






这篇文章很长...题库
但是不要被长度吓到了,我们已经将其分为四个部分(机器学习、统计信息、SQL、其他),以便你可以逐步了解它。
你可以使用这些问题来磨练知识并找出差距,然后填补这些空白。
我们希望你会发现这很有帮助,并祝你在数据科学的努力中好运!
机器学习基础
问1:在应用机器学习算法之前,数据争论和数据清理有哪些步骤?
当数据争论和数据清理时可以采取许多步骤。下面列出了一些最常见的步骤:
数据剖析:几乎每个人都从理解他们的数据集开始。更具体地说,你可以使用 .shape查看数据集的形状,并使用.describe查看数字变量的描述。
语法错误:这包括确保没有空格,确保字母大小写一致以及检查拼写错误。你可以使用 .unique或条形图检查拼写错误。
标准化或规范化:根据你使用的数据集和决定使用的机器学习方法,对数据进行标准化或标准化可能会很有用,这样不同比例的不同变量不会对模型的性能产生负面影响。
处理空值:有多种处理空值的方法,包括完全删除带有空值的行,将空值替换为均值/中位数/众数,将空值替换为新的类别(例如未知)、预测值,或使用可以处理空值的机器学习模型。在这里阅读更多。
其他事情包括:删除不相关的数据,删除重复项和类型转换。
问2:如何处理不平衡的二元分类?
首先,你想重新考虑用于评估模型的指标。模型的准确性可能不是最好的指标,因为我将用一个例子来说明原因。假设有99次银行提款不是欺诈行为,而1次提款是欺诈行为。如果你的模型仅将每个实例归类为“非欺诈性”,则其准确性为99%!因此,你可能要考虑使用精确度和召回率等指标。
改善不平衡二元分类的另一种方法是增加对少数群体分类错误的成本。通过增加这种惩罚,模型应该更准确地对少数群体进行分类。
最后,你可以通过对少数类进行过度采样或对多数类进行欠采样来改善类的平衡。你可以在这里读更多关于它的内容。
问3:箱线图和直方图有什么区别?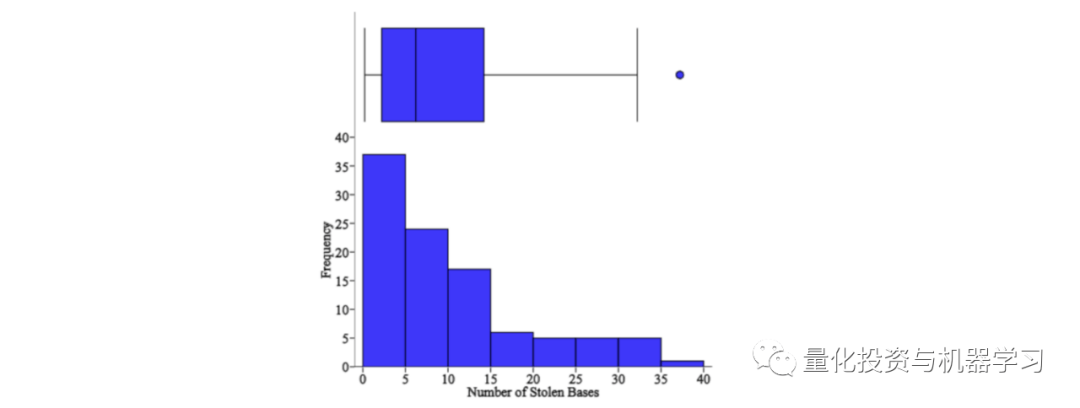
