









转:链接
二、Python字符串和正则
字符串无所不在,字符串的处理也是最常见的操作。本章节将总结和字符串处理相关的一切操作。主要包括基本的字符串操作;高级字符串操作之正则。目前共有25个小例子
91 反转字符串
st="python"
#方法1
''.join(reversed(st))
#方法2
st[::-1]
92 字符串切片操作
字符串切片操作——查找替换3或5的倍数
In [1]:[str("java"[i%3*4:]+"python"[i%5*6:] or i) for i in range(1,15)]
OUT[1]:['1',
'2',
'java',
'4',
'python',
'java',
'7',
'8',
'java',
'python',
'11',
'java',
'13',
'14']
93 join串联字符串
In [4]: mystr = ['1',
...: '2',
...: 'java',
...: '4',
...: 'python',
...: 'java',
...: '7',
...: '8',
...: 'java',
...: 'python',
...: '11',
...: 'java',
...: '13',
...: '14']
In [5]: ','.join(mystr) #用逗号连接字符串
Out[5]: '1,2,java,4,python,java,7,8,java,python,11,java,13,14'
94 字符串的字节长度
def str_byte_len(mystr):
return (len(mystr.encode('utf-8')))
str_byte_len('i love python') # 13(个字节)
str_byte_len('字符') # 6(个字节)
以下是正则部分
import re
95 查找第一个匹配串
s = 'i love python very much'
pat = 'python'
r = re.search(pat,s)
print(r.span()) #(7,13)
96 查找所有1的索引
s = '山东省潍坊市青州第1中学高三1班'
pat = '1'
r = re.finditer(pat,s)
for i in r:
print(i)
# <re.Match object; span=(9, 10), match='1'>
# <re.Match object; span=(14, 15), match='1'>
97 \d 匹配数字[0-9]
findall找出全部位置的所有匹配
s = '一共20行代码运行时间13.59s'
pat = r'\d+' # +表示匹配数字(\d表示数字的通用字符)1次或多次
r = re.findall(pat,s)
print(r)
# ['20', '13', '59']
98 匹配浮点数和整数
?表示前一个字符匹配0或1次
s = '一共20行代码运行时间13.59s'
pat = r'\d+\.?\d+' # ?表示匹配小数点(\.)0次或1次,这种写法有个小bug,不能匹配到个位数的整数
r = re.findall(pat,s)
print(r)
# ['20', '13.59']
# 更好的写法:
pat = r'\d+\.\d+|\d+' # A|B,匹配A失败才匹配B
99 ^匹配字符串的开头
s = 'This module provides regular expression matching operations similar to those found in Perl'
pat = r'^[emrt]' # 查找以字符e,m,r或t开始的字符串
r = re.findall(pat,s)
print(r)
# [],因为字符串的开头是字符`T`,不在emrt匹配范围内,所以返回为空
IN [11]: s2 = 'email for me is guozhennianhua@163.com'
re.findall('^[emrt].*',s2)# 匹配以e,m,r,t开始的字符串,后面是多个任意字符
Out[11]: ['email for me is guozhennianhua@163.com']
100 re.I 忽略大小写
s = 'That'
pat = r't'
r = re.findall(pat,s,re.I)
In [22]: r
Out[22]: ['T', 't']
101 理解compile的作用
如果要做很多次匹配,可以先编译匹配串:
import re
pat = re.compile('\W+') # \W 匹配不是数字和字母的字符
has_special_chars = pat.search('ed#2@edc')
if has_special_chars:
print(f'str contains special characters:{has_special_chars.group(0)}')
###输出结果:
# str contains special characters:#
### 再次使用pat正则编译对象 做匹配
again_pattern = pat.findall('guozhennianhua@163.com')
if '@' in again_pattern:
print('possibly it is an email')
102 使用()捕获单词,不想带空格
使用()捕获
s = 'This module provides regular expression matching operations similar to those found in Perl'
pat = r'\s([a-zA-Z]+)'
r = re.findall(pat,s)
print(r) #['module', 'provides', 'regular', 'expression', 'matching', 'operations', 'similar', 'to', 'those', 'found', 'in', 'Perl']
看到提取单词中未包括第一个单词,使用?表示前面字符出现0次或1次,但是此字符还有表示贪心或非贪心匹配含义,使用时要谨慎。
s = 'This module provides regular expression matching operations similar to those found in Perl'
