







第4章 Faster R-CNN网络模型设计
4.1 Faster RCN文件结构介绍
本文在介绍具体的训练模型之前,先介绍Faster RCNN的文件结构。如图4.1所示,主要包括了7个文件夹和4个文件。主要的文件夹模块为:caffe-fast-rcnn,data,experiments,lib,tools,models,.git,和两个主要的文件LICENSE和README。

图4.1 Faster RCNN下的文件截图
在caffe-fast-rcnn文件夹下定义了caffe的框架目录,而在data文件夹下则存放了接下来训练Faster RCNN模型可能会用到的预训练模型。而lib文件下存放了下文中关于整个Faster RCNN里面会用到的一些Pyhton层的封装。比如说RPN,NMS,Fast RCNN,datasets,ROI data层等等相关的Pyhton层,也就是在网络结构中将用到的层。这些层的实现主要是通过Python来完成的。tools文件夹下主要是训练和测试所用到的Python文件,例如train net,test net,demo这样的一些Python脚本文件。而在models里则存放了接下来训练要用到的网络结构。Caffe框架则存放到了.git文件夹下。
在caffe-fast-rcnn这个文件夹下,在本文实验中包含了一些Faster RCNN会用到的一些网络层。比如说ROI Pooling层,smooth_L1_loss_layer层等。在最新版本的Caffe中,已经集成了相关的层。如图4.2所示,在src文件夹下为caffe的源代码,而include中主要是源文件。
Experiments文件夹下存放了接下来训练要用到的脚本,主要是一些SH脚本。还有一些log日志以及相关的配置信息。在lib文件夹下,存放了接下来用在网络中的特殊层,比如说,rpn层、nms层、datasets也就是数据的输入层等。在后续优化整个Faster RCNN的框架过程中,需要在这几个特殊层的角度来进行改进、优化。在models文件夹下则存放了coco和pascal_voc两个文件夹,分别对应到了coco数据集和pascal_voc数据集,本文选用了pascal_voc2007的数据集。在pascal_voc文件夹下包括了三个主干网络模型,分别为VGG_CNN_M_1024,VGG16,ZFNet。本文选用的是VGG16主干网络模型结构。Faste RCNN存在有两种训练方法,一种采用分布的方法进行训练,还有一种是采用一次性端到端的训练方法。这两种训练方法的区别在于采用分步的方法来训练时首先训练RPN网络,再对整个网络进行训练,而采用端到端的训练方法时,不单独区分RPN网络层和整个网络结构。在本文实验中采用的是分类的方法,两者精度差距很小,但是分类方法在处理图像目标检测时在速度上更具优势。
在data文件夹下有以下内容:Imagenet_models和faster_rcnn_models预训练模型,cache文件——其中存放有在训练时生成的临时文件,对于cache文件需要在每次重新训练模型时进行清除,scripts中存放有脚本文件,主要用于下载预训练模型,demo文件——其中存放有几张用于测试的图片。
图4.2 caffe-fast-rcnn文件目录
4.2 基础特征提取网络
基础特征网络VGG主要是由卷积层和池化层组成的。如图4.3所示,它的特点在于将有权重的层叠加至16层或者19层,具备了深度,根据层的深度,有时也称为“VGG16”或“ VGG19”。本文实验中选用的就是VGG16。 VGG中需要注意的地方是,基于3×3的小型滤波器的卷积层的运算是连续进行的。如图4.3所示,重复进行“卷积层重叠2次到4次,再通过池化层将大小减半”运算,最后输出在全连接层。在2014年的比赛中VGG获得了第2名。虽然在性能上不及GoogleNet,但因为VGG结构简单,应用性强,所以本文中也选用了操作较为简单的基于 VGG的网络。[21]
