





Scrapy提取数据有自己的一套机制,它们被称作选择器(seletors),通过特定的Xpath或者css表达式来"选择"html文件中的某个部分。
Xpath是一门用来在XML文件中选择节点的语言,也可以用在HTML上,css是一门将HTML文档样式化的语言,选择器由它定义,并与特定的HTML元素的样式相关联
Scrapy的选择器构建与lxml库之上,这意味着他们在速度和解析准确性上非常相似
Xpath是一门在XML文档中查找信息的语言,Xpath可用来在XML文档中对元素和属性进行遍历。Xpath含有超过100个内建的函数,这些函数用于字符串值,数值,日期和时间比较,节点和QName处理,序列处理,逻辑值等等。
XPath,有7种类型节点:元素,属性,文本,命名空间,处理指令,注释以及文档节点
练习代码如下
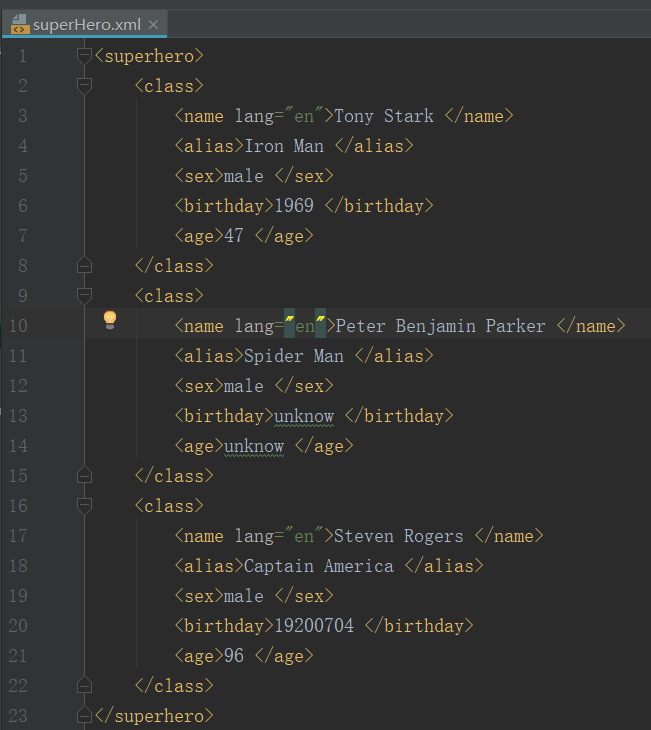
<superhero>
<class>
<name>Tony Stark </name>
<alias>Iron Man </alias>
<sex>male </sex>
<birthday>1969 </birthday>
<age>47 </age>
</class>
<class>
<name>Peter Benjamin Parker </name>
<alias>Spider Man </alias>
<sex>male </sex>
<birthday>unknow </birthday>
<age>unknow </age>
</class>
<class>
<name>Steven Rogers </name>
<alias>Captain America </alias>
<sex>male </sex>
<birthday>19200704 </birthday>
<age>96 </age>
</class>
</superhero>
Xpath使用路径表达式在XML文档中选取节点,常用路劲表达式如下:
表达式 描述
nodeName 选取此节点的所有子节点
/ 从根节点选取
// 从匹配选择的当前节点选择文档中的节点,不考虑它们的位置
. 选取当前节点
… 选取当前节点的父节点
@ 选取属性
* 匹配任何元素节点
@* 匹配任何属性节点
Node() 匹配任何类型的节点
下面用Xpath选择器来"采集"XML文件所需要的内容
在pycharm上面创建superHero.xml文件,把上面的xml内容导入,进行练习
准备工作,如下

上面这段代码的意思是:导入scrapy.selector模块中的Selector,打开superHero.xml文件,并将内容写入到变量body中,然后使用XPath选择器显示superHero.xml文件中的所有内容,执行结果如下

下面来看XPath选择器“收集”数据
练习1,代码如下
print(‘采集superHero.xml中第一个class的内容’)
Selector(text=body).xpath(‘/html/body/superhero/class[1]’).extract()
执行结果

可以对比下之前的superHero.xml文件,看选择的第一个class内容是否正确
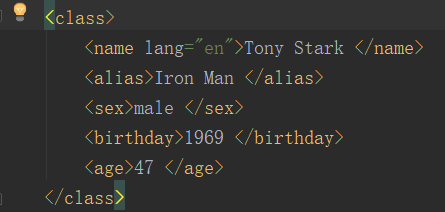
对比下内容一样,选取没问题
练习2,代码如下
print(‘采集superHero.xml中最后一个class的内容’)
Selector(text=body).xpath(‘/html/body/superhero/class[last()]’).extract()
执行结果,然后去对比下

练习3,代码如下
print(‘采集superHero.xml中name属性为en的数据’)
Selector(text=body).xpath(‘//name[@lang=“en”]’).extract()
执行结果,去对比

练习4,代码如下
print(‘采集superHero.xml中倒数第二个class的name节点的文本’)
Selector(text=body).xpath(‘/html/body/superhero/class[last()-1]/name/text()’).extract()
执行结果,对比

练习5,代码如下
print(‘以下展示的是嵌套选择器’)
sub = Selector(text=body).xpath(‘/html/body/superhero/class[last()-1]’).extract()
sub
Selector(text=sub[0]).xpath(‘/html/body/class/sex/text()’).extract()
Selector(text=sub[0]).xpath(‘//class/sex/text()’).extract()
执行结果对比

注释
sub = Selector(text=body).xpath(‘/html/body/superhero/class[last()-1]’).extract()
注释:采集superHero中倒数第二个class内容,然后赋值给subBody
sub
Selector(text=sub[0]).xpath(‘/html/body/class/sex/text()’).extract()
注释:从根节点进行匹配获取sex里面的文本,注意xpath后面接的是 / 指根节点
Selector(text=sub[0]).xpath(‘//class/sex/text()’).extract()
注释:从当前节点进行匹配获取sex里面的文本,注意xpath后面接的是 //指当前节点















 458
458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









