







如果你对数据结构了解不深,又想要学习普里姆算法,建议你看看我这篇,我尽量往细致的方向写,如果有些大佬认为我写的比较啰嗦,请见谅,毕竟我的目的是为了让数据结构小白能够在理解普里姆算法上相对容易一些。由于为了清楚地说明普里姆算法,可能会牺牲一些严谨性,但只讲严谨的术语会加大理解难度,尤其对于非科班出身的人。如遇大佬,请勿喷。
发文的目的
我个人学习图结构已经有相当长一段时间了,图这块对于初学者来说真的相当难学,建议在学习数据结构之前先修计算机数学或者离散数学。我学习数据机构是为了毕业设计服务,本身并非计算机出身,学起来有难度。主要是为路径规划服务。非科班出身可以参考一下我的学习经验。
全文结构
由于要详解,全文的内容可能会比较长,先做个提纲,可以从自己需要的部分看下去,不过建议从头看。
- 图结构的必要了解知识
- 普里姆算法简介
- 算法详解
- 总结
1、树的必要了解知识
图结构是一种非线性数据结构,每个节点都可能有不止一个前驱和后继,这是它不同于树的地方。树的术语极多,要注意理解。关于树的存储,至少要理解邻接矩阵法。推荐的视频有小甲鱼的《数据结构》和入门书籍《大话数据结构》。建议初学者结合起来看。这里简单说一下要用到的概念。树的邻接矩阵存储方式,采用一个一维数组存储顶点,一个二维数组存储各边上的权值,两个顶点非连通则使用∞表示,在程序中使用一个所有边的权值都不可能达到的一个较大的数,例如65535,。自身到自身的顶点的边的权值用0表示。其他必要信息,例如顶点数,边数,可以用整型数表示。讲到这里,我们很自然地想到用一个结构体变量来定义和存储数结构。
2、普里姆算法简介
普里姆算法是用来解决求图的最小生成树的经典算法。即求连通图的n个顶点的n-1条边的权值之和最小。使用这个算法有个称之为MST的性质,首先假设实际网N(带权图)是一个连通网(从图的任意一个顶点出发,都能到达其他的顶点),对于网N,已经找到的最小生成树的顶点必然是最终的最小生成树的顶点,说简单一点,就是你已经找到顶点V3是当前的最小生成树的顶点,这个点你可以不用找了,放心大胆地找其余的点,不会有更优的路径。这一点详见严蔚敏老师《数据结构》。如果你对图结构有一定了解但不熟悉,从这里开始看。
关于普里姆算法的流程。它的大致步骤如下:
1、从任意一个顶点开始(一般是第一个顶点),搜索与它相关联的顶点的最小权值的边,把这个顶点纳入保存已经找到的最小生成树的顶点的集合中,边并入最小生成树边的集合,这个顶点以后不再继续搜索;
2、从找到的这个顶点开始,用之前的顶点的边权值修正这个顶点的边权值,取两者之中最小的。
3、从修正后的顶点中继续找最小权值的边,保存顶点和边到最小生成树的点集和边集中。
4、重复步骤2,3,直到最小生成树的顶点集达到图的顶点数停止。
普里姆算法本质上是图的遍历和求最小值。但它既不是深度优先算法,也不是广度优先算法,结合实例会理解的更深刻一些。
3、算法详解
有了前面的铺垫,再继续讲会更容易理解一些,如果你已经学习过图结构,但是对于普里姆算法又不是很理解,很会用。建议从这里开始看起。
结合实例来说明普里姆算法。实例来源于《大话数据结构》,如果想详细了解,可以阅读原文。问题描述如下:如下图,求最小生成树
邻接矩阵
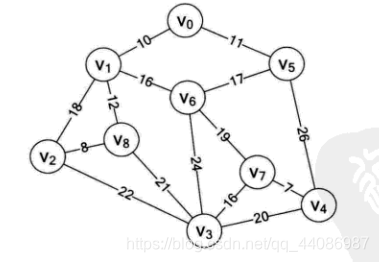
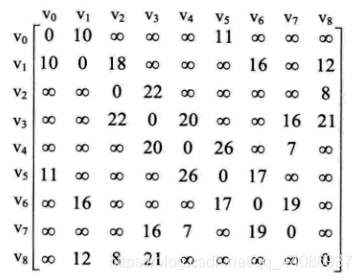
对下面的代码做入下解释
∞–INF;
由于本例中的图是无向图,它的邻接矩阵是对称阵,所以可以输入其中一半,另一半直接赋值。对于稀疏图,可以采用把邻接矩阵的所有元素都赋值为INF,然后把相互连通的顶点的边权值赋值。lowcost数组存放当前正在搜索的边权值,adjvex数组存放已经找到的最小生成树顶点。
代码的主要流程
- 将lowcost数组初始化为图的与第一个顶点V0相关联的边的权值,将第一个顶点V0纳入最小生成树的顶点,这个点对应的列权值以后不再搜索;
- 搜索lowcost数组中的最小值(v1),记下最小值的标号给k(1),这个点将作为找到变的终点(后继)以后的lowcost的第0和1个元素不在搜索(置0),做记号,而搜索其余的元素2,3,…,8;
- 更新lowcost,把和新找到的这个顶点(v1)相关联的边的权值(0,1不再参与搜索)和lowcost数组的对应元素作比较,找出更小的权值,保存在lowcost中,从图中来看就是,从已经找到的顶点(V0,V1)向下搜索,找最小值,如果一个顶点和两个已经找出的顶点都相连通,那么取两条边权值较小的那一个。并把k对应的值作为找到的边的起点(前驱)。
- 重复2,3过程,直到所有的顶点都被遍历,即所有的lowcost都被置0;
在这里对比较难细节性的问题再做一下说明。主要是第二个for循环那里,他做了两件事,一是用找到的这一个新的顶点(k)的这一顶点的所有边去更新lowcost。如果你愿意的话,你可以用普里姆算法的流程在人脑里执行这个过程。举个例子,在我们已经找到v0,v1之后的下一步,你要查找和v0,v1相关联的边{(v0,v5),(v1,v2),(v1,v6),(v1,v8)},这个更新的过程对人来说的流程是先从v0找起,找到和它相关联的边,再找v1。但对于计算机来说就不是这样,它不管你是v0还是v1,把v0和v1的值都比较一番,谁小就取谁,显然(v0,v5)小,不仅如此,每次把比较之后修改的值也做上记号,好知道他是来自哪里的数据,比如,经过比较,发现(v1,v2)小,把它的顶点信息记在adjvex[2](1)里面,作为前驱。人和计算机的逻辑差别有点像两种招人方式,有的单位招人看学校和成绩,有的公司看能力,不管你的学校和学历,只要你干得好,初中我都要。
总结一下,普里姆算法就干了三件事。第一,更新lowcost,始终都把当前能找到的最小路径放在里面,而且记下被修改的数据的顶点信息,以方便后面找它的根(前驱)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









