









SR研究(1)RCAN论文阅读上
阅读论文:Image Super-Resolution Using Very Deep Residual Channel Attention Networks
RCAN网络主要的成就为提出了RIR结构用于构建深层次的网络从而提高视觉识别的效果,利用模型抓取高频信息并且和低频信息结合从而提高分辨率。此外还在低分辨率图像任务中首次引入了注意力机制,通过通道注意力来调整资源分配给信息更丰富的区域,提高分辨率改进效果。
1. Introduction(引言部分)
We address the problem of reconstructing an accurate high-resolution (HR) image given its low-resolution (LR) counterpart, usually referred as single image super-resolution (SR) [8]. Image SR is used in various computer vision applications, ranging from security and surveillance imaging [45], medical imaging [33] to object recognition [31]. However, image SR is an ill-posed problem, since there exists multiple solutions for any LR input. To tackle such an inverse problem, numerous learning based methods have been proposed to learn mappings between LR and HR image pairs.
SR是不适定问题,对应的每一幅LR图像都可以有多幅HR图像相对应。

Recently, deep convolutional neural network (CNN) based methods [5, 6, 10, 16,19,20,23,31,34,35,39,42–44] have achieved significant improvements over conventional SR methods. Among them, Dong et al. [4] proposed SRCNN by firstly introducing a three-layer CNN for image SR. Kim et al. increased the network depth to 20 in VDSR [16] and DRCN [17], achieving notable improvements over SRCNN. Network depth was demonstrated to be of central importance for many visual recognition tasks, especially when He at al. [11] proposed residual net (ResNet). Such effective residual learning strategy was then introduced in many other CNN-based image SR methods [21, 23, 31, 34, 35]. Lim et al. [23] built a very wide network EDSR and a very deep one MDSR by using simplified residual blocks. The great improvements on performance of EDSR and MDSR indicate that the depth of representation is of crucial importance for image SR. However, to the best of our knowledge, simply stacking residual blocks to construct deeper networks can hardly obtain better improvements. Whether deeper networks can further contribute to image SR and how to construct very deep trainable networks remains to be explored.
EDSR,MDSR很好地说明了网络深度对于图像识别任务的重要性。并且简单地叠加剩余块来构建更深的网络很难获得更好的改善。更深层次的网络是否能够进一步促进图像SR,以及如何构建非常深入的可训练网络,还有待于探索。
On the other hand, most recent CNN-based methods [5, 6, 16, 19, 20, 23, 31, 34, 35, 39, 43] treat channel-wise features equally, which lacks flexibility in dealing with different types of information. Image SR can be viewed as a process, where we try to recover as more high-frequency information as possible. The LR images contain most low-frequency information, which can directly forwarded to the final HR outputs. While, the leading CNN-based methods would treat each channel-wise feature equally, lacking discriminative learning ability across feature channels, and hindering the representational power of deep networks.
SR技术核心是抓取高频信息进行恢复,而LR图像中还会有大量的低频信息,这些信息往往会直接被发送到最终的高分辨率图像的输出。但是当前主流的深度神经网络并没有对不同通道的加以区分,都是平等的,因此缺乏跨特征通道的区分学习能力,阻碍了深层网络的表现力。
To practically resolve these problems, we propose a residual channel attention network (RCAN) to obtain very deep trainable network and adaptively learn more useful channel-wise features simultaneously. To ease the training of very deep networks (e.g., over 400 layers), we propose residual in residual (RIR) structure, where the residual group (RG) serves as the basic module and long skip connection (LSC) allows residual learning in a coarse level. In each RG module, we stack several simplified residual block [23] with short skip connection (SSC). The long and short skip connection as well as the short-cut in residual block allow abundant low-frequency information to be bypassed through these identity-based skip connections, which can ease the flow of information. To make a further step, we propose channel attention (CA) mechanism to adaptively rescale each channel-wise feature by modeling the interdependencies across feature channels. Such CA mechanism allows our proposed network to concentrate on more useful channels and enhance discriminative learning ability. As shown in Figure 1, our RCAN achieves better visual SR result compared with state-of-the-art methods.