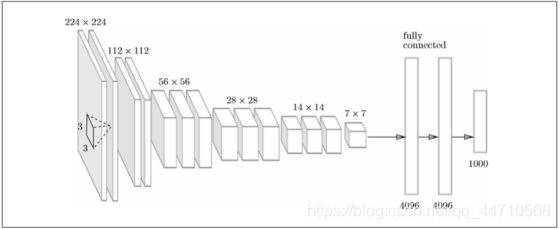
图4.3 VGG操作流程图
此外,还有名气更盛的GoogLeNet。它的网络结构相较于VGG而言较为复杂,总的来说是在纵向和横向上都有深度。过深的网络结构可能导致有过拟合问题,而GoogLeNet利用inception结构很巧妙地解决了这个问题,在不增加计算量的前提下,做到了22层的网络深度。在才用了Hebbian原理进行优化网络后,GoogLeNet在目标检测领域有不错的效果,值得一提的是在2014年夺冠的正是GoogleNet。因本文篇幅有限,不加赘述其原理。
4.3 深度学习框架性能对比实验
深度学习框架的出现降低了入门的门槛,这意味着不需要从头开始编写复杂的神经网路,而只需要选择已有的模型通过训练得到模型参数。总的来说,深度学习框架提供了一系列的深度学习的组件,研究人员可以根据不同的需求选择不同的模型并根据特定任务来优化算法和添加自己需要的分类器。
在深度学习的最开始阶段,研究人员需要写大量重复的开发代码。而框架就是一些研究人员为了提高工作效率将自己的代码整合成框架放在开源社区上供所有人一起使用的一个模型。以下为到目前为止主流的深度学习框架的介绍。[22]
TensorFlow是一款使用C++语言开发的Goole公司出品的数学计算软件。在经过简单的改写后,其几乎可以普遍适用于各个领域。TensorFlow是全世界使用人数最多、项目代码最为庞大的一个框架,因为维护和更新频繁,并且有着大众语言Python和C++的接口,教程书籍繁多,所以一直以来都被视为是深度学习框架的首选目标。
而Caffe的名气也和TensorFlow不相上下,它是由加州大学开发的一个高效的开源深度学习框架。很多比赛中使用的网络模型都是用Caffe写的,因此Caffe深受学院派开发人员的喜爱。Caffe框架提供了大量的网络模型,只需要进行微调就可以高效,快速地用于开发新的应用,操作简单,上手快。但它的缺点也很明显,Caffe框架不够灵活,内存占用较高,相比TensorFlow来说发展潜力较小。
Theano本质是数学公式的编辑器,其开发人员大多参与了TensorFlow的开发,因此可以说Theano是TensorFlow的前身。
PyTorch的前身是Torch,其底层和Torch框架一样,但Python更加灵活,并支持动态图比如视频信息等,不仅能够实现GPU加速,同时还支持动态神经网络。相比于其他主流深度学习框架,PyTorch大有追上TensorFlow的势头。
通过实验对深度学习框架性能进行对比,本文实验中使用CNN的经典结构AlexNet,对各个框架的识别速度和识别精度进行对比。本文以标准VOC2007公开数据集作为训练集。AlexNet训练的各测试网络性能超参数值如下表4.1所示。
表4.1 测试网络性能超参数值

因为实验耗时过长,所以本文设置的迭代步数较少,只设置了300000步,并取消了权值衰减系数。实验结果如图4.4所示。
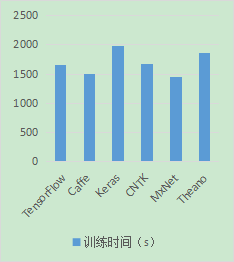
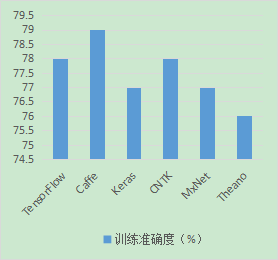
图4.4 各个主流深度学习框架的识别速度和准确度
综合实验结果和文献资料可以得出结论,Tensorlow的计算速度和准确率在所有主流学习框架中处于中上水平,同时TensorFlow具有很强的普适性,通过简单的超参数修改,就可以放在不同的硬件环境中运行。同时TensorFlow 在使用人数、开源代码数量、下载数上都占据优势,因此TensorFlow是一个极为良好的深度学习框架的选择。[20]
