







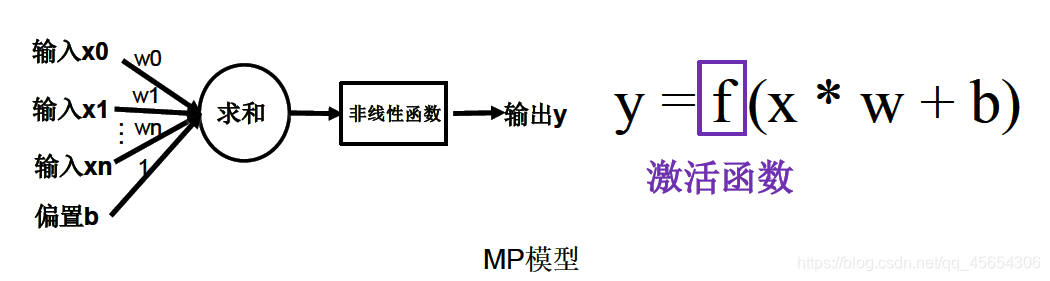
激活函数的概念
对于简化的神经元模型,没有设计激活函数,因此无论设计多少层神经结构,最终得到的都是线性结构。

因此,我们在神经元进行乘加运算的神经元体后面增加一个激活函数,以增强模型的表达力。(激活函数非线性时,多层神经网络可逼近所有函数)
激活函数的特征
优秀的激活函数应有以下几个特征:
非线性:
激活函数非线性时,多层神经网络可逼近所有函数。
非线性也就是导数不是常数。这个条件是多层神经网络的基础,保证多层网络不退化成单层线性网络。这也是激活函数的意义所在。任意多个线性函数的组合还是线性函数,因此只要隐藏层的输出是线性的,无论多少层,都是和一个隐藏层是一回事,只有在线性回归问题中的输出层才会用到线性激励函数,但是实际上对于回归任务,你完全可以不使用激活函数。
可微性:
优化器大多用梯度下降更新参数,可微性保证了在优化中梯度的可计算性。传统的激活函数如sigmoid等满足处处可微。对于分段线性函数比如ReLU,只满足几乎处处可微(即仅在有限个点处不可微)。对于SGD算法来说,由于几乎不可能收敛到梯度接近零的位置,有限的不可微点对于优化结果不会有很大影响。