箱线图和直方图是用于显示数据分布的可视化效果,但它们以不同的方式传达信息。
直方图是显示数值变量的频率的条形图,并用于估计给定变量的概率分布。它使你可以快速了解分布的形状、变化和潜在的离群值。
箱线图传达数据分布的不同方面。虽然你无法通过箱形图看到分布的形状,但可以收集其他信息,例如四分位数、范围和离群值。当你想同时比较多个图表时,箱线图特别有用,因为它们比直方图占用更少的空间。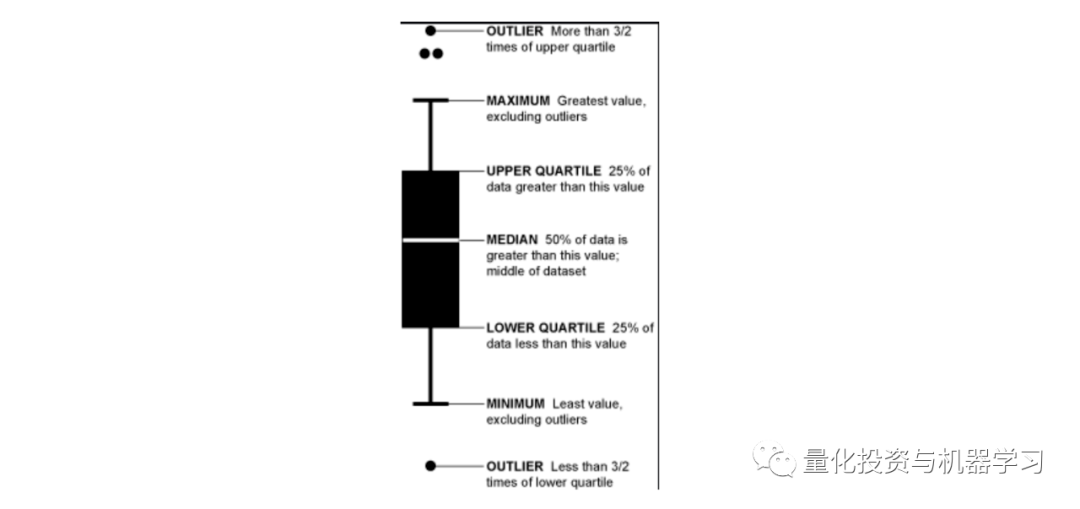
问4:请描述不同的正则化方法,例如L1和L2正则化?
L1和L2正则化都是用于减少训练数据过拟合的方法。最小二乘法可最小化残差平方和,这可能会导致低偏差但高方差。
L2正则化(也称为岭回归)可最小化残差平方和加上λ乘以斜率平方。这个附加术语称为“岭回归惩罚”。这会增加模型的偏差,使训练数据的拟合度变差,但也会降低方差。
如果采用岭回归惩罚并将其替换为斜率的绝对值,则将获得套索回归或L1正则化。
L2没有那么强大,但具有稳定的解决方案,并且始终是一个解决方案。L1更强大,但解决方案不稳定,可能有多个解决方案。
StatQuest在这里有关于套索和岭回归的精彩视频。
问5:神经网络基础知识
神经网络是受人脑启发的多层模型。像我们大脑中的神经元一样,上方的圆圈代表一个节点。蓝色圆圈代表输入层,黑色圆圈代表隐藏层,绿色圆圈代
表输出层。隐藏层中的每个节点代表输入所经历的函数,最终导致绿色圆圈中的输出。这些函数的正式术语称为sigmoid激活函数。
问6:什么是交叉验证?
交叉验证本质上是一种用于评估模型在新的独立数据集上的性能的技术。交叉验证的最简单示例是将数据分为两组:训练数据和测试数据,其中使用训练数据构建模型,使用测试数据测试模型。
问7:如何定义/选择指标?
没有一种“放之四海而皆准”的指标。选择用于评估机器学习模型的度量标准取决于多种因素:
- 它是回归还是分类任务?
- 业务目标是什么?例如:精确度与召回率
- 目标变量的分布是什么?
