



 本文介绍了数据字典在开发中的应用,特别是在行业、省市区等多级下拉选择业务中的使用。通过创建一个包含id、name、value、type、grade、sort和pid等字段的enum表来实现。查询方式包括下拉选查询和树状结构查询,用于获取不同级别的分类数据。此外,还详细阐述了字段的含义和查询示例。
本文介绍了数据字典在开发中的应用,特别是在行业、省市区等多级下拉选择业务中的使用。通过创建一个包含id、name、value、type、grade、sort和pid等字段的enum表来实现。查询方式包括下拉选查询和树状结构查询,用于获取不同级别的分类数据。此外,还详细阐述了字段的含义和查询示例。
数据字典
1.需求
在开发中数据字典常被用于行业、省市区等下拉选业务中。
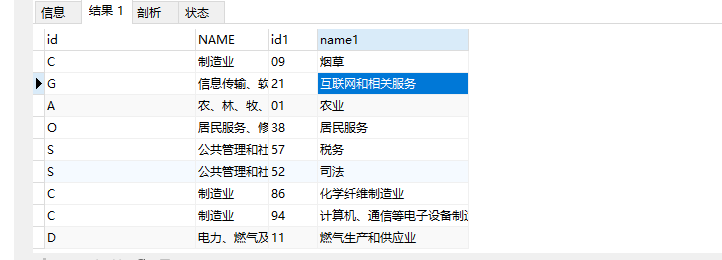
以下图为例,我们需要设计一个公共的数据字典表以适用于行业、省市区等多种类型的多级连带的下拉选业务
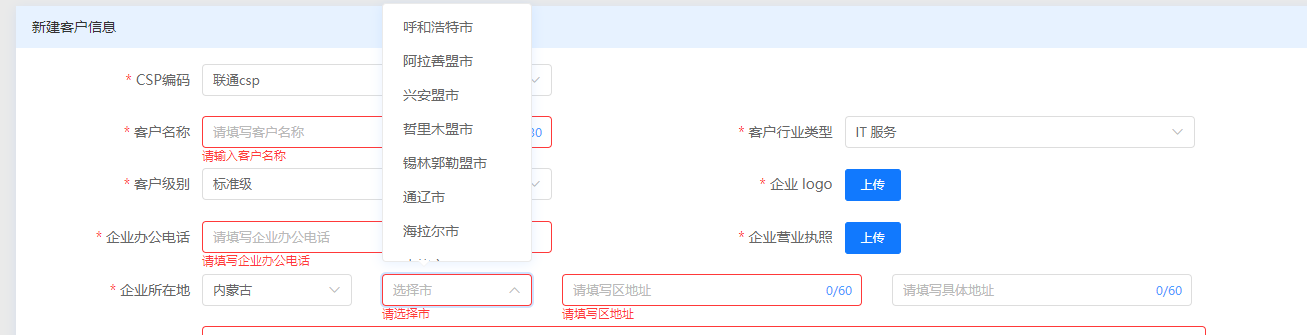
2.表机构设计
| id | varchar | 32 | 主键 |
|---|---|---|---|
| name | varchar | 32 | 枚举名称 |
| value | varchar | 32 | 枚举值 |
| type | varchar | 32 | 枚举类型 |
| grade | int | 1 | 等级(1:一级,2:二级,3:三级依次类推) |
| sort | int | 11 | 排序 |
| pid | varchar | 32 | 枚举上级id |
| del | int | 1 | 0正常1删除 |
2.1 建表语句
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for enum
-- ----------------------------
DROP TABLE IF EXISTS `enum`;
CREATE TABLE `enum` (
`id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '主键',
`name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '枚举名称',
`value` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '枚举值',
`type` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '枚举类型',
`grade` int(1) NULL DEFAULT 1 COMMENT '等级',
`sort` int(11) NULL DEFAULT NULL COMMENT '排序',
