







AcWing156.矩阵
题目大意
给出一个 n ∗ m n*m n∗m的矩阵,然后给出 Q Q Q个 A ∗ B A*B A∗B的矩阵,问该矩阵是否在 n ∗ m n*m n∗m的矩阵中出现过。
解题思路
如果暴力的做法,我们需要考虑 n ∗ m n*m n∗m矩阵中每个 A ∗ B A*B A∗B的矩阵,如果暴力比较显然会 T L E TLE TLE到飞起,这个时候需要用二维哈希:
在如下图的二维字符串矩阵,对他二维哈希实际上就是按照行从小到大,列从小到大的顺序转化成一维字符串"
a
b
c
d
e
f
g
h
i
abcdefghi
abcdefghi",然后对这个一维字符串哈希:
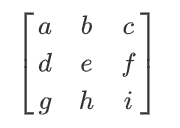
但是在本题中我们必须
O
(
1
)
O(1)
O(1)地求出所有的
A
∗
B
A*B
A∗B子矩阵,对于每一行来说,固定长度的子串哈希的转移很简单,但是对于列呢?实际上道理和行一样的,我们可以首先将行都预处理,然后对于列来说每次每列取长度为
B
B
B的子串,取
A
A
A列然后哈希,对于列来说也相当于一个“字符串”,只是每个字符都是长度为
B
B
B的子串,且需要乘的基数的哈希值为
b
a
s
e
B
base^{B}
baseB。
然后就是字符串哈希的性质应用了,我一开始只想到这个(证明我对哈希理解还不够):

这样写的代码超级长。实际上在哈希的经典应用之一,判断字符串是否含有某个子串,我们的处理方法就是对字符串从左向右转化为基数的进制数然后保存每个位置的结果
f
(
i
)
f(i)
f(i),那么
h
a
s
h
(
l
,
r
)
=
f
(
r
)
−
f
(
l
−
1
)
∗
b
a
s
e
r
−
l
+
1
hash(l,r) = f(r) - f(l-1)*base^{r-l+1}
hash(l,r)=f(r)−f(l−1)∗baser−l+1,因此二维哈希也可以用这种方式,代码只展示这种。
#include <bits/stdc++.h>
#include <unordered_map>
using namespace std;
typedef long long ll;
typedef unsigned long long ull;
typedef pair<int, int> pii;
const int maxn = 1e6 + 10;
ull base = 131;
ull Mod = 212370440130137957LL;
ull bn[maxn], a[1010][1010];
char s[1010];
int n, m, A, B, Q;
unordered_set<ull> st;
ull cal(ull i, int l, int r) { return a[i][r] - a[i][l - 1] * bn[r - l + 1]; }
void init() {
for (int j = B; j <= m; j++) {
ull hashe = 0;
int l = j - B + 1, r = j;
for (int i = 1; i <= n; i++) {
hashe = hashe * bn[B] + cal(i, l, r);
if (i > A) hashe -= cal(i - A, l, r) * bn[A * B];
if (i >= A) st.insert(hashe);
}
}
}
int main() {
scanf("%d%d%d%d", &n, &m, &A, &B);
bn[0] = 1;
for (int i = 1; i < maxn; i++) {
bn[i] = bn[i - 1] * base;
}
for (int i = 1; i <= n; i++) {
scanf("%s", s + 1);
for (int j = 1; j <= m; j++) {
a[i][j] = a[i][j - 1] * base + s[j] - '0';
}
}
init();
scanf("%d", &Q);
while (Q--) {
ull hashe = 0;
for (int i = 1; i <= A; i++) {
scanf("%s", s + 1);
for (int j = 1; j <= B; j++) {
hashe = hashe * base + s[j] - '0';
}
}
if (st.count(hashe))
puts("1");
else
puts("0");
}
return 0;
}
图像存储
题目大意
给出一个01矩阵,求出里面的1连通块的个数和种类数,当两个连通块经过上下左右平移可以重合时认为他们是相同的。
解题思路
结合上题,我们发现可以将一个连通块拿出来,左下角放在原点,那么1和0可以构成一个矩阵,我们可以对这个矩阵求二维前缀和,也可以只拿出来所有的1然后求一个哈希。
如何保证两个相同种类的块遍历的起始位置相同?实际上如果两个块相同,那么我们对整个矩阵从上到下从左到右遍历时起点一定相同,且最后映射过去图案是完全相同的。
#include <bits/stdc++.h>
#include <unordered_map>
using namespace std;
typedef long long ll;
typedef unsigned long long ull;
typedef pair<int, int> pii;
const int maxn = 1e6 + 10;
const int dx[] = {0, 0, 1, -1}, dy[] = {1, -1, 0, 0};
int a[1005][1005];
bool vis[1005][1005];
unordered_map<ull, int> mp;
vector<pii> path;
ull base = 233317;
ull Mod = 212370440130137957LL;
int n, m;
bool check(int x, int y) {
if (x <= 0 || y <= 0 || x > n || y > m) return 0;
if (vis[x][y] || !a[x][y]) return 0;
return 1;
}
void dfs(int x, int y) {
vis[x][y] = 1;
path.push_back({x, y});
for (int i = 0; i < 4; i++) {
int r = x + dx[i], c = y + dy[i];
if (check(r, c)) dfs(r, c);
}
}
int main() {
ios::sync_with_stdio(0), cin.tie(0), cout.tie(0);
string s;
while (cin >> n >> m && n) {
for (int i = 1; i <= n; i++) {
cin >> s;
for (int j = 1; j <= m; j++) {
a[i][j] = s[j - 1] - '0';
vis[i][j] = 0;
}
}
int cnt = 0;
mp.clear();
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
if (a[i][j] && !vis[i][j]) {
path.clear(), dfs(i, j), cnt++;
int px = path[0].first, py = path[0].second;
ull hashe = 0;
for (auto p : path) {
p.first -= px, p.second -= py;
ull pos = p.first * m + p.second + 1;
hashe = (hashe * base + pos) % Mod;
}
if (!mp.count(hashe)) mp[hashe] = 1;
}
}
}
cout << cnt << " " << mp.size() << endl;
}
return 0;
}














 390
390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