文章提出了一种剩余信道注意网络(RCAN),以获得非常深的可训练网络,同时自适应地学习更多有用的信道特性。为了简化超深网络(例如400层以上)的训练,文章提出了残差中残差(RIR)结构,其中残差群(RG)作为基本模块,长跳连接(LSC)允许在粗层次上进行残差学习。在每个RG模块中,文章使用短跳连接(SSC)堆叠几个简化的剩余块。长跳转和短跳转连接以及剩余块中的短跳转连接允许通过这些基于身份的跳转连接绕过大量的低频信息,从而简化信息的流动。为了更进一步,文章提出了通道注意(CA)机制,通过对特征通道间的相互依赖性进行建模,自适应地调整每个通道的特征。这种CA机制使得文章提出的网络能够集中在更多有用的信道上,并增强区分学习能力。与最先进的方法相比,文章的RCAN实现了更好的视觉SR结果。
Overall, our contributions are three-fold: (1) We propose the very deep residual channel attention networks (RCAN) for highly accurate image SR. (2) We propose residual in residual (RIR) structure to construct very deep trainable networks. (3) We propose channel attention (CA) mechanism to adaptively rescale features by considering interdependencies among feature channels.
RCAN贡献:
(1)提出了非常深的剩余通道注意网络(RCAN)来实现高精度的图像SR。
(2)提出了残差中的剩余(RIR)结构来构建非常深的可训练网络。
(3) 提出了通道注意(CA)机制,通过考虑特征通道之间的相互依赖性来自适应地重新缩放特征。
2. Related Work(相关工作)
- Deep CNN for SR
The pioneer work was done by Dong et al. [4], who proposed SRCNN for image SR and achieved superior performance against previous works. SRCNN was further improved in VDSR [16] and DRCN [17]. These methods firstly interpolate the LR inputs to the desired size, which inevitably loses some details and increases computation greatly. Extracting features from the original LR inputs and upscaling spatial resolution at the network tail then became the main choice for deep architecture. A faster network structure FSRCNN [6] was proposed to accelerate the training and testing of SRCNN. Ledig et al. [21] introduced ResNet [11] to construct a deeper network with perceptual losses [15] and generative adversarial network (GAN) [9] for photo-realistic SR. However, most of these methods have limited network depth, which has demonstrated to be very important in visual recognition tasks [11]. Furthermore, most of these methods treat the channel-wise features equally, hindering better discriminative ability for different features.
开山之作SRCNN,在之后的CDSR,DRCN等网络中被改进,这些方法首先将LR输入值插值到所需的大小,这样不可避免地会丢失一些细节并大大增加计算量。从原始LR输入中提取特征并在网络尾部提升空间分辨率成为深层次体系结构的主要选择。 此后的ResNet,SRGAN等大多具有有限的网络深度,这在视觉识别任务中非常重要。此外,这些方法中的大多数方法都是平等对待信道特征的,从而阻碍了对不同特征更好的区分能力。
- Attention mechanism
Generally, attention can be viewed as a guidance to bias the allocation of available processing resources towards the most informative components of an input [12]. Recently, tentative works have been proposed to apply attention into deep neural networks [12, 22, 38], ranging from localization and understanding in images [3, 14] to sequence-based networks [2, 26]. It’s usually combined with a gating function (e.g., sigmoid) to rescale the feature maps. Wang et al. [38] proposed residual attention network for image classi- fication with a trunk-and-mask attention mechanism. Hu et al. [12] proposed squeeze-and-excitation (SE) block to model channel-wise relationships to obtain significant performance improvement for image classification. However, few works have been proposed to investigate the effect of attention for low-level vision tasks (e.g., image SR).