单调性:
当激活函数是单调的,单调性使得在激活函数处的梯度方向不会经常改变,保证单层网络的损失函数是凸函数,从而让训练更容易收敛。
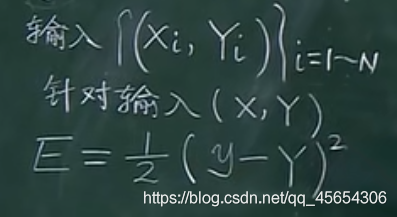
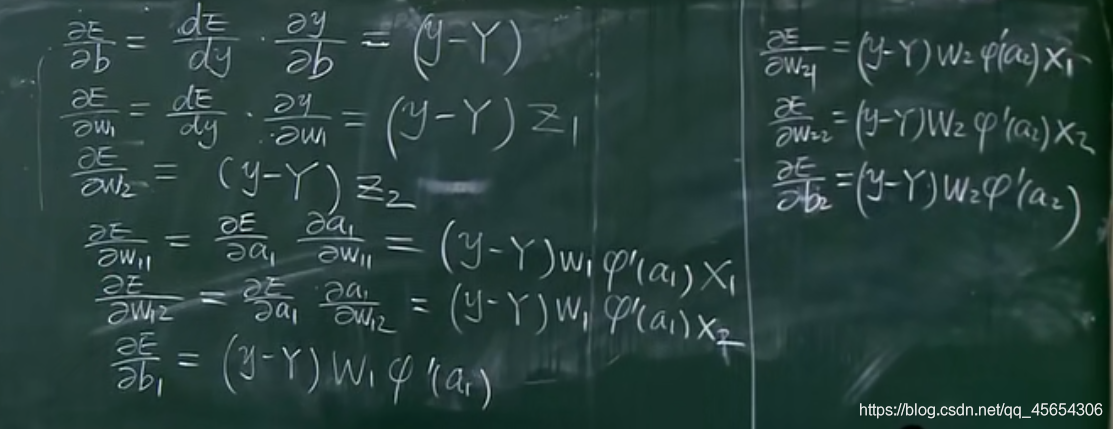
近似恒等性:
f(x)≈x当参数初始化为随机小值时,神经网络更稳定。这样的好处是使得输出的幅值不会随着深度的增加而发生显著的增加,从而使网络更为稳定,同时梯度也能够更容易地回传。这个与非线性是有点矛盾的,因此激活函数基本只是部分满足这个条件,比如TanH只在原点附近有线性区(在原点为0且在原点的导数为1),而ReLU只在x>0时为线性。这个性质也让初始化参数范围的推导更为简单。额外提一句,这种恒等变换的性质也被其他一些网络结构设计所借鉴,比如CNN中的ResNet和RNN中的LSTM。
参考:https://blog.csdn.net/junjun150013652/article/details/81487059
激活函数输出值的范围:
