










Python之批量数据处理
文章目录
- Python之批量数据处理
- 前言
- 一、汇总批量excel文件
- 二、批量汇总DOCX内容到表格
- 三、Debug
- 1.pip install DOCX:
- 2.SyntaxError:Missing parentheses in call to 'print' .Did you mean print('sucess')?
- 3.运行setup.py时出现no commands supplied 错误
- 4.IndentationError:expected an indented block
- 5.ModuleNotFoundError:No module named 'oenpyxl'
- 6.ImportError:DLL Load failed:找不到指定模块
- 7.ModuleNotFoundError: No module named 'cv2'
- 8.ModuleNotFoundError: No module named 'matplotlib'
- 9.python封装成exe
- 总结
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、汇总批量excel文件
需求描述:指定文件夹下有大批量的excel,我们需要汇总每个excel里面指定的行数据,手动复制粘贴,效率低,耗费时间长,不可取,我们采用python进行批量提取汇总。
1.源码
代码如下(示例):
# coding:utf-8
import xlrd #导入读取excel的模块,import语句用来导入其它python文件,称为module模块,使用该模块里定义的类,方法,或者变量,从而达到代码复用的目的
import os
import pandas as pd
import xlwt
from xlutils.copy import copy #xlutils模块的功能是xlrd和xlwt的桥梁,解决了xlrd中book对象无法编辑的问题,通过copy模块将xlrd.Book对象转换为xlwt.Workbook对象,从而实现原始excel文件的编辑功能。
"""
将文件夹下所有excel文件合并成一个文件
注意:
本代码仅支持合并excel文件第一个sheet,如果合并的excel文件有多个sheet,只会读取和合并第一个sheet,
需要合并的excel文件如果有多个sheet需要修改代码的merge_excel()函数
思路:
1.获取路径下所有文件,注意 本代码没有异常处理
2.新建一个excel文件,用于存储全部数据
3.逐个打开需要合并的excel文件,逐行读取数据,再用一个列表来保存每行数据。最后该列表中会存储所有的数据
4.向excel文件中逐行写入
"""
def get_allfile_msg(file_dir):
for root, dirs, files in os.walk(file_dir):
'''
print(root) #当前目录路径
print(dirs) #当前路径下所有子目录
print(files) #当前路径下所有非目录子文件
'''
return root, dirs, [file for file in files if file.endswith('.xls') or file.endswith('.xlsx')]
def get_allfile_url(root, files):
"""
将目录的路径加上'/'和文件名,组成文件的路径
:param root: 路径
:param files: 文件名称集合
:return: none
"""
allFile_url = []
for file_name in files:
file_url = root + '/' + file_name
allFile_url.append(file_url)
return allFile_url
def all_to_one(root, allFile_url, file_name='allExcel.xls', title=None, have_title=True):
"""
合并文件
:param root: 输出文件的路径
:param allFile_url: 保存了所有excel文件路径的集合
:param file_name: 输出文件的文件名
:param title: excel表格的表头
:param have_title: 是否存在title(bool类型),默认为true,不读取excel文件的第0行
:return: none
"""
# 首先在该目录下创建一个excel文件,用于存储所有excel文件的数据
file_name = root + '/' + file_name
create_excel(file_name, title)
list_row_data = []
for f in allFile_url:
# 打开excel文件
print('打开%s文件' % f)
excel = xlrd.open_workbook(f)
# 根据索引获取sheet,这里是获取第一个sheet
table = excel.sheet_by_index(0)
print('该文件行数为:%d,列数为:%d' % (table.nrows, table.ncols))
# 获取excel文件所有的行
for i in range(28,table.nrows):
# 如果存在表头,则跳过第0行,否则不跳过
if have_title and i == 0:
continue
else:
row = table.row_values(11) # 获取整行的值,返回列表
list_row_data.append(row)
row = table.row_values(12) # 获取整行的值,返回列表
list_row_data.append(row)
row = table.row_values(22) # 获取整行的值,返回列表
list_row_data.append(row)
row = table.row_values(23) # 获取整行的值,返回列表
list_row_data.append(row)
row = table.row_values(25) # 获取整行的值,返回列表
list_row_data.append(row)
row = table.row_values(26) # 获取整行的值,返回列表
list_row_data.append(row)
print('总数据量为%d' % len(list_row_data))
# 写入all文件
add_row(list_row_data, file_name)
# 创建文件名为file_name,表头为title的excel文件
def create_excel(file_name, title):
print('创建文件%s' % file_name)
a = xlwt.Workbook()
# 新建一个sheet
table = a.add_sheet('sheet1', cell_overwrite_ok=True)
# 写入数据
for i in range(len(title)):
table.write(0, i, title[i])
a.save(file_name)
# 向文件中添加n行数据
def add_row(list_row_data, file_name):
# 打开excel文件
allExcel1 = xlrd.open_workbook(file_name)
sheet = allExcel1.sheet_by_index(0)
# copy一份文件,准备向它添加内容
allExcel2 = copy(allExcel1)
sheet2 = allExcel2.get_sheet(0)
# 写入数据
i = 0
for row_data in list_row_data:
for j in range(len(row_data)):
sheet2.write(sheet.nrows + i, j, row_data[j])
i += 1
# 保存文件,将原文件覆盖
allExcel2.save(file_name)
print('合并完成')
if __name__ == '__main__':
# 设置文件夹路径,
# file_dir = 'D:\SoftWare\PythonWorkSpace\excel-test'
file_dir = r'C:\Users\gxcaoty\AppData\python3.7\test\test01\4'
# 获取文件夹的路径,该路径下的所有文件夹,以及所有文件
root, dirs, files = get_allfile_msg(file_dir)
# 拼凑目录路径+文件名,组成文件的路径,用一个列表存储
allFile_url = get_allfile_url(root, files)
# 设置文件名,用于保存数据
file_name = 'output.xls'
# 设置excle文件表头
title = ['UA3P', '检测项目','管控标准','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15','16','日期','合格率']
# have_title参数默认为True,为True时不读取excel文件的首行
all_to_one(root, allFile_url, file_name=file_name, title=title, have_title=True)
二、批量汇总DOCX内容到表格
1.本节学习内容来自【程序员大飞】(亲测可用):