注意力机制在网络中起到引导资源分配的作用,会将资源偏向输入信息丰富的部分。注意力机制在HR层面的应用已经不少,但是在LR的图像识别中的应用还很少。
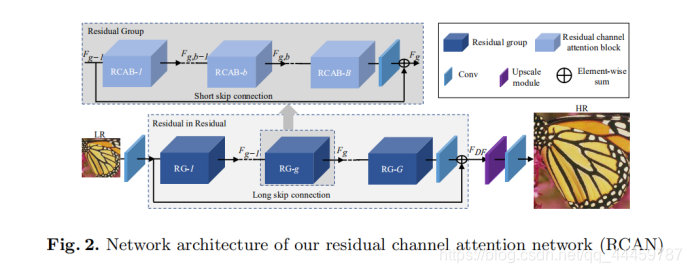
3. Residual Channel Attention Network (RCAN)
- Network Architecture
As shown in Figure 2, our RCAN mainly consists four parts: shallow feature extraction, residual in residual (RIR) deep feature extraction, upscale module, and reconstruction part. Let’s denote ILR and ISR as the input and output of RCAN. As investigated in [21, 23], we use only one convolutional layer (Conv) to extract the shallow feature F0 from the LR input
F0 = HSF (ILR), (1)
where HSF (·) denotes convolution operation. F0 is then used for deep feature extraction with RIR module. So we can further have
FDF = HRIR (F0), (2)
where HRIR (·) denotes our proposed very deep residual in residual structure, which contains G residual groups (RG). To the best of our knowledge, our proposed RIR achieves the largest depth so far and provides very large receptive field size. So we treat its output as deep feature, which is then upscaled via a upscale module
FUP = HUP (FDF ), (3)
where HUP (·) and FUP denote a upscale module and upscaled feature respectively.
ISR = HREC (FUP ) = HRCAN (ILR), (4)
where HREC (·) and HRCAN (·) denote the reconstruction layer and the function of our RCAN respectively.
RCAN的主要结构分为四个部分:
(1)浅层特征提取
(2)RIR深度特征提取
(3)upscale模块
(4)重构部分
将原始输入的LR图像通过HSF浅层提取,输出通过HRIR进行深度学习,把该输出作为深特征通过upscale放大。
There’re several choices to serve as upscale modules, such as deconvolution layer (also known as transposed convolution) [6], nearest-neighbor upsampling + convolution [7], and ESPCN [32]. Such post-upscaling strategy has been demonstrated to be more efficient for both computation complexity and achieve higher performance than pre-upscaling SR methods (e.g., DRRN [34] and MemNet [35]). The upscaled feature is then reconstructed via one Conv layer
upscale模块的可选择策略有很多,有去卷积层(也称为转置卷积)、最近邻上采样+卷积、ESPCN等。这种后向上扩展策略已经被证明在计算复杂度和性能上比升级前的SR方法(例如DRRN和MemNet)更有效。
Then RCAN is optimized with loss function. Several loss functions have been investigated, such as L2 [5, 6, 10, 16, 31, 34, 35, 39, 43], L1 [19, 20, 23, 44], perceptual and adversarial losses [21, 31]. To show the effectiveness of our RCAN, we choose to optimize same loss function as previous works (e.g., L1 loss function). Given a training set Ii LR, Ii HR Ni=1, which contains N LR inputs and their HR counterparts. The goal of training RCAN is to minimize the L1 loss function
where Θ denotes the parameter set of our network. The loss function is optimized by using stochastic gradient descent. More details of training would be shown in Section 4.1. As we choose the shallow feature extraction HSF (·), upscaling module HUP (·), and reconstruction part HUP (·) as similar as previous works (e.g., EDSR [23] and RDN [44]), we pay more attention to our proposed RIR, CA, and the basic module RCAB.