4.4 网络模型架构
Faster RCNN的网络分为两大部分,分别是基础特征提取网络和区域候选网络RPN,其整体检测流程如图4.5所示。Faster RCNN首先采用基础特征提取网络VGG16提取目标物体的重要特征,并获得输出特征图;然后RPN层会在特征图的每个点上生成多个候选窗口,并初步将图片的物体划,同时对生成的候选窗口进行回归调整;最后,Faster R-CNN利用RPN网络生成的候选窗口进行精细分类和边界框回归,从而实现物体的准确检测。
本文中采用VGG16作为Faster RCNN的基础特征提取网络,VGG16由卷积层和最大池化层堆叠而成,采用多个3×3卷积核串联的方式可模拟更大的感受野,提取更加全局的特征信息。本文所采用的深度学习框架为Caffe,卷积层的网络定义形式与代码注释如下:
layer {
name: "conv1_1" // 网络层名称
type: "Convolution" // 网络层类型
bottom: "data" // 网络输入层
top: "conv1_1" // 网络输出层
param { lr_mult: 0 decay_mult: 0 }
param { lr_mult: 0 decay_mult: 0 }
convolution_param {
num_output: 64 // 卷积核数量
pad: 1 // 边缘填充像素数
kernel_size: 3 // 卷积核尺寸
}
}
池化层的网络定义形式如下:
layer {
name: "pool1" // 网络层名称
type: "Pooling" // 网络层类型
bottom: "conv1_2" // 网络输入层
top: "pool1" // 网络输出层
pooling_param {
pool: MAX // 最大池化
kernel_size: 2 // 池化窗寸
stride: 2 // 池化步长
}
}
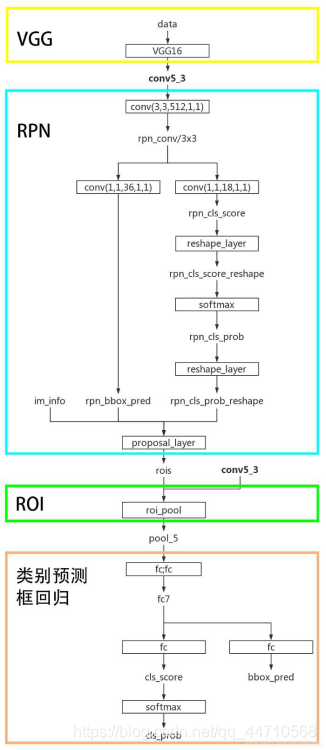
图4.5 基于VGG16的Faster RCNN网络模型框架
在每个卷积层后跟着一个ReLU激活层,对卷积特征图进行非线性激活,从而增加网络模型的非线性表达能力。
ROI池化层的主要目的是提取固定长度的特征向量以供分类器进行分类。不同尺寸的输入图像经过特征提取网络后输出的特征图尺寸也是不一样的,但全连接要求输入特征图尺寸是固定不变的,因此引入ROI池化层解决此问题。ROI池化层将最后特征图上分别划分为4×4,2×2和1×1的网格,并取每个网络内的最大值作为输出特征,最终能够提取出21个特征值,并且不受特征图尺寸的影响。
4.5 性能评价指标
为了衡量模型的检测性能,本文采用平均精度AP(Average Precision)和均值平均精度mAP(mean Average Precision)作为模型的评价指标。平均精度AP是指每一类别在不同阈值下的Precision值的平均值,可理解为每一类物体P-R曲线下的面积,mAP是多类目标物体的平均值,其中P代表准确率(Precision),R代表召回率(Recall),他们的计算方式如下:
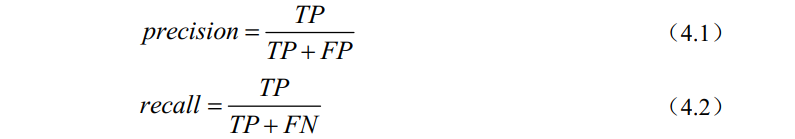
式中,TP(True Positive)——表示将正类预测为正类的数量;
TN(True Negative)——表示将正类预测为负类的数量;
FP(False Negative)——表示将负类预测为正类的数量;
FN(False Negative)——表示将负类预测为负类的数量。
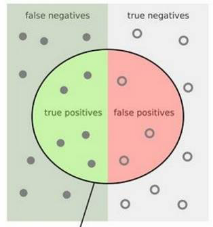
图4.6 样本分类图
