




为什么需要分布式系统
相信大家在学习阶段学习的demo或者是项目基本上都是单体系统,在自己的一台机器上就可以成功运行了,我自己也是如此.但是无论是面试中或者说随着学习的深入,自己又常常遇到分布式,可是分布式的相关知识在我的脑海中就像蒙上一层雾气,可以看清轮廓,却不见其细节,所以自己也打算系统的学习一下.
1.单体结构系统的不足
我们把我们的服务部署在一台服务器上就可以正常运行了,但是我们可以假设一些场景来说明分布式的重要性
facebook和Instagram等世界级网站每秒可能要承受几百万级别的访问,在峰值可能甚至会达到亿级别的流量,这种量级的流量一台服务器承受得了吗,这么多用户的数据一台服务器能存储的了吗?-----这就是高性能问题- 假如
Facebook唯一的那一台服务器所在的地区停电了或者说那栋楼发生火灾了,服务因为不可抗力被终止了,怎么办?Facebook所有的用户都不能使用了,这是多么糟糕的用户体验,造成的损失是不可估计的!—这就是高可用问题
2.分布式是怎样解决这些问题的呢?
-
高性能:高性能可以指两个方面,一个是存储的高性能,一个是计算的高性能.解决的思路都很相似:都是在水平层面来增加更多的机器,然后将计算和存储的压力分担到不同的机器上面,一台机器存储不了,我们就将数据
分片(partition),分别存储在不同的机器上.如果一个计算运算能力不够,我们就将大任务分成很多小任务,最后将结果汇总,这就是MapReduce的基本思想. -
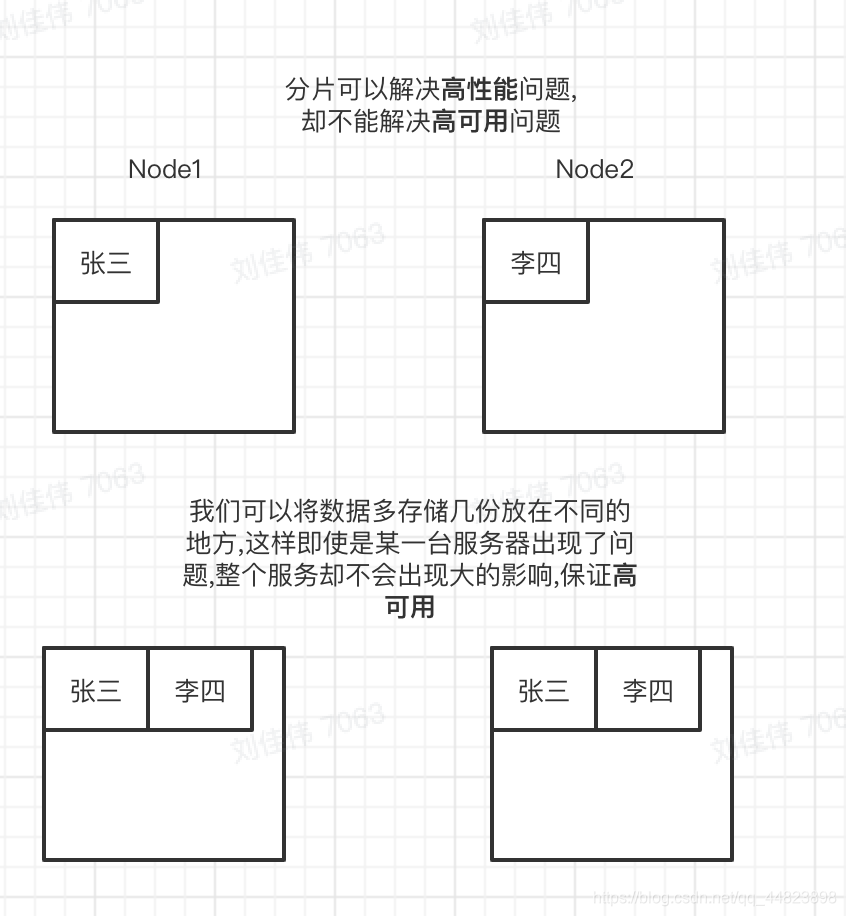
高可用:高可用就是指在整个系统中,即使某个节点某台机器出现了问题,整个系统也不会因此而停止向用户提供服务,以存储为例:假设有两个节点分别存储不同的数据,张三的用户数据存在
Node1里面,如果Node1突然宕机了,这时张三就不能正常访问了,这时我们可以冗余存储(Replication),在Node1&Node2上都存储.
