






1 聚类算法
对于"监督学习"(supervised learning),其训练样本是带有标记信息的,并且监督学习的目的是:对带有标记的数据集进行模型学习,从而便于对新的样本进行分类。而在“无监督学习”(unsupervised learning)中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。对于无监督学习,应用最广的便是"聚类"(clustering)。
“聚类算法”试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个“簇”(cluster),通过这样的划分,每个簇可能对应于一些潜在的概念或类别。
我们可以通过下面这个图来理解:
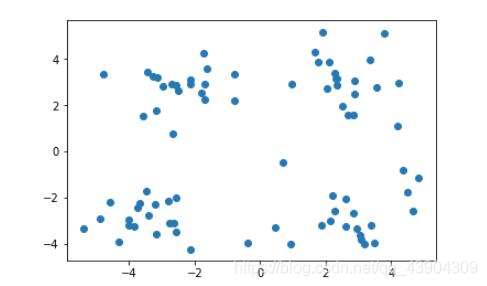
上图是未做标记的样本集,通过他们的分布,我们很容易对上图中的样本做出以下几种划分。
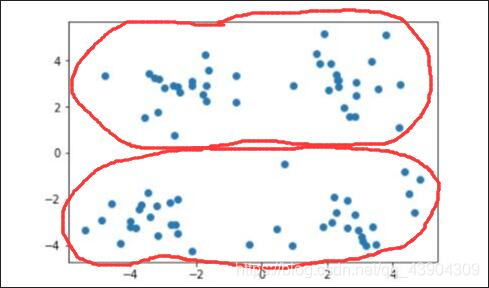
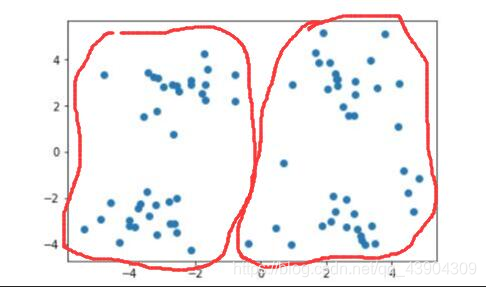
当需要将其划分为两个簇时,即 k=2 时:
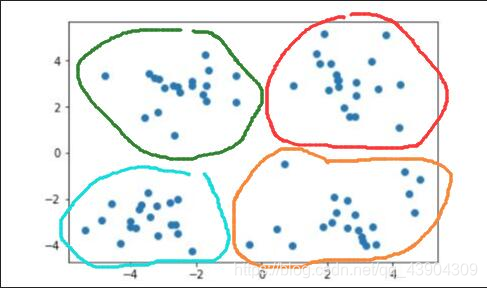
当需要将其划分为四个簇时,即 k=4 时:
那么计算机是如何进行这样的划分的呢?这就需要聚类算法来进行实现了。本文主要针对聚类算法中的一种——kmeans算法进行介绍。
2.K均值聚类算法(kmeans)
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
根据以上描述,我们大致可以猜测到实现kmeans算法的主要三点:
(1)簇个数 k 的选择
(2)各个样本点到“簇中心”的距离
(3)根据新划分的簇,更新“簇中心”
2.1 kmeans算法要点
(1) k 值的选择
k 的选择一般是按照实际需求进行决定,或在实现算法时直接给定 k 值。
(2) 距离的度量
给定样本
x(i)={x(i)1,x(i)2,…,x(i)n,}与x(j)={x(j)1,x(j)2,…,x(j)n,},其中i,j=1,2,…,m,表示样本数,,其中i,j=1,2,…,m,表示样本数,n表示特征数 。距离的度量方法主要分为以下几种:
(2.1)有序属性距离度量(离散属性 {1,2,3} 或连续属性):
闵可夫斯基距离(Minkowski distance): 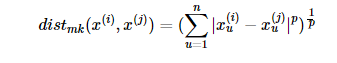
欧氏距离(Euclidean distance),即当 p=2 时的闵可夫斯基距离: 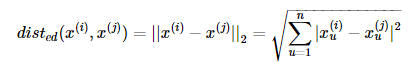
曼哈顿距离(Manhattan distance),即当 p=1 时的闵可夫斯基距离: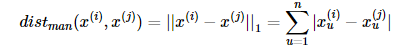
(3) 更新“簇中心”
对于划分好的各个簇,计算各个簇中的样本点均值,将其均值作为新的簇中心。
2.2 kmeans算法过程