pat = r'\s?([a-zA-Z]+)'
r = re.findall(pat,s)
print(r) #['This', 'module', 'provides', 'regular', 'expression', 'matching', 'operations', 'similar', 'to', 'those', 'found', 'in', 'Perl']
103 split分割单词
使用以上方法分割单词不是简洁的,仅仅是为了演示。分割单词最简单还是使用split函数。
s = 'This module provides regular expression matching operations similar to those found in Perl'
pat = r'\s+'
r = re.split(pat,s)
print(r) # ['This', 'module', 'provides', 'regular', 'expression', 'matching', 'operations', 'similar', 'to', 'those', 'found', 'in', 'Perl']
### 上面这句话也可直接使用str自带的split函数:
s.split(' ') #使用空格分隔
### 但是,对于风格符更加复杂的情况,split无能为力,只能使用正则
s = 'This,,, module ; \t provides|| regular ; '
words = re.split('[,\s;|]+',s) #这样分隔出来,最后会有一个空字符串
words = [i for i in words if len(i)>0]
104 match从字符串开始位置匹配
注意match,search等的不同:
- match函数
import re
### match
mystr = 'This'
pat = re.compile('hi')
pat.match(mystr) # None
pat.match(mystr,1) # 从位置1处开始匹配
Out[90]: <re.Match object; span=(1, 3), match='hi'>
- search函数
search是从字符串的任意位置开始匹配
In [91]: mystr = 'This'
...: pat = re.compile('hi')
...: pat.search(mystr)
Out[91]: <re.Match object; span=(1, 3), match='hi'>
105 替换匹配的子串
sub函数实现对匹配子串的替换
content="hello 12345, hello 456321"
pat=re.compile(r'\d+') #要替换的部分
m=pat.sub("666",content)
print(m) # hello 666, hello 666
106 贪心捕获
(.*)表示捕获任意多个字符,尽可能多的匹配字符
content='<h>ddedadsad</h><div>graph</div>bb<div>math</div>cc'
pat=re.compile(r"<div>(.*)</div>") #贪婪模式
m=pat.findall(content)
print(m) #匹配结果为: ['graph</div>bb<div>math']
107 非贪心捕获
仅添加一个问号(?),得到结果完全不同,这是非贪心匹配,通过这个例子体会贪心和非贪心的匹配的不同。
content='<h>ddedadsad</h><div>graph</div>bb<div>math</div>cc'
pat=re.compile(r"<div>(.*?)</div>")
m=pat.findall(content)
print(m) # ['graph', 'math']
非贪心捕获,见好就收。
108 常用元字符总结
. 匹配任意字符
^ 匹配字符串开始位置
$ 匹配字符串中结束的位置
* 前面的原子重复0次、1次、多次
? 前面的原子重复0次或者1次
+ 前面的原子重复1次或多次
{n} 前面的原子出现了 n 次
{n,} 前面的原子至少出现 n 次
{n,m} 前面的原子出现次数介于 n-m 之间
( ) 分组,需要输出的部分
109 常用通用字符总结
\s 匹配空白字符
\w 匹配任意字母/数字/下划线
\W 和小写 w 相反,匹配任意字母/数字/下划线以外的字符
\d 匹配十进制数字
\D 匹配除了十进制数以外的值
[0-9] 匹配一个0-9之间的数字
[a-z] 匹配小写英文字母
[A-Z] 匹配大写英文字母
110 密码安全检查
密码安全要求:1)要求密码为6到20位; 2)密码只包含英文字母和数字
pat = re.compile(r'\w{6,20}') # 这是错误的,因为\w通配符匹配的是字母,数字和下划线,题目要求不能含有下划线
# 使用最稳的方法:\da-zA-Z满足`密码只包含英文字母和数字`
pat = re.compile(r'[\da-zA-Z]{6,20}')
选用最保险的fullmatch方法,查看是否整个字符串都匹配:
pat.fullmatch('qaz12') # 返回 None, 长度小于6
pat.fullmatch('qaz12wsxedcrfvtgb67890942234343434') # None 长度大于22
pat.fullmatch('qaz_231') # None 含有下划线
pat.fullmatch('n0passw0Rd')
Out[4]: <re.Match object; span=(0, 10), match='n0passw0Rd'>
111 爬取百度首页标题
import re
from urllib import request
#爬虫爬取百度首页内容
data=request.urlopen("http://www.baidu.com/").read().decode()
#分析网页,确定正则表达式
pat=r'<title>(.*?)</title>'
result=re.search(pat,data)
print(result) <re.Match object; span=(1358, 1382), match='<title>百度一下,你就知道</title>'>
result.group() # 百度一下,你就知道
112 批量转化为驼峰格式(Camel)
