






第四章 存储系统
一、存储器的分类
1、按存储介质分类
半导体存储器(SemiConductor Memory,SCM) 体积小、功耗低、速度快
磁表面存储器(Magnetic Surface Memory,MSF) 非易失、价格低廉
光介质存储器(Ferro electric Memory,FeM) 记录密度大
2、按访问周期是否均等分类
随机访问存储器(Random Access Memory,RAM) 访问时间与存储位置无关
顺序访问存储器(Serial Access Storage,SAS) 访问时间与存储所在位置有关
3、按访问类型分类
可读/写存储器(亦称为RAM)
只读存储器(Read Only Memory,ROM)
4、按在计算机系统中的作用分类
主存(亦称为内存) 通常在计算机系统中的内部
辅存(亦称为外存) 通常在计算机系统中的外部,有时可以看作外部设备
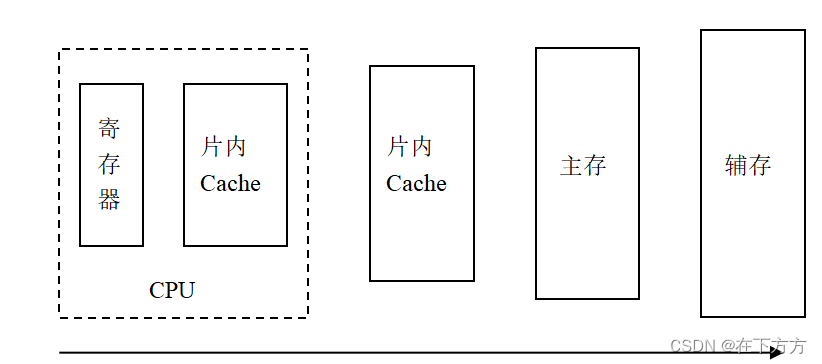
高速缓冲存储器(Cache)
- 计算机存储系统的层次结构
- 局部性原理
(1)时间局部性:现在正在访问的信息可能马上还会被访问到
(2)空间局部性:现在正在访问的信息,与之相邻的信息可能马上也会被访问到
二、半导体存储器
1、基本结构
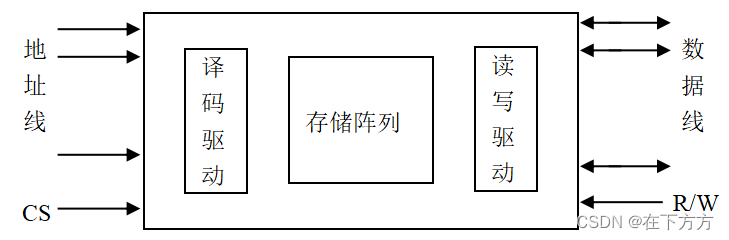
地址线位数由地址空间决定,如空间大小1K(即210),则地址线10位
数据线位数由存储单元决定,如存储单元字长为8,则数据线8位
- 译码驱动方式
(1)线性译码,亦称单译码,即只有一个译码器
特点:控制简单、速度快、但地址空间较小
(2)多重译码,即包含多个译码器,只有当全部译码器选中才工作
特点:控制复杂、地址空间大
2、随机访问存储器RAM
(1)静态RAM(Static RAM,SRAM)
特点:存储一位二进制数需要6个三极管(触发器工作原理)
速度快、控制简单、容量小
(2)动态RAM(Dynamic RAM,DRAM)
特点:存储一位二进制数仅需要1个三极管(靠三极管的极间电容存储数据)
速度略慢、控制复杂、需要刷新和重写操作、容量大
3、动态RAM的刷新 - 原因:利用极间电容存储数据,电容会自放电
- 周期:2ms,超过2ms不重新写入,原数据不可读
- 方式:按行(或列)完成,即一次刷新完一行(或一列)