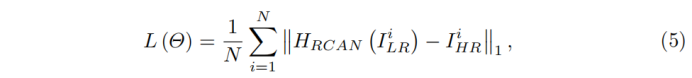
RCAN在损失函数上并没有做出改变,而是选择了与先前工作相同的loss函数,训练RCAN的目标是最小化L1损失函数。(PS这一点也不失为RCAN的改进方向之一,因为在EDSR网络的论文中有提出L2相较L1更适合低分辨率的图像识别问题)。参数集的优化方式是梯度下降。
- Residual in Residual (RIR)
It has been demonstrated that stacked residual blocks and LSC can be used to construct deep CNN in [23]. In visual recognition, residual blocks [11] can be stacked to achieve more than 1,000-layer trainable networks. However, in image SR, very deep network built in such way would suffer from training difficulty and can hardly achieve more performance gain. Inspired by previous works in SRRestNet [21] and EDSR [23], we proposed residual group (RG) as the basic module for deeper networks. A RG in the g-th group is formulated as
Fg = Hg (Fg 1) = Hg (Hg 1 (· · · H1 (F0)· · ·)), (6)
where Hg denotes the function of g-th RG. Fg 1 and Fg are the input and output for g-th RG. We observe that simply stacking many RGs would fail to achieve better performance. To solve the problem, the long skip connection (LSC) is further introduced in RIR to stabilize the training of very deep network. LSC also makes better performance possible with residual learning via
FDF = F0 + WLSC FG = F0 + WLSCHg (Hg 1 (· · · H1 (F0)· · ·)), (7)
where WLSC is the weight set to the Conv layer at the tail of RIR. The bias term is omitted for simplicity. LSC can not only ease the flow of information across RGs, but only make it possible for RIR to learning residual information in a coarse level.
利用叠加残差块和LSC可以构造deep很大的CNN网络,但是对于SR来说,这样子构建的1000多层的可训练网络的训练难度很大,并且得到的性能增益不高。文章在SRResNet和EDSR中得到启发,利用剩余群(RG)作为更深层网络的基本模块。并且,简单的堆叠RG效果不好,因此还使用了LSC来稳定超深网络的堆叠。LSC还可以通过剩余学习实现更好的性能。其中,WLSC是RIR尾部的Conv层的权重层。为了简单起见,省略了偏差项。LSC不仅可以简化信息在RGs间的流动,而且可以使RIR在粗略的层次上学习剩余信息。
As discussed in Section 1, there are lots of abundant information in the LR inputs and features and the goal of SR network is to recover more useful information. The abundant low-frequency information can be bypassed through identity-based skip connection. To make a further step towards residual learning, we stack B residual channel attention blocks in each RG. The b-th residual channel attention block (RCAB) in g-th RG can be formulated as
Fg,b = Hg,b (Fg,b 1) = Hg,b (Hg,b 1 (· · · Hg,1 (Fg 1)· · ·)), (8)
where Fg,b 1 and Fg,b are the input and output of the b-th RCAB in g-th RG. The corresponding function is denoted with Hg,b. To make the main network pay more attention to more informative features, a short skip connection (SSC) is introduced to obtain the block output via
Fg = Fg 1 + WgFg,B = Fg 1 + WgHg,B (Hg,B 1 (· · · Hg,1 (Fg 1)· · ·)), (9)
where Wg is the weight set to the Conv layer at the tail of g-th RG. The SSC further allows the main parts of network to learn residual information. With LSC and SSC, more abundant low-frequency information is easier bypassed in the training process. To make a further step towards more discriminative learning, we pay more attention to channel-wise feature rescaling with channel attention.
