345,67890) [STORED AS DIRECTORIES] -- 方案3:增加桶数量 CLUSTERED BY (user_id) INTO 128 BUCKETS
7.2 桶文件过多问题
- 现象:小文件导致NameNode压力大
- 解决方案:
-- 方案1:使用组合分桶键
CLUSTERED BY (user_id, order_id) INTO 64 BUCKETS
-- 方案2:对倾斜键特殊处理
SKEWED BY (user_id) ON (12345,67890) [STORED AS DIRECTORIES]
-- 方案3:增加桶数量
CLUSTERED BY (user_id) INTO 128 BUCKETS7.3 分桶失效问题
现象:未达到预期性能提升检查清单:
- 确认hive.enforce.bucketing=true
- 验证实际桶文件数量dfs -count
- 检查JOIN条件是否匹配分桶键
- 确认数据加载使用INSERT方式
8 总结
分桶技术核心价值:
- 连接加速:实现Map-side join避免Shuffle
- 采样优化:支持高效随机采样
- 存储优化:更均衡的数据分布
- 查询加速:减少数据扫描量
分桶设计黄金法则:
键选择原则:
- 高基数、分布均匀
- 常用连接字段优先
- 避免频繁更新字段
桶数确定原则:
- 参考数据量和HDFS块大小
- 通常为2的幂次方
- 考虑未来数据增长
存储格式选择:
- 列式存储(ORC/Parquet)优先
- 配置适当压缩(ZLIB/SNAPPY)
通过合理应用分桶技术,可使Hive查询性能提升3-10倍。建议在大型事实表、频繁连接的表上优先实施分桶优化,同时结合分区技术实现多层次数据组织,构建高效的企业级数据仓库。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











