







掌握常见常用Java集合框架
说到集合框架,下面这张图一定经常会看见

初看这副图,你可能会觉得眼花缭乱,问题不大,本文这就带你去了解这副图。
1.整体感知
-
从图中可以看出,集合框架主要分为两个类型,Collection和Map , Collection 是一个存储一系列单个对象的容器,Map 是一个图,可以存储 一系列键值对。Collection 有三个子接口 List, Set, Queue
-
所以集合框架有四种具体的类型:Map, List, Set, Queue
-
List代表了有序可重复集合,可直接根据元素的索引来访问;Set代表无序不可重复集合,只能根据元素本身来访问;Queue是队列集合;Map代表的是存储键值对(key-value)的集合,可根据元素的key来访问value。
2.顶层接口
Iterator Iterable ListIterator
-
先来看我们经常用到的 Iterator 接口 和它的子接口 ListIterator
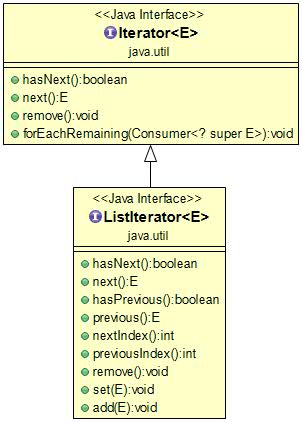
Iterator 有三个主要方法
-
hasNext() : 检测集合是否还有下一个元素
-
next() : 返回迭代器的下一个元素,并更新迭代器的游标(类似指针)
-
remove() : 将迭代器返回的元素删除
下面来通过例子来观察一下
public static void main(String[] args) { List<Integer> list = new ArrayList<>(); list.add(89); list.add(39); list.add(29); list.add(19); list.add(29); Iterator<Integer> it = list.iterator(); //获取迭代器 while(it.hasNext()){ Integer next = it.next(); System.out.print(next + " "); } Iterator<Integer> it2 = list.iterator(); while(it2.hasNext()){ if(it2.next() < 30){ it2.remove(); } } System.out.println(); Iterator<Integer> it3 = list.iterator(); //获取迭代器 while(it3.hasNext()){ Integer next = it3.next(); System.out.print(next + " "); } }输出结果为
89 39 29 19 29 89 39下面解释一下运行的过程,新建一个ArrayList集合,往里面添加了5个元素,第一次获取迭代器,遍历了集合,第二次获取迭代器,把集合里小于30的数删除,第三次再获取迭代器,再次遍历集合,发现小于30的数都被删除掉了。
-
下面来看一下ListIterator 接口,具体可以参考:Java 集合中关于Iterator 和ListIterator的详解
-
(1)ListIterator有**add()方法,可以向List中添加对象,而Iterator不能
(2)ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历,但是ListIterator有hasPrevious()和previous()**方法,可以实现逆向(顺序向前)遍历。Iterator就不可以。
(3)ListIterator可以定位当前的索引位置,**nextIndex()和previousIndex()**可以实现。Iterator没有此功能。
(4)都可实现删除对象,但是ListIterator可以实现对象的修改,set()方法可以实现。Iierator仅能遍历,不能修改。
-
最后来看一下Iterable接口
public interface Iterable<T> { Iterator<T> iterator(); /** * @since 1.8 */ default void forEach(Consumer<? super T> action) { Objects.requireNonNull(action); for (T t : this) { action.accept(t); } } default Spliterator<T> spliterator() { return Spliterators.spliteratorUnknownSize(iterator(), 0); } }可以看到其实里面也提供了Iterator接口,在JDK1.8之后,iterable提供foreach遍历,也就是我们经常用的增强for循环。但究其本质,增强for循环其实底层还是用迭代器遍历。
-
-
最后来小结一波
-
Iterator 是最常用的迭代器接口,主要提供了三个方法供我们去操作集合,hasNext(), next(), remove()。
-
ListIterator则可以称的上是Iterator的增强版,但它只可以对list集合操作,在Iterator的基础上,它还提供了add()方法,hasPrevious() 和 previous() 供我们后续遍历list集合,它还可以定位一个元素的索引和修改元素。
-
Iterable则提供了foreach遍历集合的方法。
3.Map集合
Map存储的是键值对<key, value> 形式的值, 每个key对应唯一一个value, 所以Map不可以有重复的key值,但存储重复的key值时,会将后来的 value 值覆盖掉原来的value值。也就是这个原因,作为key值得元素都必须重写hashcode()和equals()方法。