为了进一步实现剩余学习,文章在每个RG中堆叠B个剩余信道注意块。第g个RG中的第b剩余信道注意块(RCAB)可以表示为Fg,b。为了使主网更加关注信息量更大的特征,引入短跳连接(SSC)来获得块输出。SSC进一步允许网络的主要部分学习剩余信息。利用LSC和SSC,在训练过程中更容易绕过更丰富的低频信息。为了使学习更具区分性,文章将更多的注意力放在基于信道的特征重定标上。
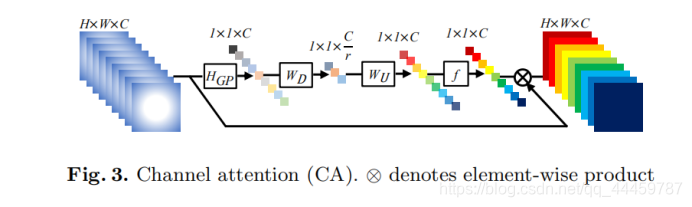
- Channel Attention (CA)
Previous CNN-based SR methods treat LR channel-wise features equally, which is not flexible for the real cases. In order to make the network focus on more informative features, we exploit the interdependencies among feature channels, resulting in a channel attention (CA) mechanism (see Figure 3).
以往的CNN网络结构都是平等地对待所有通道信息的,这并不灵活。文章网络模型则是利用通道之间的相互依赖性形成了一种通道注意(CA)机制。
How to generate different attention for each channel-wise feature is a key step. Here we mainly have two concerns: First, information in the LR space has abundant low-frequency and valuable high-frequency components. The lowfrequency parts seem to be more complanate. The high-frequency components would usually be regions, being full of edges, texture, and other details. On the other hand, each filter in Conv layer operates with a local receptive field. Consequently, the output after convolution is unable to exploit contextual information outside of the local region.
如何生成不同的注意力则是注意力机制应用的关键步骤。注意到:
(1)LR图像中包含了低频信息和高频信息,低频信息更为平坦,高频信息则相较而言充满了边缘、纹理和其他细节。
(2)每一个filter都对应了一块区域,经过卷积之后无法利用这块区域以外的信息。
Based on these analyses, we take the channel-wise global spatial information into a channel descriptor by using global average pooling. As shown in Figure 3, let X = [x1, · · · , xc, · · · , xC ] be an input, which has C feature maps with size of H × W. The channel-wise statistic z ∈ RC can be obtained by shrinking X through spatial dimensions H ×W. Then the c-th element of z is determined by
where xc (i, j) is the value at position (i, j) of c-th feature xc. HGP (·) denotes the global pooling function. Such channel statistic can be viewed as a collection of the local descriptors, whose statistics contribute to express the whole image [12]. Except for global average pooling, more sophisticated aggregation techniques could also be introduced here.
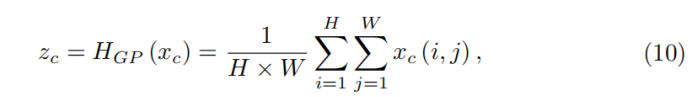
利用全局平均池化将通道全局空间信息转化为通道描述符。利用公式将HWC的feature map转化为一个X向量,这种通道统计可以看作是局部描述符的集合,它们的统计信息有助于表示整个图像。除了全局平均池化,这里还可以引入更复杂的聚合技术。(也是一个RCAN的通道注意力模块的改进点)
To fully capture channel-wise dependencies from the aggregated information by global average pooling, we introduce a gating mechanism. As discussed in [12], the gating mechanism should meet two criteria: First, it must be able to learn nonlinear interactions between channels. Second, as multiple channelwise features can be emphasized opposed to one-hot activation, it must learn a non-mututually-exclusive relationship. Here, we opt to exploit simple gating mechanism with sigmoid function
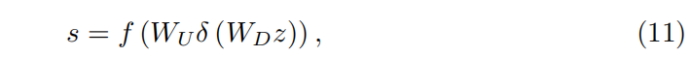
为了通过全局平均池从聚合信息中完全捕获信道依赖,文章引入了一种gating机制。该机制满足两个标准:
(1)能够学习通道之间的非线性相互作用。
(2)features可以是一个多通道特性,而非单单一个one-hot编码的 activation(这一点并没有很好的弄懂,可能是one-hot编码会导致通道之间独立)
where f (·) and δ (·) denote the sigmoid gating and ReLU [27] function, respectively. WD is the weight set of a Conv layer, which acts as channel-downscaling with reduction ratio r. After being activated by ReLU, the low-dimension signal is then increased with ratio r by a channel-upscaling layer, whose weight set is WU . Then we obtain the final channel statistics s, which is used to rescale the input xc
WD是Conv层的权重集,其作用是用缩减比r进行信道进行channel-downscaling。低维信号被ReLU激活后,由一个权重集为WU的信道上尺度层以比率r增加。然后我们得到最终的信道统计信息s,用于重新缩放输入xc。
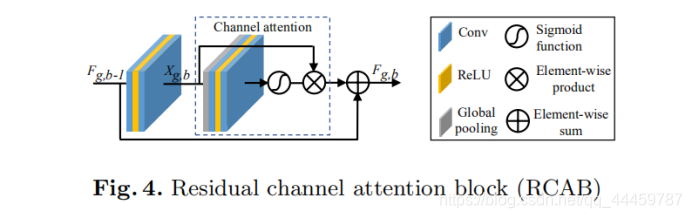
- Residual Channel Attention Block (RCAB)
As discussed above, residual groups and long skip connection allow the main parts of network to focus on more informative components of the LR features.