(1)集中式刷新
集中一段时间逐行刷新完整个存储阵列(由于刷新时无法进行读写操作,此段时间亦称为死时间)
特点:实现简单(定时电路按时触发)、存在死时间
(2)分散式刷新
扩展每个存储周期,读写操作后自动刷新一行(因此新的存储周期是原来的2倍)
特点:对外无死时间、速度变慢、刷新操作过于频繁
静态RAM与动态RAM的比较
(1)动态RAM的优点(相对静态RAM来说)
集成度高、容量大、地址可以分批写入、芯片引脚变少、功耗低、价格低
(2)动态RAM的缺点(相对静态RAM来说)
需要刷新操作、需要重写等辅助电路、速度慢
应用范围:一般来说,主存广泛使用动态RAM,高速缓存采用静态RAM
4、只读存储器ROM
(1)掩膜ROM(Masked ROM,MROM)
生产厂家在生产芯片时,利用掩膜工艺,把需要的数据直接存入芯片内。芯片生产后,内部数据无法更改,典型意义的ROM
(2)可编程ROM(Programmed ROM,PROM)
内部由厂家设置熔丝,需要时可用特殊的写入电压把相应的熔丝熔断(该操作称为编程写入),熔丝熔断后无法再次设置,因此只可写一次
(3)可擦除PROM(Erasable PROM,EPROM)
内部的电子三极管栅极具有浮动栅,不设置浮动栅,正常的导通操作;设置浮动栅则阻碍导通。根据需要设置相应的浮动栅(由特定的写入电压完成),即写入相应的数据,如不需要用紫外线照射,电子获得能量后浮动栅去除,所以可以多次写入擦除
(4)电可擦除PROM(Electrically EPROM,EEPROM或E2PROM)
擦除操作不需要紫外线,直接用特定的电流完成,操作更简单
- 闪存(Flash Memory)可以理解为一种快速的EEPROM,即闪速存储器
三、主存储器
- 由DRAM芯片(通常为多片)构成,主要考虑速度、容量和价格的平衡
1、容量的扩展
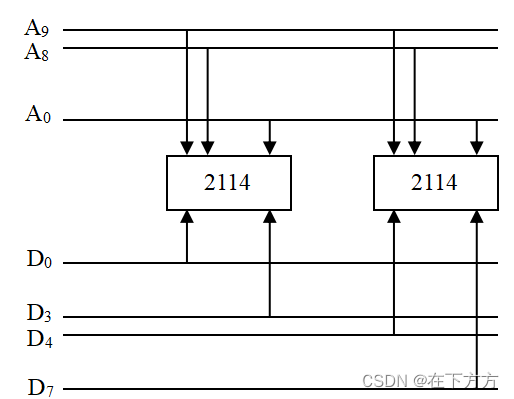
(1)扩位连接:扩展数据
例:用芯片2114(1K×4)组成1K×8的存储器
分析,2114有10根地址、4根数据,要组成的存储器需10根地址、8根数据,则从数量上看需要2片2114,共同构成8位数据,工作时一起操作。连接图见下图:
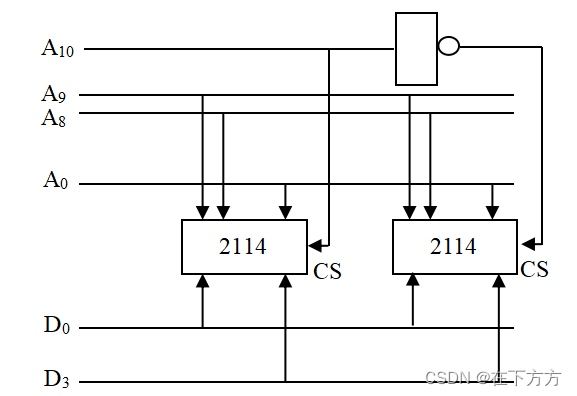
(2)扩字连接:扩展地址