激活函数输出为有限值时,特征的表示受有限权值的影响更显著,权重对特征的影响更大,基于梯度的优化方法更稳定
激活函数输出为无限值时,参数的初始值对特征的影响更大,建议调小学习率
常用的激活函数
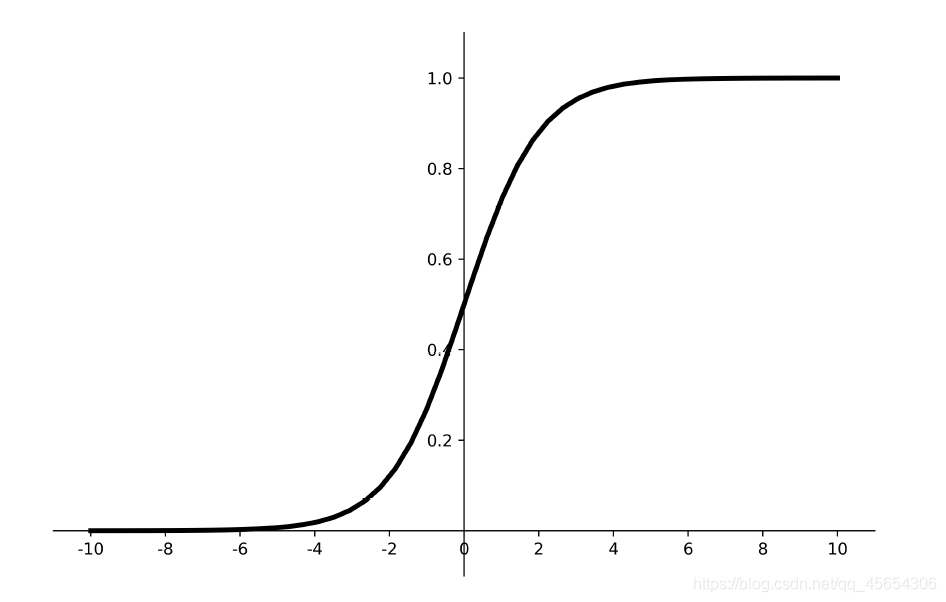
sigmoid
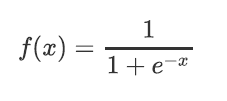
函数图像如下:
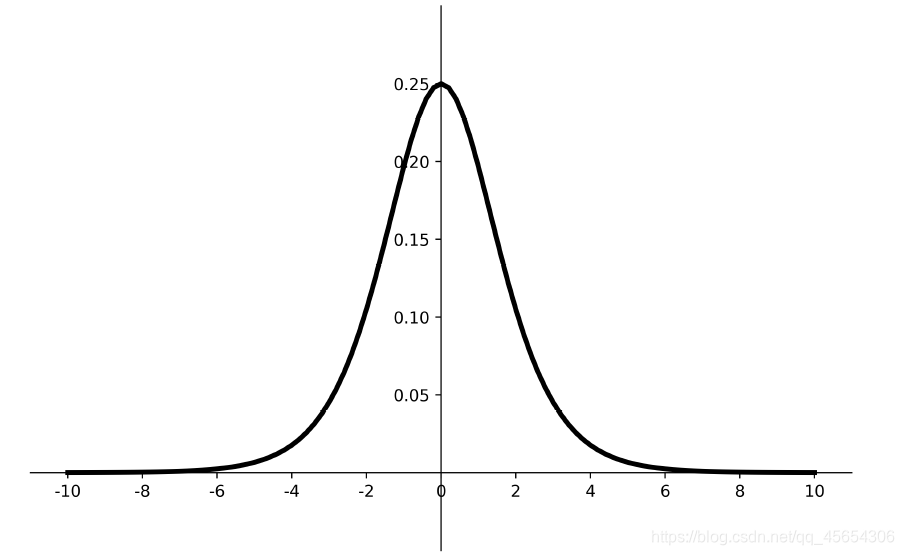
导数图像如下:
优点:
- 输出映射在(0,1)之间(相当于做了归一化),单调连续,输出范围有限,优化稳定,可用作输出层;
- 求导容易。
缺点:
- 易造成梯度消失;其导数0-0.25,经过多层的神经网络链式求导,最终会造成梯度消失。
- 输出非0均值,收敛慢;(我们希望神经元的输入以0为均值,这就要求激活函数的输出要以0为均值)
- 幂运算复杂,训练时间长。
sigmoid函数可应用在训练过程中。然而,当处理分类问题作出输出时,sigmoid却无能为力。简单地说,sigmoid函数只能处理两个类,不适用于多分类问题。而softmax可以有效解决这个问题,并且softmax函数大都运用在神经网路中的最后一层网络中,使得值得区间在(0,1)之间,而不是二分类的。
