







数据结构总目录
(一)冒泡排序
1. 图文解析
冒泡排序就是依次比较一个序列中相邻的两个数据大小,通过不断地交换数据的位置来将最大或者最小的数据依次交换到最后面的位置,从而达到数据排序的排序方法。
排序过程
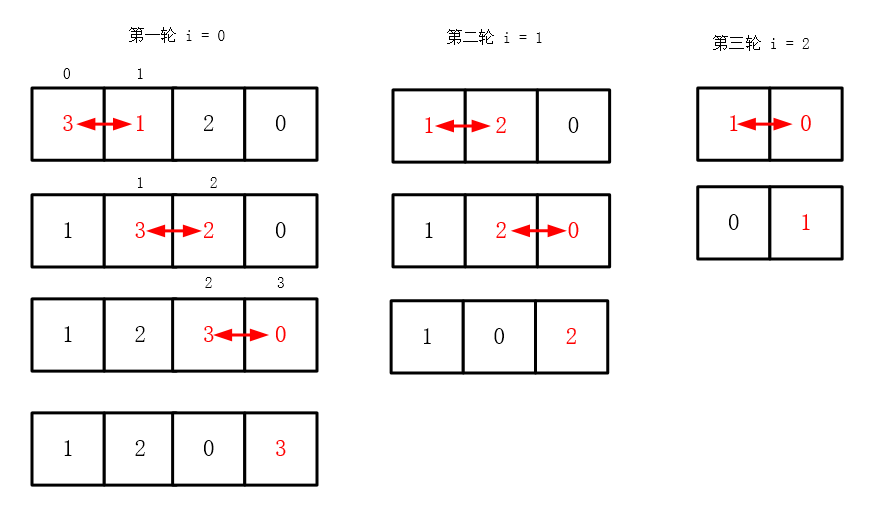
排序用例: { 3 1 2 0 }
第一轮:完成数字3的排序
比较(3 > 1) 进行交换{ 1 3 2 0 }
比较(3 > 2) 进行交换{ 1 2 3 0 }
比较(3 > 0) 进行交换{ 1 2 0 3 }
第二轮:完成数字2的排序
比较(1 < 2) 无需交换{ 1 2 0 }
比较(2 > 0) 进行交换{ 1 0 2 }
第三轮:完成数字1的排序
比较(1 > 0) 进行交换{ 0 1 }
排序完毕
2. 源代码
#include <stdio.h>
#define size 10
int main()
{
int i, j, temp, round = 0, count = 0;
int num[size] = {5, 243, 42, 123, 55, 56, 32, 23, 78, 324};
for(i = 0; i < size - 1; i++) // 排序轮次
{
// 1. 每一轮都将会完成其中一个数据的排序(size - i)
// 2. 对于最后一个数据没有后继数据可比较(size - i - 1)
for (j = 0; j < size - i - 1; j++)
{
if (num[j] > num[j + 1])
{
// 利用中间变量temp交换数据
temp = num[j];
num[j] = num[j + 1];
num[j + 1] = temp;
}
count++; // 记录比较的次数
}
round++; // 记录排序轮次
}
for (i = 0; i < size; i++)
{
printf("%d ", num[i]);
}
printf("\n排序轮次 = %d, 比较总次数 = %d\n", round, count);
return 0;
}
(二)算法优化
1. 优化一
已知如下序列:
{ 9 0 1 2 3 4 5 6 7 8 }
根据冒泡排序的过程可知,当程序完成第一轮排序后:
{ 0 1 2 3 4 5 6 7 8 9 }
继续第二轮排序,我们可以发现此时序列已经有序,不再需要进行交换
{ 0 1 2 3 4 5 6 7 8 9 }
优化思路
设立一个flag,flag=1代表该轮次发生了交换,flag=0代表没有发生交换(即序列已经有序)
#include <stdio.h>
#define size 10
int main()
{
int i, j, temp, round = 0, count = 0;
int num[size] = {9, 0, 1, 2, 3, 4, 5, 6, 7, 8};
int flag;
for(i = 0; i < size - 1; i++)
{
flag = 0; // 每一轮排序都默认没有发生交换
for (j = 0; j < size - i - 1; j++)
{
if (num[j] > num[j + 1])
{
temp = num[j];
num[j] = num[j + 1];
num[j + 1] = temp;
flag = 1; // 标识该轮排序发生了交换
}
count++; // 记录比较的次数
}
round++; // 记录排序轮次
if (flag == 0)
{
break; // 当没有发生交换时退出循环
}
}
for (i = 0; i < size; i++)
{
printf("%d ", num[i]);
}
printf("\n排序轮次 = %d, 比较总次数 = %d\n", round, count);
return 0;
}
2. 优化二
已知如下序列:
{ 3 2 0 1 4 5 6 7 8 9 }
根据冒泡排序的过程可知,当程序完成第一轮排序后:
{ 2 0 1 3 4 5 6 7 8 9 }
我们发现原序列的后半部分是已经排好顺序了
所以在第二轮比较中,2 没必要再和4、5、6、7、8、9 进行多余的比较
优化思路
1、既然 2 没必要再和4、5、6、7、8、9 进行多余的比较,那么我们就可以通过 k 来记录每轮排序发生交换的位置
2、于是在进行下一轮排序前,根据上一次发生交换的位置 k ,就可避免与有序的一部分数据进行比较
#include <stdio.h>
#define size 10
int main()
{
int i, j, temp, round = 0, count = 0;
int num[size] = {9, 0, 1, 2, 3, 4, 5, 6, 7, 8};
int flag;
for(i = 0; i < size - 1; i++)
{
flag = 0; // 每一轮排序都默认没有发生交换
for (j = 0; j < size - i - 1; j++)
{
if (num[j] > num[j + 1])
{
temp = num[j];
num[j] = num[j + 1];
num[j + 1] = temp;
flag = 1; // 标识该轮排序发生了交换
}
count++; // 记录比较的次数
}
round++; // 记录排序轮次
if (flag == 0)
{
break; // 当没有发生交换时退出循环
}
}
for (i = 0; i < size; i++)
{
printf("%d ", num[i]);
}
printf("\n排序轮次 = %d, 比较总次数 = %d\n", round, count);
return 0;
}
3. 总结
之所以进行算法优化,就是为了让时间复杂度尽量逼近于最好的情况。
就以上冒泡排序及其两种优化,我们可以用不同序列分别比较一下各自的效率
序列:{ 9 8 7 6 5 4 3 2 1 0 }//从小到大排序
均进行了9轮排序
第1轮:9次
第2轮:8次
第3轮:7次
第4轮:6次
第5轮:5次
第6轮:4次
第7轮:3次
第8轮:2次
第9轮:1次
共计:45次if判断
这是最坏的情况
序列:{ 3 2 0 1 4 5 6 7 8 9 }//从小到大排序
原始方法:
共9轮
共计:45次if判断
优化一:
共2轮
第一轮:9次
第二轮:8次
总计:17次if判断
优化二:
共3轮
第一轮:9次
第二轮:2次
第三轮:1次
共计:11次if判断
序列:{ 0 1 2 3 4 5 6 7 8 9 }//从小到大排序
原始方法:
9轮次
共计45次if判断
优化一:
1轮次
共计9次if判断
优化二:
1轮次
共计9次if判断
这是最好的情况
通过以上三种序列的三种冒泡排序方法中,我们不难看出优化的重要性,当序列长达几万甚至几十万的时候,判断一万次和多余判断几十万次所浪费的时间是极大的
















 3316
3316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