可以使用许多指标,包括调整后的r平方、MAE、MSE、精确度、召回率、准确度、f1得分等等。
问8:请解释什么是精确度和召回率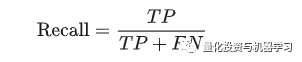
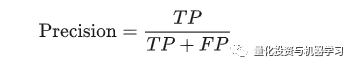
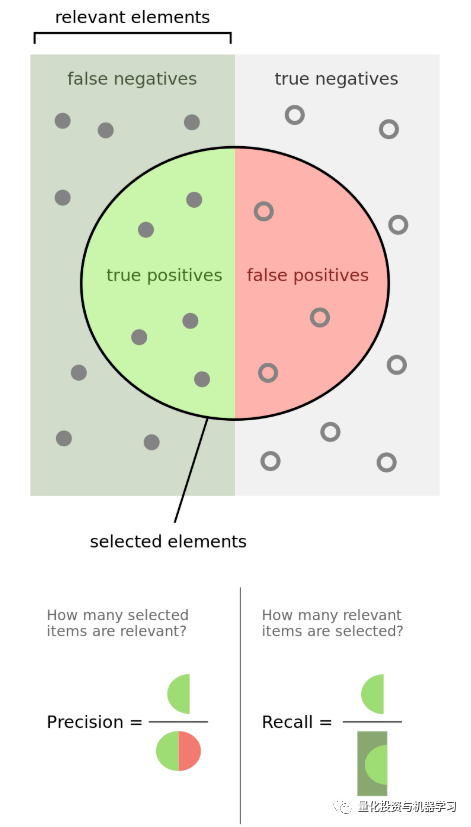
问9:请解释什么是假阳性和假阴性。为什么彼此之间很重要?举例说明假阳性比假阴性更重要,假阴性比假阳性更重要,以及当这两种类型的错误同等重要时
筛查癌症是假阴性比假阳性更重要的一个例子。更糟糕的是,当一个人患了癌症时却说他没有患癌症,而不是说某人患有癌症,后来又意识到他没有癌症。
这是一个主观论点,但从心理学的角度来看,假阳性可能比假阴性更糟。例如,由于人们通常不期望中奖,因此,赢得彩票的假阳性可能比假阴性结果更糟。
问10:监督学习和无监督学习有什么区别?给出具体的例子
监督学习涉及学习基于示例输入输出对[1]将输入映射到输出的函数men。
例如,如果我们有一个包含年龄(输入)和身高(输出)两个变量的数据集,我们可以实现一个监督学习模型,以根据一个人的年龄预测其身高。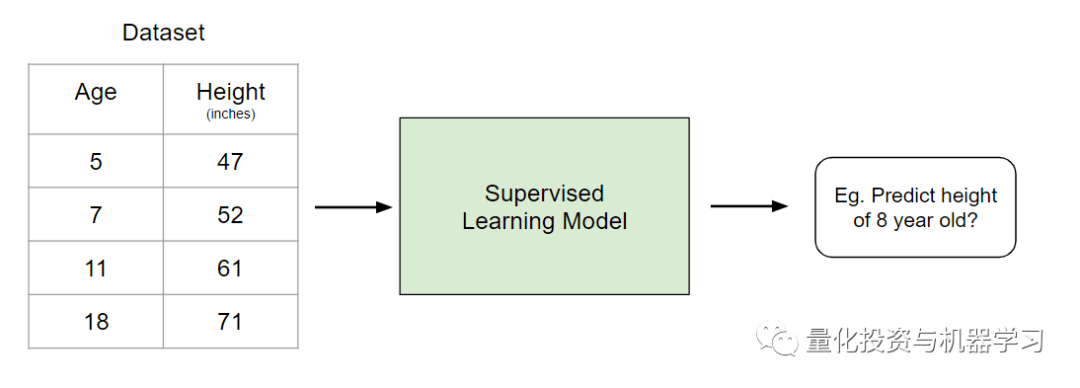
与监督学习不同,无监督学习用于得出推论并从输入数据中找到模式,而无需参考标记的结果。无监督学习的常见用法是通过购买行为来对客户进行分组以找到目标市场。
(ps,未完待续)















 450
450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