例:用芯片2114(1K×4)组成2K×4的存储器
分析,2114有10根地址、4根数据,要组成的存储器需11根地址、4根数据,则从数量上看需要2片2114,共同构成2K个存储单元,工作时一次只一片操作,由高位地址片选控制。连接图见下图:
(3)即扩字又扩位:即扩数据又扩地址,上述二者的结合
方法同上,具体略
例:设CPU共有16根地址线,8根数据线,并用MREQ(低电平有效)作访存控制信号,R/W作读/写控制信号(高电平读、低电平写),现有8片8K×8位的RAM芯片。完成下列要求:* 用74LS148译码器画出CPU与RAM的连接图。 - 写出每片RAM的地址范围
- 如果运行时发现无论往哪片RAM写入数据时,以A000H为起始地址的存储芯片都有与其相同的数据,分析其原因。
连接图见下图:
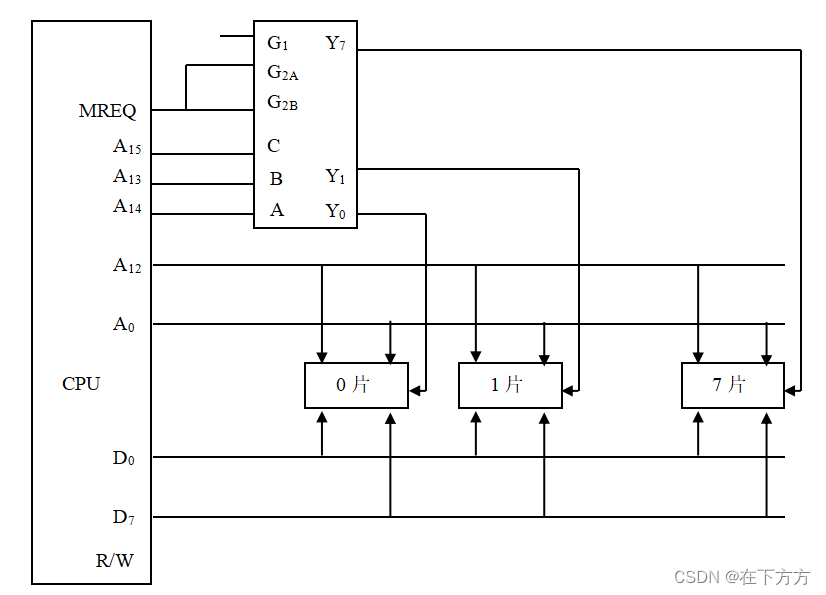
各片RAM地址范围如下:
0片:0000H—1FFFH
1片:2000H—3FFFH
2片:4000H—5FFFH
3片:6000H—7FFFH
4片:8000H—9FFFH
5片:A000H—BFFFH
6片:C000H—DFFFH
7片:E000H—FFFFH
以A000H为起始地址的存储芯片为第5片,片选信号为Y5,当无论往哪片RAM写入数据时,其都有相同的数据写入,说明其片选一直有效,如不考虑其他,可能Y5接地。
2、几个主要的技术指标
(1)存储容量=存储单元个数×存储字长
为了便于相互比较,现在习惯上把存储字长转换为Byte(8位)的倍数。
(2)速度- 存取时间:启动一次操作到完成该操作的时间(仅与器件本身有关)
- 存储周期:在系统中,存储器进行两次连续独立操作的最小间隔时间(与所在系统有关),通常存储周期的值要大于存取时间
(3)带宽:单位时间内存储器完成的最大数据传输位数
- 是一个速率值,单位时间通常取1 s
- 是理论上的最大值(即峰值),在实际中一般很少出现
例:若某存储器一次读写操作最大可以传输16位,存储周期为500ns(10-9s),求该存储器的存储带宽。
分析,一次操作16位,即2Byte;
一秒内最多可以完成1s/500ns=2×106次存储操作;
则存储带宽=(2×106)×2Byte=4MB/s
注意:在数值计算时,因210=1024,近似为1000(即103),所以103有时可缩写为1K,同理106可缩写为1M,看清前后上下文。