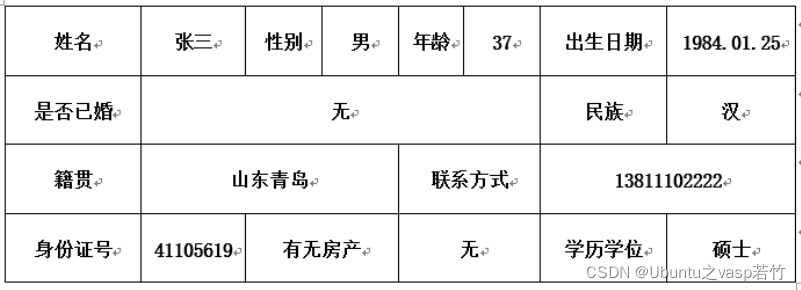
需求描述:将含有数个上面形式的 word 文档整理,利用 python 自动生成下面 excel 表格形式!!

2.源码
代码如下(示例):
import docx
import pandas as pd
import os
from win32com import client as wc
word_paths = (r"C:\Users\gxcaoty\AppData\python3.7\test\test13")
def convertdoc_docx(path):
# doc 转化为 docx
path_list = os.listdir(path)
doc_list = [os.path.join(path,str(i)) for i in path_list if str(i).endswith('doc')]
word = wc.Dispatch('Word.Application')
for path in doc_list:
print(path)
save_path = str(path).replace('doc','docx')
doc = word.Documents.Open(path)
doc.SaveAs(save_path,12, False, "", True, "", False, False, False, False)
doc.Close()
print('{} Save sucessfully '.format(save_path))
word.Quit()
convertdoc_docx(word_paths)
wordlist_path = [os.path.join(word_paths,i) for i in os.listdir(word_paths) if str(i).endswith('.docx')]
def GetData_frompath(doc_path):
'''
Generate Data form doc_path of word path
:param doc_path:
:return: col_keys 列键;
col_values 列名;
'''
document = docx.Document(doc_path)
col_keys = [] # 获取列名
col_values = [] # 获取列值
index_num = 0
# 添加一个去重机制
fore_str = ''
for table in document.tables:
for row_index,row in enumerate(table.rows):
for col_index,cell in enumerate(row.cells):
if fore_str != cell.text:
if index_num % 2==0:
col_keys.append(cell.text)
else:
col_values.append(cell.text)
fore_str = cell.text
index_num +=1
col_values[7] = '\t'+col_values[7]
col_values[8] = '\t'+col_values[8]
print(f'col keys is {col_keys}')
print(f'col values is {col_values}')
return col_keys,col_values
pd_data = []
for index,single_path in enumerate(wordlist_path):
col_names,col_values = GetData_frompath(single_path)
if index == 0:
pd_data.append(col_names)
pd_data.append(col_values)
else:
pd_data.append(col_values)
df = pd.DataFrame(pd_data)
df.to_csv(word_paths+'/result.csv', encoding='utf_8_sig',index=False)
三、Debug
1.pip install DOCX:


解决:包不对,换成正确的包即可;
pip3 install docx 安装模块 docx 后,发现不能正常使用,并报错 moduleNotFoundError:No module named ‘exceptions’
1、卸载原来安装的docx
pip uninstall docx
2、安装 python-docx 模块即可
pip install python-docx
2.SyntaxError:Missing parentheses in call to ‘print’ .Did you mean print(‘sucess’)?

解决:
python2.X版本与python3.X版本输出方式不同造成的在python3.X的,输入内容时都要带上括号python()
3.运行setup.py时出现no commands supplied 错误
解决:
python setup.py
实际改为 python setup.py install
4.IndentationError:expected an indented block

解决:用tab键在对应语句下添加缩进;
5.ModuleNotFoundError:No module named ‘oenpyxl’
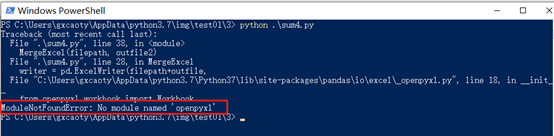
解决:pip install openpyxl
6.ImportError:DLL Load failed:找不到指定模块
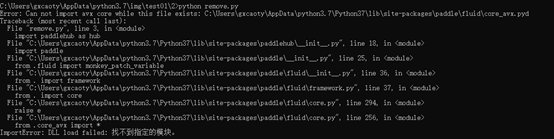
解决:安装VC_redist.x64
-2015-64位下载地址:
https://www.microsoft.com/zh-cn/download/confirmation.aspx?id=48145
手动下载:
64位: https://download.microsoft.com/download/9/3/F/93FCF1E7-E6A4-478B-96E7-D4B285925B00/vc_redist.x64.exe
32位: https://download.microsoft.com/download/9/3/F/93FCF1E7-E6A4-478B-96E7-D4B285925B00/vc_redist.x86.exe
其它版本:https://docs.microsoft.com/en-US/cpp/windows/latest-supported-vc-redist?view=msvc-170
7.ModuleNotFoundError: No module named ‘cv2’
解决:
pip install opencv-python (如果只用主模块,使用这个命令安装)
pip install opencv-contrib-python (如果需要用主模块和contrib模块,使用这个命令安装)
8.ModuleNotFoundError: No module named ‘matplotlib’
解决:
%pip install matplotlib (如果只用主模块,使用这个命令安装)
%如果显示失败,安装不成功,这是因为网速原因,直接访问国外网站导致超时等原因。此时需要在国内的豆瓣镜像进行安装,命令如下
%pip install XXX -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com(XXX是我们需要安装的包名称)
matplotlib是python中强大的画图模块。
首先确保已经安装python,然后用pip来安装matplotlib模块。
进入到cmd窗口下,建议执行python -m pip install -U pip setuptools进行升级。
接着键入python -m pip install matplotlib进行自动的安装,系统会自动下载安装包。
安装完成后,可以用python -m pip list查看本机的安装的所有模块,确保matplotlib已经安装成功。
9.python封装成exe
解决:
pip install pyinstaller
pyinstaller –F .py
总结
有不对的地方希望大家可以评论留言,帮助大家不迷路!!
期待大家的加入,一起学习,一起交流!!















 1172
1172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