4.6 基于Faster RCNN的训练与检测
4.6.1 超参数设置
本文的实验环境采用Ubuntu16.04的操作系统,并配备了显卡驱动和神经网络加速库,所采用的Faster RCNN在Caffe框架下运行。
网络训练中涉及到诸多超参数,超参数的设置对网络训练的效果具有较大的影响,本文对Faster RCNN训练时所设置的超参数类型和具体数值如下:
(1)初始学习率base_lr: 0.001
学习率决定着训练参数,即权重与偏差的更新速度,学习率设置的较大将导致结果错过最优点,设置的太小会使下降速度较慢,训练时间长且效果不一定最优。通常地,这个值设置成动态变化的,初始值较大,在训练到一定轮数后再逐渐减小。
(2)学习率调整策略lr_policy: “step”
学习率的变化策略,包括constant、step、steps、ploy等。本文将学习率的更新策略设置为step,与(4)组合使用,即每训练stepsize次,学习率调整为原本的gamma倍。
(3)学习率衰减倍数gamma: 0.1
(4)学习率衰减步长stepsize: 30000
前四项超参数均与学习率有关,需要组合使用。在本文中,初始学习率为0.001,每迭代30000次,学习率衰减为上一次的0.1倍。
(5)display: 20
每训练20次在执行终端内显示一次信息。
(6)average_loss: 100
(7)动量momentum: 0.9
误差反向传播时最优化方法中的参数,影响着梯度下降到最优值的速度。
(8)权重衰减项weight_decay: 0.0005
权重衰减正则项,输入卷积层的数据将进行批量正则化,该参数有助于防止网络过拟合。
4.6.2 模型训练策略
Faster RCNN中有两种不同的网络训练方式,分别是交替优化法和近似联合训练法。本文所采用的训练方式是交替优化法,即分别训练RPN和Fast RCNN两个网络,共分为两大阶段,每个阶段各训练一次RPN和Fast RCNN,其训练流程图如图4.7所示。
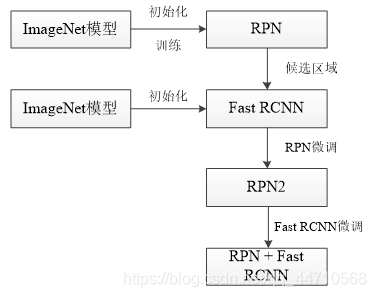
图4.7 交替优化训练流程
为了降低训练难度,提高训练效率,本文采用了VGG16在ImageNet上预训练模型作为初始模型,在此基础上训练RPN和Fast RCNN网络。这种做法的原理是特征迁移,由于卷积神经网络的底层都是提取轮廓信息特性,而ImageNet上具有1000个类别、100万张以上的数据集,通过学习该数据集上的特征能够加速本文研究目标的训练与学习,并且能够防止梯度消失和过拟合等现象的发生。
整体训练的流程如下:
(1)使用预训练模型对RPN网络进行初始化,并在预训练模型基础上训练RPN网络;
(2)使用预训练模型对Fast RCNN网络进行初始化并在此基础进行训练;
(3)将RPN和Fast RCNN中共享的卷积层学习率设置为0,即不再更新这部分网络的参数,并只训练RPN中特有的网络层;
(4)将RPN和Fast RCNN共享的网络层固定,只训练微调Fast RCNN中特有的网络层。
网络训练的迭代次数设置为max_iters = [80000, 40000, 80000, 40000],分别对应着以上四个阶段的训练次数。
4.6.3 检测结果与分析
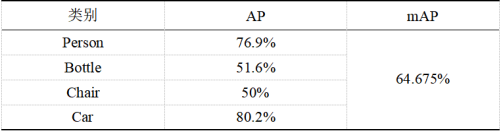
本文的测试集在调试完成的网络模型在上进行了测试,并获取了特定目标识别的平均精度AP和均值平均精度mAP如表4.2所示。
从表中可以看出,汽车的识别效果最好,均值平均精度达到了80.2%,其次是人,杯子和椅子的识别效果相对较差,均值平均精度分别为51.6%和50%。这主要是由于数据集中人和车的数量较多,杯子和椅子的图片数量较少造成的。在测试集中的检测结果如图4.8所示。