3、主存储器的地址分配
(1)字节地址和字地址 - 主存的编址原则:按字节编址(一个8位数据对应一个物理地址)
即不论机器的具体组织结构,一个地址就对应1Byte(8位二进制数) - 存储字:主存为了提高工作速度,实际一次访存数据要大于8位(通常为Byte的整数倍数),对应存储器的具体组织结构,一般称一次实际访存所对应的组织结构为存储单元(亦称存储字),该单元内存放的二进制数的位数值为存储字长。
示例如下图:
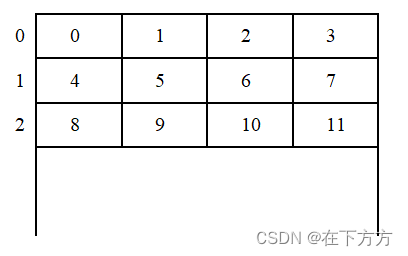
上图一个存储单元内含4个字节,对应字节地址值为方框内数据,每个存储单元前的数据为字地址值。
字节地址和字地址变换关系见下表(字节地址字长取8位):
十进制地址值 字节地址值(字节地址去掉2位后即变为字地址)
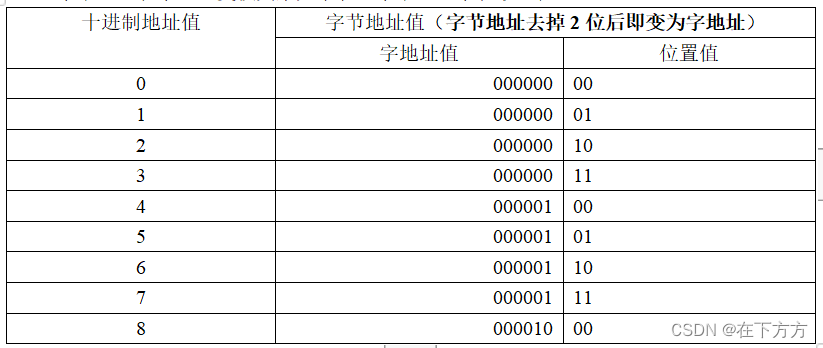
字地址值 位置值
0 000000 00
1 000000 01
2 000000 10
3 000000 11
4 000001 00
5 000001 01
6 000001 10
7 000001 11
8 000010 00
上表每4行一组(对应示例图中的4个字节构成一个存储字),则每组内前6位相同(正好对应为存储单元的字地址),后两位依次变化,对应为每个存储字内的不同位置值。
如每个存储单元由8个字节组成,则字节地址后三位为位置值,去掉三位剩下的为字地址。
(2)大端(Big endian)存储和小端存储(Little endian) - 小端:地址按从小到大排列,最低有效地址在前面(代表机型Intel系列)
即8086汇编语言所说的:高高低低原则 - 大端:地址按从小到大排列,最低有效地址在后面(代表机型IBM370系列)
例:十六进制数12345678H存放在地址100H处,示例图如下:

注意:无论大端存储还是小端存储,在高级语言编程中不可见;仅在底层数据传输时需考虑此问题。
4、提高访存速度的措施
(1)多端口RAM
两套或多套独立的读写逻辑,可并行操作
(2)单体多字
一次访存,同时读出或写入多个存储字(提高了访存带宽)
如连续操作相邻的地址单元,则效果明显,如连续操作跳跃的地址单元,效果不明显
(3)多体并行
多个存储体操作,并行效率高,但控制复杂