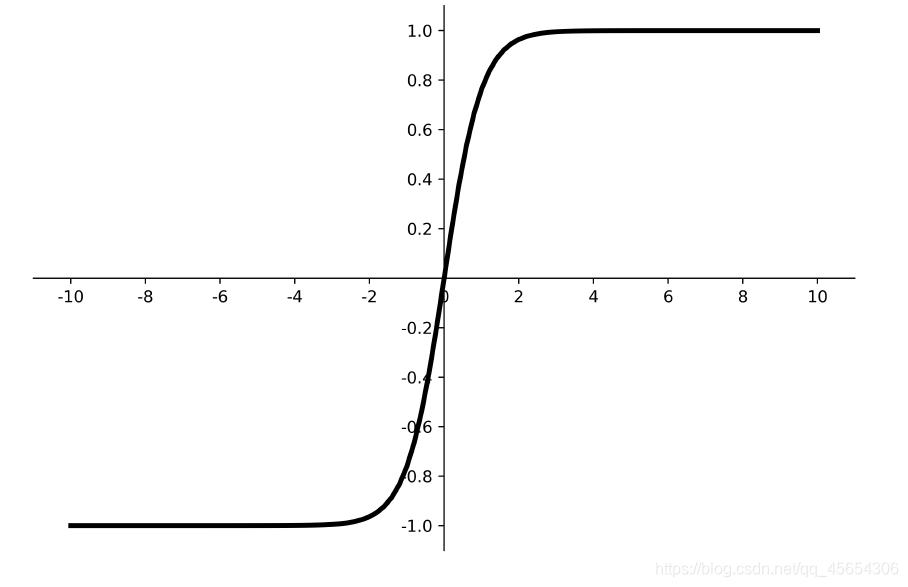
tanh
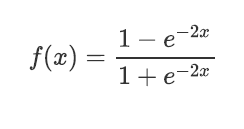
函数图像
导数图像
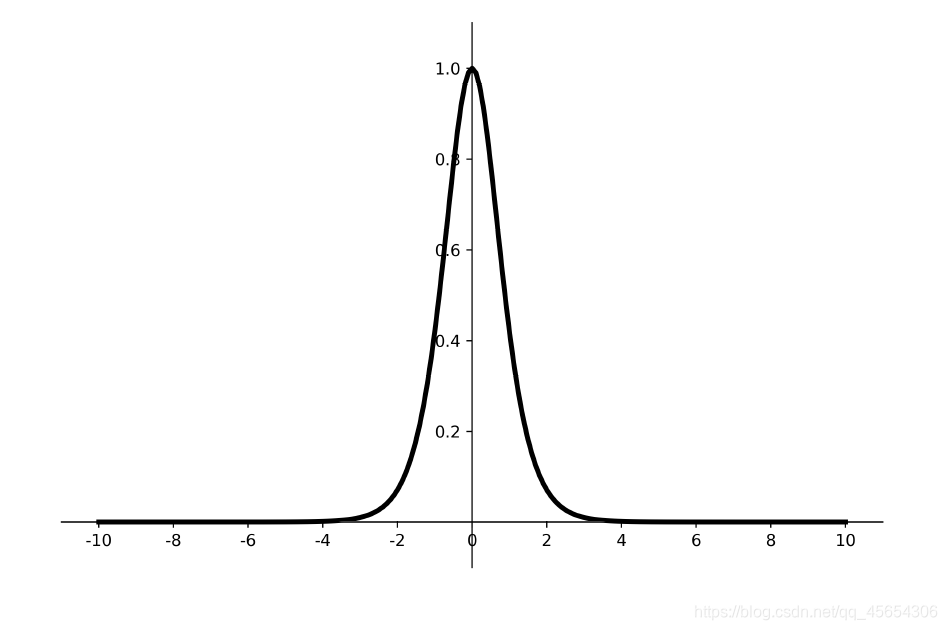
优点:
- 比sigmoid函数收敛速度更快。
- 相比sigmoid函数,其输出以0为中心。
缺点: - 易造成梯度消失;
- 幂运算复杂,训练时间长。
ReLU
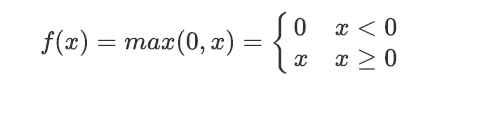
函数图像
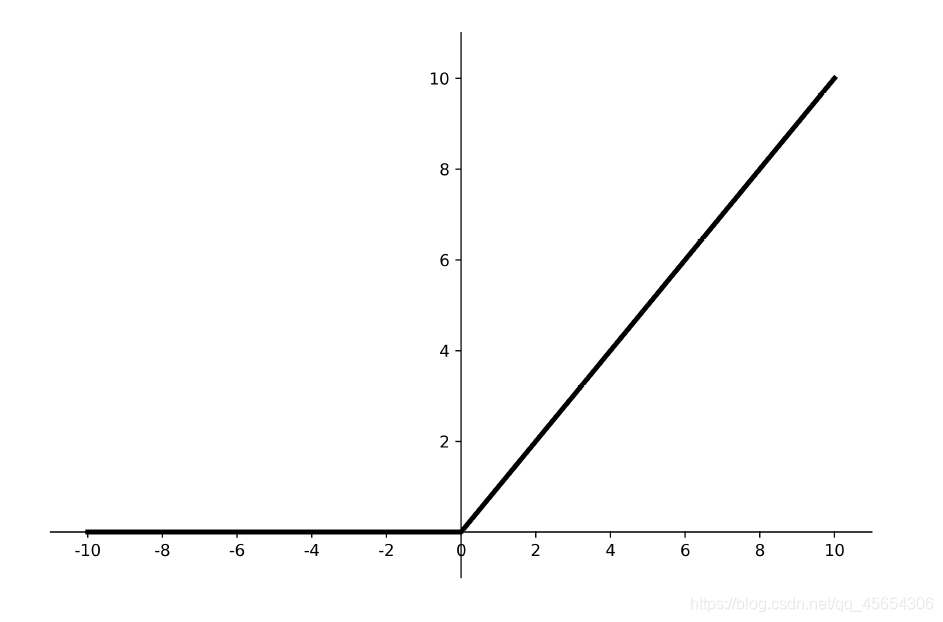
导数图像
优点:
- 解决了梯度消失问题(在正区间);
- 只需判断输入是否大于0,计算速度快;
- 收敛速度远快于sigmoid和tanh,因为sigmoid和tanh涉及很多expensive的操作;
- 提供了神经网络的稀疏表达能力。