`pid` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '枚举上级id',
`del` int(1) NULL DEFAULT 0 COMMENT '0正常1删除',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
3.字段说明
**id:**这里其实id字段是可以选项,定义规则如:TELECOM_TRADE_TYPE对应1-xxx,MOBILE_TRADE_TYPE对应2-xxx
**name:**内容
**value和pid:**以下图为例,前面是定义了一级栏目,后面定义的是二级栏目;三级栏目以此类推,只需要将二级栏目的value值设置为对应三级栏目的pid即可。
type: 首先时便于查询,其次是可以根据不同的type定义相同value和pid
sort: 用于排序
**grade:**表示级别,如一级栏目grade=1,二级栏目grade=2,三级栏目grade=3 以此类推
**del:**逻辑删除状态 0-正常,1-删除
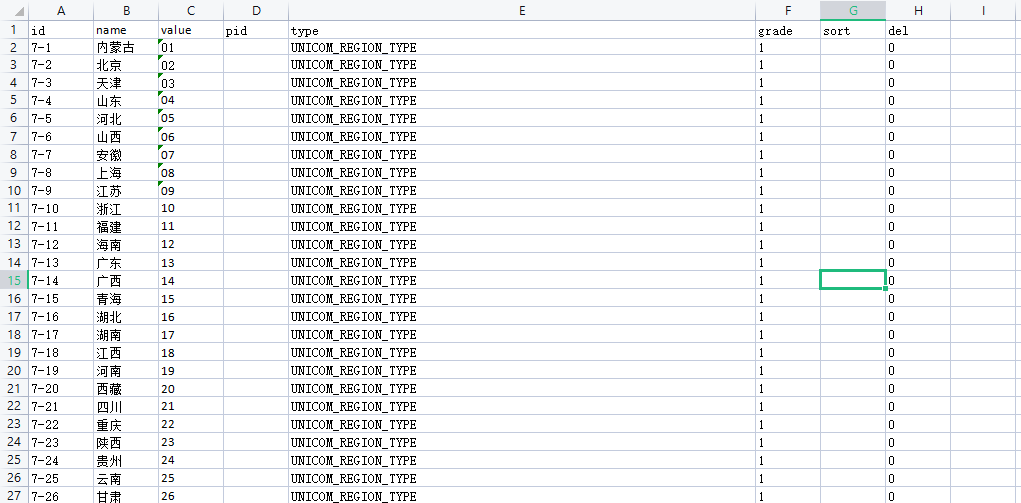
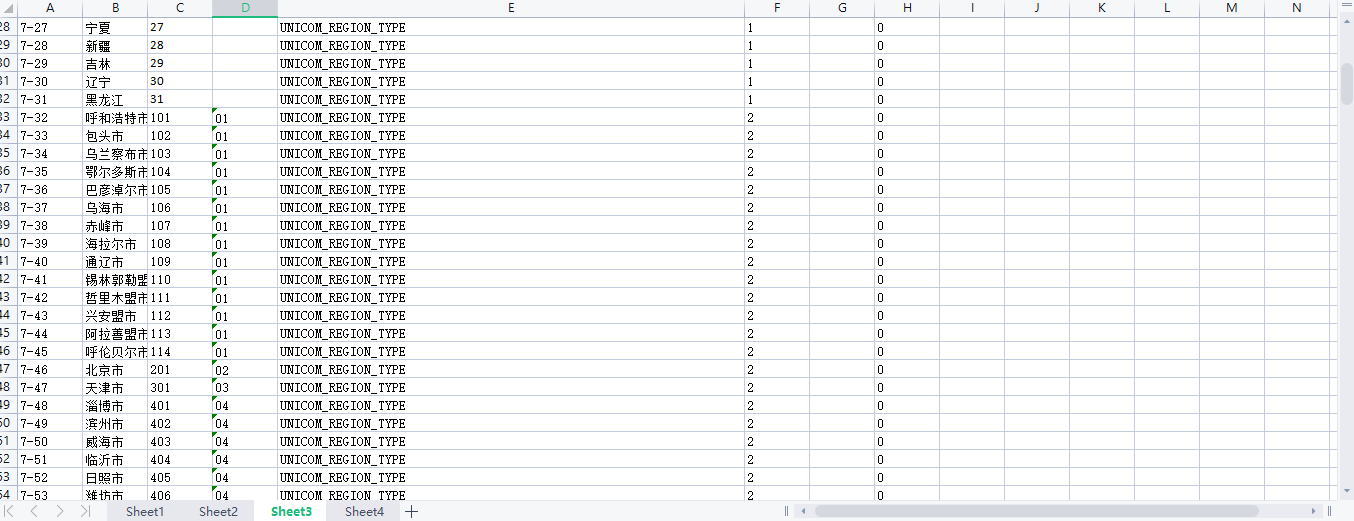
4.查询
1.下拉选查询方式
获取一级栏目
SELECT
`value` AS id,
`name` AS NAME
FROM
`enum` where `type` = 'TELECOM_TRADE_TYPE'
AND grade = 1
AND del = 0
order by sort
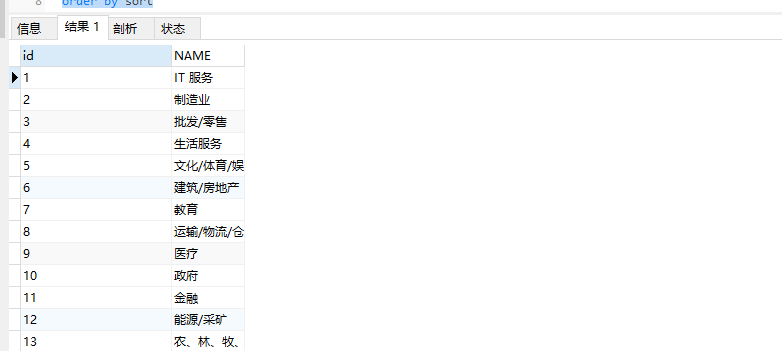
查询子级栏目
在查询到一级栏目之后,前端可以获取到所有一级栏目的id,子级栏目的查询时可以作为pid进行查询,以此类推
SELECT
`value` as id,
`name` as name
FROM
`enum`
where `type` = 'TELECOM_TRADE_TYPE'
AND pid = #{pid}
and del = 0
order by sort
2.树状结构查询
SELECT
a.VALUE
AS id,
a.NAME AS NAME,
b.
VALUE
AS id1,
b.NAME AS name1
FROM
`enum` a
LEFT JOIN `enum` b ON b.pid = a.`value`
AND b.`del` = 0
WHERE
a.type = #{type} AND a.`del` = 0 and a.`grade`=1 ORDER BY a.`sort`,b.`sort`

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