分为高位地址交叉和低位地址交叉两种模式
访存优先级原则:
- 易发生代码丢失的优先级高 (一般来说I/O操作>CPU操作)
- 严重影响CPU工作的优先级高 (一般来说写操作>读操作,不是绝对的,看具体情况)
四、高速缓冲存储器Cache
- 问题的提出:CPU和主存的速度不匹配
- 基于的理论:局部性原理(即某一时间段,被访问的主存地址分布集中在某一区域)
1、相关的基本原理
(1)基本逻辑关系图 - 主存、Cache均划分为大小相同的块,操作时以块为单位(不同于主存以字为单位)
- 块的大小要适中,一般为几个字至十几个字
块太小,影响命中率;块太大,一次调入调出的时间开销大 - 地址分为块号(高位)和块内地址(低位)两部分
如果一个块大小为8个字,则块内地址为3位,其余情况依次类推 - Cache的每个块均会设置相应的标志状态(包含多位),用来判断是否命中
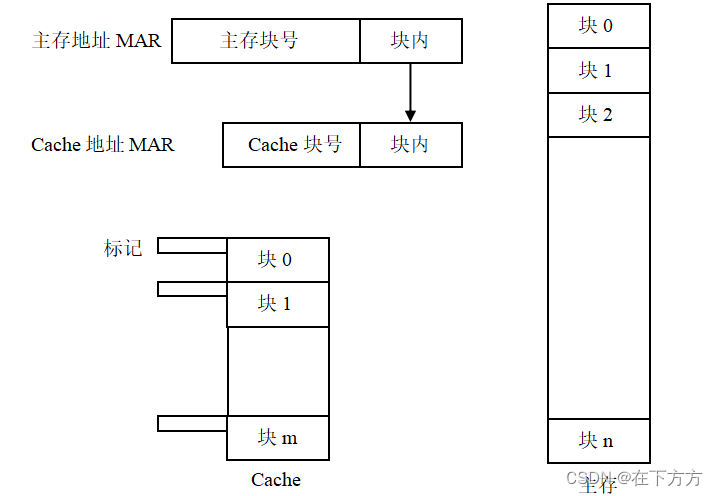
注意:Cache容量越大,则命中率越高,但价格越昂贵
(2)Cache组成结构分类 - 旁视式Cache结构
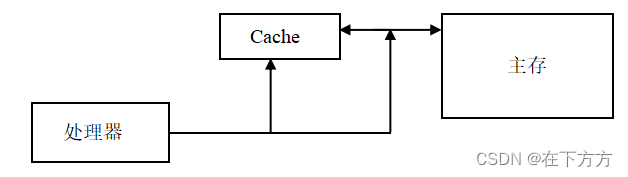
特点:处理器即可访问Cache,又可访问主存;
假设访问Cache的时间为T1,访问主存的时间为T2,则Cache命中时,系统操作时间为T1,Cache不命中时,系统操作时间为T2(主存与Cache同时启动);
每次操作均需占用系统总线,总线负荷大。 - 透过式Cache结构

特点:处理器不可直接访问主存;
假设访问Cache的时间为T1,访问主存的时间为T2,则Cache命中时,系统操作时间为T1,Cache不命中时,系统操作时间为T1+T2(主存与Cache不同时启动);
总线负荷降低。
(3)完整的读数过程(以旁视式Cache结构为例,透过式Cache结构略有不同) - 地址映像变换机构:把主存地址进行变换,判断是否能生成Cache地址
能映像(即可以变换,称为命中),生成相应的Cache地址,访问Cache
不能映像(即无法变换,称为失效),无法访问Cache,只能访问主存 - 块替换机构:当Cache装满时,再需装入新块,要替换哪个块
- 多字宽数据总线:Cache体系所特有的结构,块不是一字一字写入的,而是一次直接写入的(主要考虑减小延迟、减小失效开销,硬件开销增大)