算法实现步骤
1、首先确定一个k值,即我们希望将数据集经过聚类得到k个集合。
2、从数据集中随机选择k个数据点作为质心。
3、对数据集中每一个点,计算其与每一个质心的距离(如欧式距离),离哪个质心近,就划分到那个质心所属的集合。
4、把所有数据归好集合后,一共有k个集合。然后重新计算每个集合的质心。
5、如果新计算出来的质心和原来的质心之间的距离小于某一个设置的阈值(表示重新计算的质心的位置变化不大,趋于稳定,或者说收敛),我们可以认为聚类已经达到期望的结果,算法终止。
6、如果新质心和原质心距离变化很大,需要迭代3~5步骤。
为避免运行时间过长,通常设置一个最大运行轮数或最小调整幅度阈值,若达到最大轮数或调整幅度小于阈值,则停止运行。
代码
import numpy as np
import matplotlib.pyplot as plt
#两点距离
def distance(e1,e2):
return np.sqrt((e1[0]-e2[0])**2+(e1[1]-e2[1])**2)
# 集合中心
def means(arr):
return np.array([np.mean([e[0] for e in arr]), np.mean([e[1] for e in arr])])#计算均值
#arr中距离a最远的元素,用于初始化聚类中心
def farthest(k_arr,arr):
f=[0,0]
max_d=0
for e in arr:
d = 0
#d=distance(k_arr[0],e)
for i in range(k_arr.__len__()):
d=d+np.sqrt(distance(k_arr[i],e))
if d > max_d:
max_d = d
f=e
return f
#arr中距离a最近的元素,用于聚类
def closest(a,arr):
c=arr[1]
min_d=distance(a,arr[1])
arr = arr[1:]
for e in arr:
d=distance(a,e)
if d<min_d:
min_d=d
c=e
return c
#随机数据生成
arr = np.random.randint(100,size=(100,1,2))[:,0,:]
print("生成的随机数组:")
print(arr)
#初始化聚类中心和聚类容器
m=5#k值
r = np.random.randint(arr.__len__()-1)
#print(r)
k_arr=np.array([arr[r]])#从arr中随机选一个中心点
cla_arr=[[]]
print("随机生成一个中心点:")
print(k_arr)
for i in range(m-1):
k=farthest(k_arr,arr)
k_arr=np.concatenate([k_arr,np.array([k])])
cla_arr.append([])
print("彼此相距最远的{}类中心点".format(m))
print(k_arr)
#迭代聚类
n=20
cla_temp=cla_arr
for i in range(n):#迭代n次
for e in arr:#把集合里每一个元素聚到最近的类
ki=0 #假设距离第一个中心最近
min_d=distance(e,k_arr[ki])
for j in range(1, k_arr.__len__()):
if distance(e, k_arr[j])<min_d: #找到更近的聚类中心
min_d=distance(e,k_arr[j])
ki=j
cla_temp[ki].append(e)
#迭代更新聚类中心
B=[]
for k in range(k_arr.__len__()):
k_arr[k]=means(cla_temp[k])#更新均值
B.append(k_arr[k])
A=[]
if A==B:
break
else:
A=B
print("质心")
print(B)
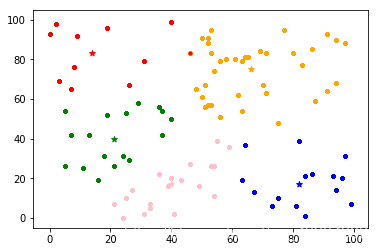
#可视化展示
col=['Pink','orange','red','blue','green']
for i in range(m):
plt.scatter(k_arr[i][0],k_arr[i][1],linewidth=1,color=col[i],marker='*')#质心
plt.scatter([e[0] for e in cla_temp[i]],[e[1] for e in cla_temp[i]],linewidth=1,color=col[i],marker='.')
plt.show()
结果
生成的随机数组:
[[69 84]
[77 95]
[61 80]
[73 6]
[ 5 54]
[64 81]
[55 39]
[54 11]
[ 7 42]
[94 68]
[64 37]
[53 95]
[49 16]
[52 88]
[51 67]
[29 58]
[63 19]
[40 20]
[59 36]
[94 90]
[36 22]
[97 88]
[ 9 92]
[54 26]
[54 74]
[48 65]
[56 51]
[70 67]
[52 91]
[86 85]
[18 31]
[31 79]
[37 42]
[27 14]
[ 3 69]
[58 80]
[13 42]
[ 8 76]
[ 0 93]
[82 39]
[50 91]
[26 67]
[39 16]
[ 5 26]
[75 10]
[11 25]
[87 59]
[33 7]
[58 80]
[16 19]
[71 63]
[62 62]
[ 7 65]
[80 83]
[84 21]
[36 56]
[33 5]
[99 7]
[40 50]
[37 54]
[63 54]
[46 27]
[93 21]
[96 20]
[67 13]
[46 83]
[71 83]
[56 79]
[24 31]
[31 2]
[83 77]
[19 96]
[53 26]
[86 22]
[24 0]
[75 48]
[81 6]
[84 1]
[94 14]
[25 53]
[63 79]
[21 26]
[26 29]
[53 83]
[91 93]
[53 57]
[65 81]
[41 2]
[52 57]
[51 56]
[40 99]
[ 2 98]
[19 52]
[97 31]
[43 19]
[91 64]
[65 81]
[50 61]
[21 7]
[25 10]]
随机生成一个中心点:
[[27 14]]
彼此相距最远的5类中心点
[[27 14]
[97 88]
[ 2 98]
[99 7]
[ 5 26]]
质心
[array([40, 17]), array([66, 75]), array([14, 83]), array([82, 17]), array([21, 40])]














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









