






-
二叉树
-
红黑树(平衡二叉树)
-
hash
-
B-Tree(多路平衡二叉树)
-
四种数据结构做mysql各有什么优缺点
-
实际官方用的是B+Tree和B-Tree有什么区别?
-
B-Tree将data也存在了树上
-
B+Tree将data存在了子节点,根节点只允许16k,并且在在叶子节点做了冗余,H=3,可以支撑的索引为估算16k/14b(根节点bigint数据8b,指针6b)=1170
-
三层就是1170x1170x16约2000w条索引
-
在叶子节点也是有指针的
感悟:空间换时间,多做了冗余,加了复杂的规则,空间占用的多了,时间就会降下来.
类比于静态语言和解释型语言,在写代码的时候让人判断的多了加了一些约束的写法,性能自然会高,让机器代码自己去判断,性能自然会低.
- innodb存储引擎(表级别的)
frm文件:数据表结构的信息
MYD文件:行信息
MYI:索引 B+Tree
- Innodb存储一引擎:
- frm文件:数据表结构的额信息
- ibd文件:将索引和数据元素进行合并 (B+Tree组织的索引结构文件)
聚集索引:主键索引就是聚集索引(索引和文件聚集在一起)(innodb)
非聚集索引:两个文件,不放在一起
- 为什么innodb表必须有主键,并且自增?
如果没有建立主键则默认给你建立一个id或者选择一个id,索引,来维护所有数据
为什么用整形自增UUID()(一长串字符串) UUID占用的空间大,要逐个比较大小很消耗资源要转换为ASCII,然后查表去比
- 引入数据结构与算法,Python中集合比list在查找效率更高
hash表(乱序)和二叉树(有序的)
python:dict就是hashmap
-
要用其他的可以用第三方的高级的数据结构
-
字典进来进行排序 比较排序好的单词
-
map用来计数 字母对应次数,放在map里面进行计数
-
map快于排序
-
sorted:快排
-
{}用hash表来实现
-
手动创建hash表
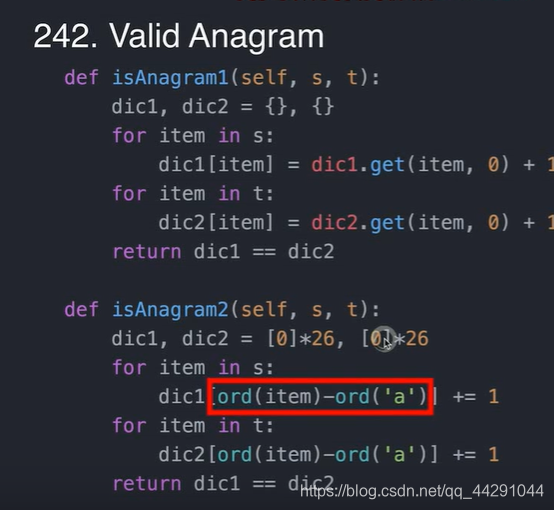
- two sum three sum用map实现
树,二叉搜索树,图
链表和树(从链表分叉出来)
分层打印二叉树
指回去(图) 最短路径(工程上用的比较少)
链表就是特殊化的树, 树是特殊化的图
- python实现二叉树
class TreeNode:
def __init__(self, var):
self.val = val
self.left, self.right = None, None
- 左右子树有顺序(二叉搜索树),平衡二叉搜索树,红黑树
二叉搜索树:左子树小于根节点的值,
右子树大于根节点
注意是所有的都是,不论第几级别的根
查询更加方便(少了一半的数据量)
从n到logn 搜索更加有效率
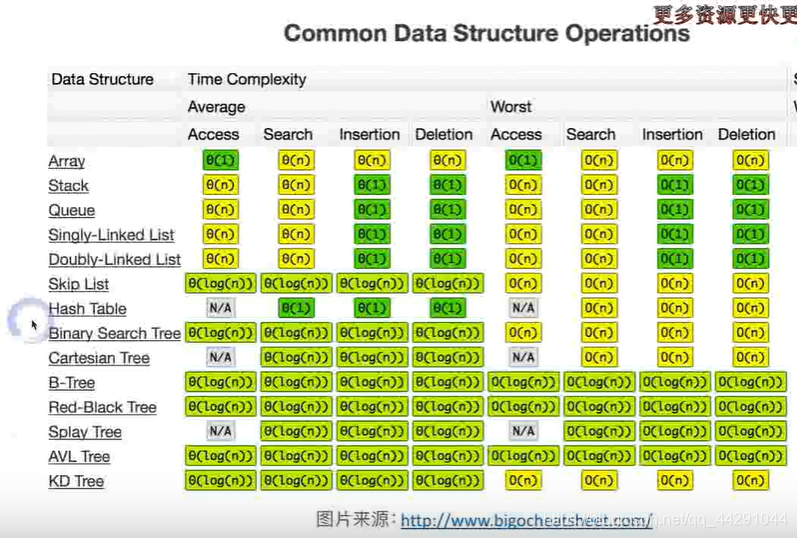
平均是logn 最坏的是n
红黑树:平衡二叉搜索树(java,c++内置的二叉树都是红黑树)
判断一个树是否是二叉排序树
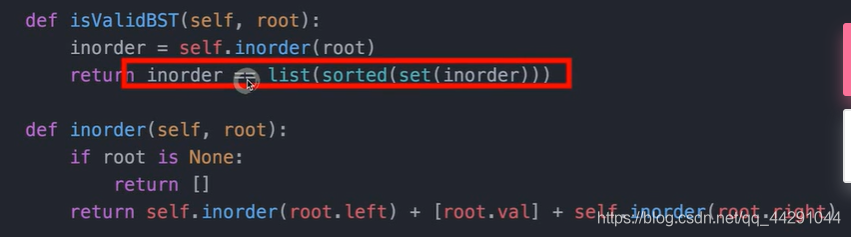
根的位置:在左,中,右 前中后
自己调用自己的就是递归:不停止的递归就会死循环,要有个退出的条件
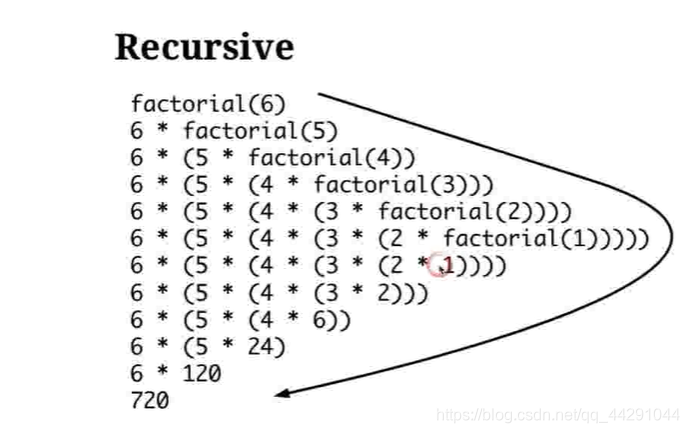
递归的思想
- 斐波那契数列用递归写














 1958
1958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