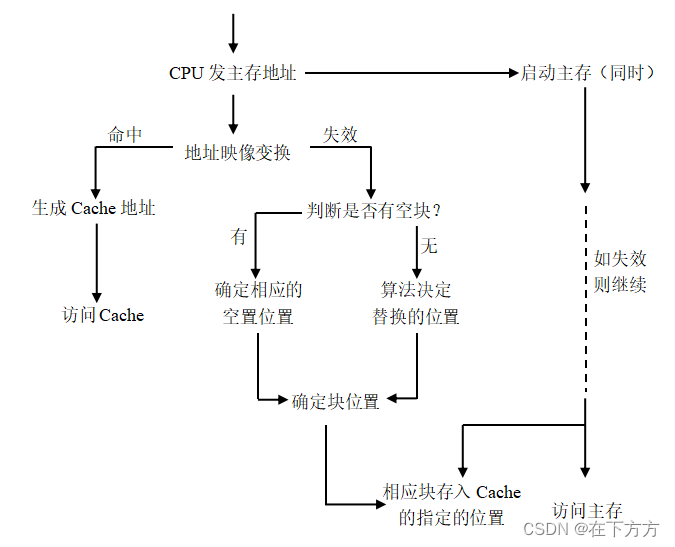
注意:透过式Cache结构操作上的几点不同
- 透过式结构仅在映像地址失效后,才启动主存(主存启动次数少,主存利用效率高)
- CPU无法直接访问主存,必须调入Cache后,CPU才能访问到相应的数据(失效开销大)
- 多核系统比较常见此种结构(每个核对应一个Cache,主存安全性较高)
2、地址映像方式(Address Mapping)
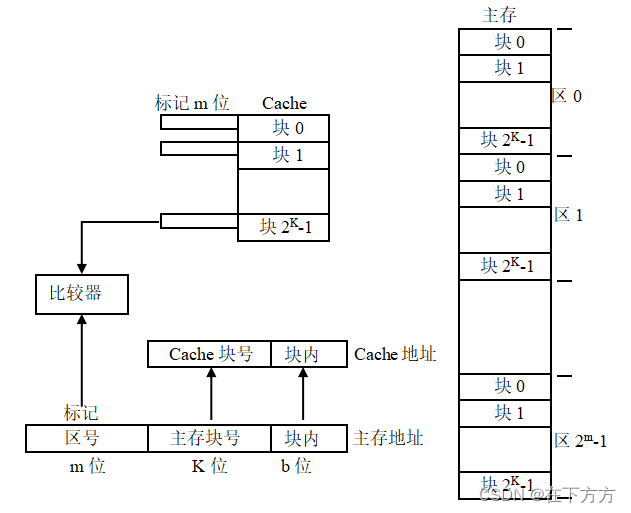
(1)直接映像(相当于对号入座) - 主存的块号直接决定映射Cache的位置
- 硬件实现简单,主存的后几位地址即为Cache地址,只需一个比较器即可判断命中
- Cache的利用率相对较低,即使有空的槽位,依旧替换
(2)全相联(相当于随便入座) - 主存的块可以对应Cache的任意位置,没任何限制
- Cache的利用率相对较高,只要有空的槽位,即可装入
- 硬件代价高,需要一个庞大的相联比较器,实际上无法实现
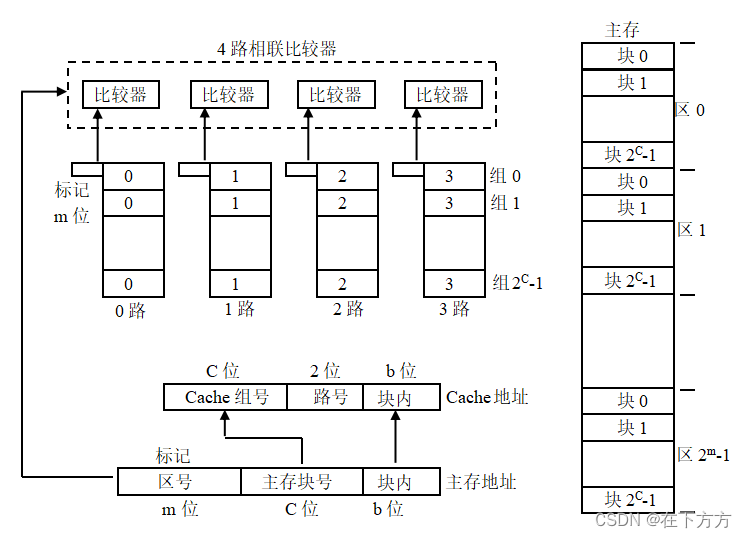
(3)组相联(上述二者的折中) - Cache分若干组,组内全相联映射,各组之间直接映像
- 硬件代价不是很高,实际上最多8路相联
- 各组内编号相同的块可以组成一个逻辑结构,称为路,8路即组内有8个块
具体映像逻辑图如下:
(1)直接映像
(2)全相联映像

(3)组相联映像(以4路组相联为例)
3、替换算法
(1)先进先出(FIFO):最先进入的块最先替换
例:假设Cache只有4个块,采用全相联映射,初始为空状态,块号调入次序为:1、2、4、6、1、3、1,示意图如下:
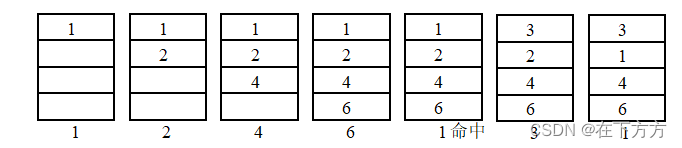
- 实现简单,只需一个循环移位器,循环指示要替换的位置即可
- 命中率相对较低,会出现颠簸现象
(2)近期最少使用(LRU,Least Recently Used)
上例示意图如下:
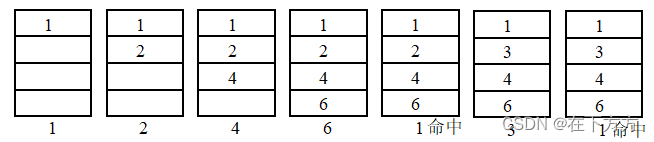
- 命中率相对较好,不会出现颠簸现象
- 硬件实现复杂
(3)随机法 - 随机选中一个块作为替换块
- 硬件代价最小
- 模拟实现表明,命中率差的不多,所以在实际中也经常被采用