图4.8 Faster RCNN检测结果示例
从检测结果表4.2可以看出,本文所训练的Faster RCNN模型能够准确地识别出图片中的人、车、杯子和椅子,在生活日常物体中具有较好的检测结果。检测过程中发现,基于VGG16的Faster RCNN网络检测单张图片的平均耗时为0.172s,即每秒可检测5.8张图片,距离实时性还具有一定的差距。
表4.2 实验检测结果
4.7 本章小结
本章从数据集制作出发,详细介绍了本文采集和标注数据集的具体过程和所使用的工具,并针对训练需求将标注好的VOC2007数据集按比例划分为训练集、测试集和验证集。其次,介绍了Faster RCNN的网络整体架构,并对深度学习框架Caffe下的实现代码进行了举例解释,同时介绍了目标检测中AP,mAP,P,R等性能评价指标。在本文最后介绍了训练所采用的实验仿真环境和模型训练过程中的超参数设置,阐述了Faster RCNN的训练流程,并对训练后的模型进行了测试,获得了模型在各个类别上的性能指标。
第5章 结论和展望
5.1 结论
本文通过文献和网上资料的学习,初步认识到了卷积神经网络在目标检测领域中的潜力和优势,它是传统的手工算法所无法相比的。通过学习和改进,本文在实验中使用Faster RCNN算法进行了网络模型设计并通过实验完成了超参数调优。基本完成了对图片中的多个特定目标进行识别和定位的任务。
本文的工作大致为以下几个方面:
1)介绍了目标检测的定义和目标检测算法发展中各个常用目标识别算法的原理,重点介绍了卷积神经网络的原理。
2)通过采集公开数据集中没有的生活用品目标,如杯子等图像数据,通过数据增强和标记,制作了部分XML格式的生活用品目标数据集用于卷积神经网络对于真实环境的多目标图像识别。
3)通过查阅资料和对比实验得出TensorFlow仍是最佳框架选择的结论。并使用特征提取网络和自制数据集构建基于Faster R-CNN算法在Caffe框架下的区域选择多目标识别网络并通过实验完成参数调优。
结果表明,本文所训练的基于候选区域的深度学习目标检测算法模型在对生活中日常物体的检测中具有较好的性能表现。
5.2 未来展望
因为时间紧张和所学专业的不同,所以对于深度学习和目标检测算法的学习只能是很肤浅的略知一二。通过这段时间的学习和实验,我不仅学习到了卷积神经网络的原理和初步运用,更学会了使用开源社区和博客上他人的精彩代码进行学习和自我进步,让我对于深度学习有了更加浓厚的兴趣。未来希望自己能在这个方面更多的学习,不断完善自己对于各种深度学习框架和网络层的理解。本文不足之处很多,基于文献和目标检测领域未来的发展提出了几点建议:
1)深度学习框架。本文因为作者水平有限,采用了较为简单,多是模块化的Caffe框架进行实验,但未来TensorFlow仍是主流的深度学习框架。TensorFlow资源丰富,在github上有很多可以借鉴的基于TensorFlow的神经网络。
2)算法。由于时间有限,本文只对Faster RCNN算法进行了详细研究。但目前来说,基于回归的深度学习目标检测算法也是研究重点,它在目标检测速度上相比较于Faster
RCNN提高了很多。但如果要在保证识别精度的基础上进一步提升识别的速度,还需要进一步的研究和网络层的优化来提升目标检测模型的性能。
3)识别目标。本文仅对生活目标中的一部分特定目标进行了数据集的采集和制作。未来可以在此基础上扩大数据集,识别更多的目标。
4)识别准确率。本文未对光照条件,物体运动速度,遮挡等进行屏蔽,在图片背景较为复杂或颜色和识别物体相同时,识别准确率大大降低。未来可以在此算法的基础上,进一步深化对图像锐化和边缘处理算法的改进,从而提高对于复杂背景条件下的多目标检测识别。
参考文献