应用分布式带来的挑战
- 我们会使用不同的节点提供相同的服务来保证
高可用,这时候就会带来一个问题,如果一个请求过来,我们应该选择那一个节点来为它提供服务了,因为不可能所有节点提供服务的能力都相同.如果选择一个合适的节点来提供服务.这就是负载均衡 - 在
冗余存储(Replication)中,不同的节点存储着相同的数据,如果我们需要对数据进行更新,因为网络等等原因,有的节点更新的快,有的慢,有的因为网络没有接收到更新的请求,这个时候不同的数据就会有短暂的不一致情况,我们就会需要在一致性(consistency)和高可用(Availability)进行一定的权衡,这里就会涉及到CAP理论&Raft算法等相关知识 - 为了提供
高性能,我们会将一个大的服务拆分成不同的小服务,例如一个商城服务,我们将用户模块,商品模块,下单服务等放在不同机器上,这个时候我们怎么去调用其他服务呢?因为在不同机器,所以我们就需要使用网络通信,而因为网络通信比较复杂,我们希望调用其他远程服务就像本地方法一样方便简单,这就涉及到了**RPC**相关的知识 - 在分布式系统中,我们也需要事务,希望涉及到不同服务的一组操作能够正常运行.这就又涉及到**
分布式事务**
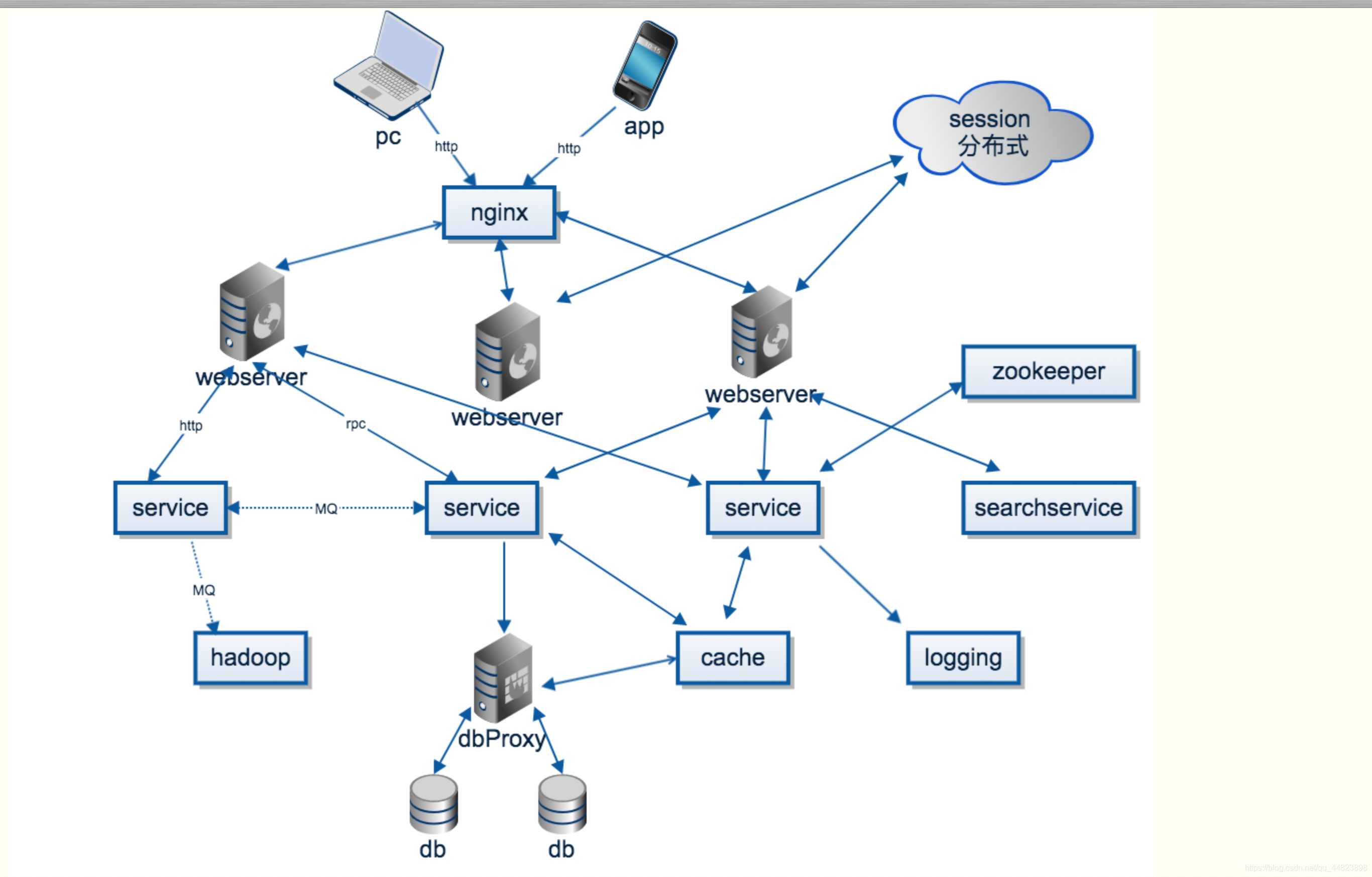
然后借用网上的一张图来简单的概括下一个分布式系统

















 1151
1151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