-
HashMap 和 HashTable
HashMap是最常用的一个实现类,当存入元素时,会将key的hashcode转化为数组的索引放入对应的数组位置,查找时以同样的方式查找。
HashTable一般都用不到了,操作方法和HashMap差不多,但性能比HashMap差,主要是底层实现导致的。HashTable有一个子类叫properties,是一个key和value都是String类型得Map,主要用于读取配置文件。
两者的区别:
- HashTable是线程安全的,HashMap是线程不安全的, HashTable底层实现的时候加了synchronized关键字。
- 底层实现时,HashTable是数组+链表,HashMap是数组+链表+红黑树, 具体是当链表长度大于8时会转为红黑树,因为这样查询效率会比原来快。
- HashMap可以用null作为key,而HashTable不可以
-
LinkedHashMap
LinkedHashMap是HashMap的子类,它内部有一条双向链表来维护键值对的次序,维护了Map的迭代顺序,与插入顺序一致,具体可以用来实现LRU缓存策略。
-
TreeMap
TreeMap有排序的功能,底层是数组+红黑树实现的,每一个键值对是一个树节点,默认按key值排序,因此key值必须实现Comparable接口。迭代的时候输出就是按照key值得默认顺序输出。
下面来例子演示一下
public static void main(String[] args) { Map<String, Integer> hashmap = new HashMap<>(); hashmap.put("Messi",6); hashmap.put("Ronaldo",5); hashmap.put("Kaka",1); hashmap.put("Modric",1); hashmap.put("Lingard",100); System.out.println("用HashMap: "); Set<Map.Entry<String, Integer>> set1 = hashmap.entrySet(); for(Map.Entry<String, Integer> s: set1){ System.out.println(s.getKey() +" "+s.getValue()); } Map<String, Integer> linkedHashMap = new LinkedHashMap<>(); linkedHashMap.put("Messi",6); linkedHashMap.put("Ronaldo",5); linkedHashMap.put("Kaka",1); linkedHashMap.put("Modric",1); linkedHashMap.put("Lingard",100); System.out.println("用LinkedHashMap: "); Set<Map.Entry<String, Integer>> set2 = linkedHashMap.entrySet(); for(Map.Entry<String, Integer> s: set2){ System.out.println(s.getKey() +" "+s.getValue()); } Map<String,Integer> treeMap = new TreeMap<>(); treeMap.put("Messi",6); treeMap.put("Ronaldo",5); treeMap.put("Kaka",1); treeMap.put("Modric",1); treeMap.put("Lingard",100); System.out.println("用TreeMap: "); Set<Map.Entry<String, Integer>> set3 = treeMap.entrySet(); for(Map.Entry<String, Integer> s: set3) { System.out.println(s.getKey() + " " + s.getValue()); } }用HashMap: Ronaldo 5 Lingard 100 Modric 1 Messi 6 Kaka 1 用LinkedHashMap: Messi 6 Ronaldo 5 Kaka 1 Modric 1 Lingard 100 用TreeMap: Kaka 1 Lingard 100 Messi 6 Modric 1 Ronaldo 5用HashMap会使遍历得时候变得无序,每次遍历得时候可能都会不一样,用LinkedHashMap
则严格按照添加顺序输出, 用TreeMap时则会将key值排序在输出。
4.Set集合
Set集合就是存储一系列不重复得元素,和Map有点像,就是少了value。
Set集合和基本上差不多,有几个具体得实现类,
HashSet,是基于HashMap 实现的,
** LinkedHashSet ,是基于LinkedHashMap实现的, **
TreeSet,是基于TreeMap实现的
操作除了没了value值,和Map差不多,存储的元素都要重写hashcode()和equals()方法。
5.List集合
常见的实现有ArrayList, LinkedList, Vector, Stack,
先说一下Vector和Stack, Stack是vector 的子类,它们都是线程安全的,也正是因为这一点,使得它们现在已经过时了。
- 现在主要来说一下ArrayList和LinkedList
ArrayList 类是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删除元素。
-