[1]谢一德.基于深度卷积神经网络和图像传感器的道路多目标检测研究[D].北京交通大学,2018.
[2]郭济民.基于深度神经网络的物体识别方法研究及实现[D].电子科技大学,2018.
[3]Ren S, He K, Girshick R, et al.Faster r-cnn: Towards real-time object detection with region proposal networks[C]//Advances in neural information processing systems. 2016: 91-99.
[4]Krizhevsky A, Sutskever I, Hinton G E.Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems. 2017: 1097-1105.
[5]LeCun Y,Bengio Y,Hinton G.Deep learning[J].nature,2016, 521(7553):436.
[6]李明攀.基于深度学习的目标检测算法研究[D].浙江大学,2018.
[7]韩月.基于深度学习的人车混合目标检测技术研究[D].北方工业大学,2018.
[8]张守东.复杂场景下基于深度学习的显著性目标检测算法研究[D].南京师范大学,2018.
[9]杜凤麟.基于深度学习目标检测算法的应用[D].安徽大学,2018.
[10]罗森.基于深度学习的车道线和车辆检测[D].电子科技大学,2018.
[11]Xi Li,Weiming Hu,Chunhua Shen,Zhongfei Zhang,Anthony Dick,Anton Van Den Hengel. A survey of appearance models in visual object tracking[J]. ACM Transactions on Intelligent Systems and Technology (TIST),2013,4(4).
[12]韩凯.基于深度学习的目标检测研究[D].西南科技大学,2018.
[13]尹宝才,王文通,王立春.深度学习研究综述[J].北京工业大学学报,2015,41(01):48-59.
[14]姜亚东.卷积神经网络的研究与应用[D].电子科技大学,2018.
[15]杨俊.基于卷积神经网络的目标检测研究[D].兰州理工大学,2018.
[16]高珏.基于卷积神经网络的目标检测算法研究[D].北京交通大学,2018.
[17]赵井飞.卷积神经网络算法及应用研究[D].沈阳航空航天大学,2018.
[18]李丹.基于深度学习的目标检测综述[J].科技经济导刊,2019,27(13):1-2+31.
[19]孙志军,薛磊,许阳明,王正.深度学习研究综述[J].计算机应用研究,2012,29(08):2806-2810.
[20]Herbert Bay,Andreas Ess,Tinne Tuytelaars,Luc Van Gool. Speeded-Up Robust Features (SURF)[J]. Computer Vision and Image Understanding,2007,110(3).
[21]黄斌,卢金金,王建华,吴星明,陈伟海.基于深度卷积神经网络的物体识别算法[J].计算机应用,2016,36(12):3333-3340+3346.
[22]薛明东,郭立.基于SVM算法的图像分类[J].计算机工程与应用,2004(30):230-232.
















 6468
6468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