数据库字段名批量转化为驼峰格式
分析过程
# 用到的正则串讲解
# \s 指匹配: [ \t\n\r\f\v]
# A|B:表示匹配A串或B串
# re.sub(pattern, newchar, string):
# substitue代替,用newchar字符替代与pattern匹配的字符所有.
# title(): 转化为大写,例子:
# 'Hello world'.title() # 'Hello World'
# print(re.sub(r"\s|_|", "", "He llo_worl\td"))
s = re.sub(r"(\s|_|-)+", " ",
'some_database_field_name').title().replace(" ", "")
#结果: SomeDatabaseFieldName
# 可以看到此时的第一个字符为大写,需要转化为小写
s = s[0].lower()+s[1:] # 最终结果
整理以上分析得到如下代码:
import re
def camel(s):
s = re.sub(r"(\s|_|-)+", " ", s).title().replace(" ", "")
return s[0].lower() + s[1:]
# 批量转化
def batch_camel(slist):
return [camel(s) for s in slist]
测试结果:
s = batch_camel(['student_id', 'student\tname', 'student-add'])
print(s)
# 结果
['studentId', 'studentName', 'studentAdd']
113 str1是否为str2的permutation
排序词(permutation):两个字符串含有相同字符,但字符顺序不同。
from collections import defaultdict
def is_permutation(str1, str2):
if str1 is None or str2 is None:
return False
if len(str1) != len(str2):
return False
unq_s1 = defaultdict(int)
unq_s2 = defaultdict(int)
for c1 in str1:
unq_s1[c1] += 1
for c2 in str2:
unq_s2[c2] += 1
return unq_s1 == unq_s2
这个小例子,使用python内置的defaultdict,默认类型初始化为int,计数默次数都为0. 这个解法本质是 hash map lookup
统计出的两个defaultdict:unq_s1,unq_s2,如果相等,就表明str1、 str2互为排序词。
下面测试:
r = is_permutation('nice', 'cine')
print(r) # True
r = is_permutation('', '')
print(r) # True
r = is_permutation('', None)
print(r) # False
r = is_permutation('work', 'woo')
print(r) # False
以上就是使用defaultdict的小例子,希望对读者朋友理解此类型有帮助。
114 str1是否由str2旋转而来
stringbook旋转后得到bookstring,写一段代码验证str1是否为str2旋转得到。
思路
转化为判断:str1是否为str2+str2的子串
def is_rotation(s1: str, s2: str) -> bool:
if s1 is None or s2 is None:
return False
if len(s1) != len(s2):
return False
def is_substring(s1: str, s2: str) -> bool:
return s1 in s2
return is_substring(s1, s2 + s2)
测试
r = is_rotation('stringbook', 'bookstring')
print(r) # True
r = is_rotation('greatman', 'maneatgr')
print(r) # False
115 正浮点数
从一系列字符串中,挑选出所有正浮点数。
该怎么办?
玩玩正则表达式,用正则搞它!
关键是,正则表达式该怎么写呢?
有了!
^[1-9]\d*\.\d*$
^ 表示字符串开始
[1-9] 表示数字1,2,3,4,5,6,7,8,9
^[1-9] 连起来表示以数字 1-9 作为开头
\d 表示一位 0-9 的数字
* 表示前一位字符出现 0 次,1 次或多次
\d* 表示数字出现 0 次,1 次或多次
\. 表示小数点
\$ 表示字符串以前一位的字符结束
^[1-9]\d*\.\d*$ 连起来就求出所有大于 1.0 的正浮点数。
那 0.0 到 1.0 之间的正浮点数,怎么求,干嘛不直接汇总到上面的正则表达式中呢?
这样写不行吗:^[0-9]\d*\.\d*$
OK!
那我们立即测试下呗
In [85]: import re
In [87]: recom = re.compile(r'^[0-9]\d*\.\d*$')
In [88]: recom.match('000.2')
Out[88]: <re.Match object; span=(0, 5), match='000.2'>
结果显示,正则表达式 ^[0-9]\d*\.\d*$ 竟然匹配到 000.2,认为它是一个正浮点数~~~!!!!
晕!!!!!!
所以知道为啥要先匹配大于 1.0 的浮点数了吧!
如果能写出这个正则表达式,再写另一部分就不困难了!
0.0 到 1.0 间的浮点数:^0\.\d*[1-9]\d*$
两个式子连接起来就是最终的结果:
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$
如果还是看不懂,看看下面的正则分布剖析图吧:
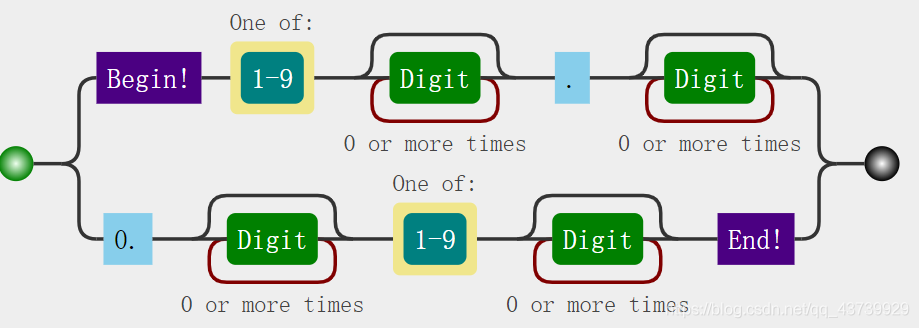














 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