ArrayList 继承了 AbstractList ,并实现了 List 接口。
ArrayList 新建时默认容量为10,如果快达到了容量,就会有扩容机制将容量扩大到原来的1.5倍,所以如果我们创建ArrayList时知道要存储大小时最好指定一下大小,避免不断扩容而增大开销
LinkedList类似于 ArrayList,底层是用链表实现的,并实现了List, Deque, Cloneable, Serializable
接口,实现了Deque接口,说明Deque可以当作双端队列来使用,也就是说,既可以当作“栈”使用,又可以当作队列使用。

关于两者的区别
以下情况使用 ArrayList :
- 频繁访问列表中的某一个元素。
- 只需要在列表末尾进行添加和删除元素操作。
以下情况使用 LinkedList :
-
你需要通过循环迭代来访问列表中的某些元素。
-
需要频繁的在列表开头、中间、末尾等位置进行添加和删除元素操作。
6.Queue集合
主要分为单向队列和双端队列,双端队列就是实现Deque接口,最常见的就是上面所说的LinkedList, 单向队列主要介绍优先队列PriorityQueue。
- 下面先来看JDK为我们提供的双端队列方法
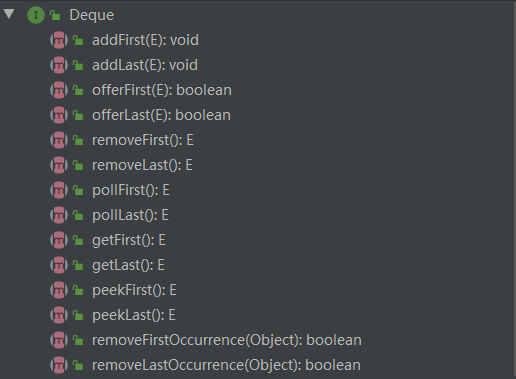
细心的朋友可能会发现,API为每种操作都提供两种方法,那么它们有什么不同呢,调用不同方法操作失败时,结果也会不同。
| 失败结果 | 添加 | 删除 | 查找 |
|---|---|---|---|
| 抛出异常 | add() | remove() | get() |
| False | offer() | poll() | peek() |
实现双端队列的除了LinkedList, 还有ArrayDeque, 两者的区别和LinkedList和ArrayList的区别有点像,都是一个底层是链表,一个是数组。用的不多
-
最后讲一下单向队列的PriorityQueue
PriorityQueue是基于优先堆实现的,优先队列,顾名思义它可以根据优先级来进行排序
要求添加的元素实现Comparable接口,并不可以存NULL值
下面来个例子演示一下
先定义了一个Player类,实现Comparable接口,并重写了CompareTo方法
public static void main(String[] args) { Queue<Player> players = new PriorityQueue<>(); Player p1 = new Player("Ronaldo", 93); Player p2 = new Player("Messi",94); Player p3 = new Player("Neymar",92); Player p4 = new Player("lewandovsiki",91); Player p5 = new Player("Lingard",100); players.add(p1); players.add(p2); players.add(p3); players.add(p4); players.add(p5); while (!players.isEmpty()){ Player p = players.poll(); System.out.println(p); } }
Player{name='Lingard', ability=100}
Player{name='Messi', ability=94}
Player{name='Ronaldo', ability=93}
Player{name='Neymar', ability=92}
Player{name='lewandovsiki', ability=91}
会发现输出顺序和ability有关,这是因为内部已经根据CompareTo方法排好序了,也就是根据ability为优先级了。
最后献上一个表格来总结一下
| 实现类 | 增删复杂度 | 查复杂度 | 底层数据结构 | 线程安全 |
|---|---|---|---|---|
| Vector | O(N) | O(1) | 数组 | 是(过时) |
| ArrayList | O(N) | O(1) | 数组 | 否 |
| LinkedList | O(1) | O(N) | 双向链表 | 否 |
| HashSet | O(1) | O(1) | 数组+链表+红黑树 | 否 |
| TreeSet | O(logN) | O(logN) | 红黑树 | 否 |
| LinkedHashSet | O(1) | O(1)~O(N) | 数组 + 链表 + 红黑树 | 否 |
| ArrayDeque | O(N) | O(1) | 数组 | 否 |
| PriorityQueue | O(logN) | O(logN) | 堆(数组实现) | 否 |
| HashTable | O(1) / O(N) | O(1) / O(N) | 数组+链表 | 是(过时) |
| HashMap | O(1) ~ O(N) | O(1) ~ O(N) | 数组+链表+红黑树 | 否 |
| TreeMap | O(logN) | O(logN) | 数组+红黑树 | 否 |
| HashTable | O(1) / O(N) | O(1) / O(N) | 数组+链表 | 是(过时) |
| HashMap | O(1) ~ O(N) | O(1) ~ O(N) | 数组+链表+红黑树 | 否 |
| TreeMap | O(logN) | O(logN) | 数组+红黑树 | 否 |














 1724
1724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