Channel attention extracts the channel statistic among channels to further enhance the discriminative ability of the network. At the same time, inspired by the success of residual blocks (RB) in [23], we integrate CA into RB and propose residual channel attention block (RCAB) ( see Figure 4). For the b-th RB in g-th RG, we have
Fg,b = Fg,b 1 + Rg,b (Xg,b) · Xg,b, (13)
where Rg,b denotes the function of channel attention. Fg,b and Fg,b 1 are the input and output of RCAB, which learns the residual Xg,b from the input. The residual component is mainly obtained by two stacked Conv layers
Xg,b = W2 * g,bδ W1 *g,bFg,b 1 , (14)
where W1 g,b and W2 g,b are weight sets the two stacked Conv layers in RCAB.
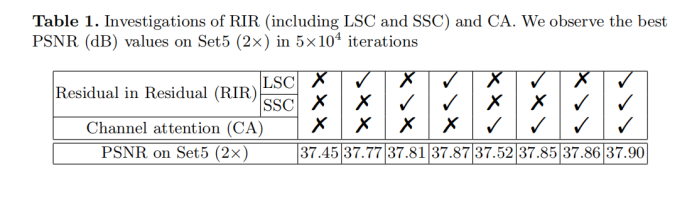
文章实验证实了CA模块以及LSC,SSC在RIR中应用的实际作用——PSNR指标有提高。
We further show the relationships between our proposed RCAB and residual block (RB) in [23]. We find that the RBs used in MDSR and EDSR [23] can be viewed as special cases of our RCAB. For RB in MDSR, there is no rescaling operation. It is the same as RCAB, where we set Rg,b (·) as constant 1. For RB with constant rescaling (e.g., 0.1) in EDSR, it is the same as RCAB with Rg,b (·) set to be 0.1. Although the channel-wise feature rescaling is introduced to train a very wide network, the interdependencies among channels are not considered in EDSR. In these cases, the CA is not considered.
文章发现了EDSR,MDSR中使用RB的原理可以看做是RCAB的一个特殊情况,即缩减比r为1的特殊情形。虽然在EDSR中引入了信道特性重定标来训练非常宽的网络,但是EDSR没有考虑通道间的相互依赖性。(也就是意味着RCAN的网络中RCAB可以借鉴EDSR网络的优点加以改进)
Based on residual channel attention block (RCAB) and RIR structure, we construct a very deep RCAN for highly accurate image SR and achieve notable performance improvements over previous leading methods. More discussions about the effects of each proposed component are shown in Section 4.2.
基于剩余信道注意块(RCAB)和RIR结构,文章构造了一个用于高精度图像SR的非常深的RCAN,并在性能上取得了显著的改进。














 1485
1485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