4、写入策略 - 读数操作(不改变原内容),即Cache与主存可以保持一致
- 写数操作(改变相应内容),如何保持Cache与主存的数据一致,实际上写入策略主要考虑的就是数据一致性。
(1)写命中时
写数的地址可以映像到Cache中,当然主存中肯定有(即主存和Cache同时存在),实现时有下面两种方法:- 写穿法(Write_Through,有时亦称写直达法)
主存和Cache同时一起写,写入时间按慢速设备为基准(即主存的时间),所以速度慢;但可以保证数据时刻一致,安全性高。
- 写穿法(Write_Through,有时亦称写直达法)
- 写回法(Write_Back)
操作时,只写Cache,在相应块设置标志位(习惯上称脏位,Dirty Bit),在该块替换时回写主存,所以速度较快;但某时间段,主存和Cache数据不一致,安全性较差。
(2)写失效时
写数的地址无法映像到Cache中,此时数据只在主存中(即Cache里不存在),因此只需操作主存(速度也只能以主存为基准),需要考虑是否把该块调入Cache(根据局部性原理,下一个操作数据也可能在此块中,但写数操作不同于读数操作,即写数操作随机性较大,所以下一个数据也可能不在此块中),具体分配方法有下面两种: - 按写分配
写主存的同时,相应块调入Cache,因此命中率相对较高,但通信开销大。 - 不按写分配
只写主存,相应块不调入Cache,通信开销小,但命中率相对较低。
5、Cache体系的性能评价
(1)命中率 H=RC/R
其中RC代表命中的次数,R代表总的访存次数
(2)平均访问时间
在Cache体系中包含Cache和主存两个部件,它们的访问时间分别为:TC和TM
则:
Ta=H·TC+(1-H)TM (旁视式)
Ta=H·TC+(1-H)(TC+TM) (透过式)
(3)加速比 SP=TM/Ta
表示采用Cache后,系统的性能比没采用Cache时性能提升的倍数
(4)效率 E=TC/Ta
因为不管命中率提升到多高,Cache体系总会包含访问主存的时间,此参数表示Cache体系的性能和单纯访问Cache的时间的接近程度。
















 1017
1017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