缺点:
- 输出非0均值,收敛慢;
- Dead ReLU问题:某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。
由于DeadReLU的问题,我们一开始随机初始化时,应该尽量选取正区间的值,此外,为了避免训练过程中产生过多的负数参数,要将学习率适当调小。
Leaky ReLU
解决了ReLU的致命问题——DeadReLU
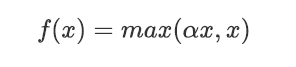
函数图像
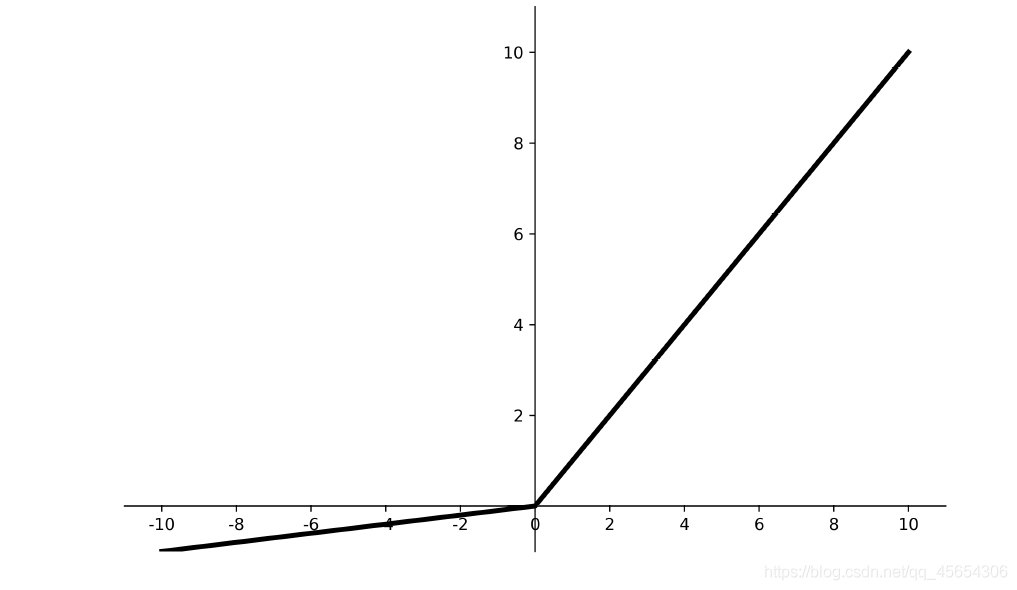
导数图像
理论上来讲,Leaky ReLU有ReLU的所有优点,外加不会有Dead ReLU问题,但是在实际操作当中,并没有完全证明Leaky ReLU总是好于ReLU。
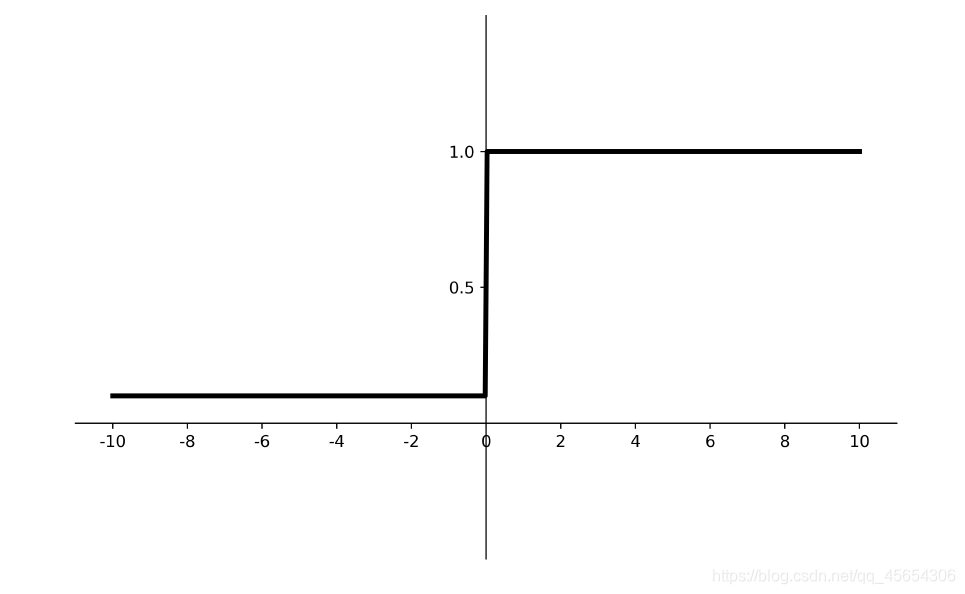
softmax
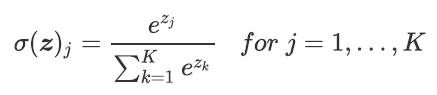
对神经网络全连接层输出进行变换,使其服从概率分布,即每个值都位于[0,1]区间且和为1。
总结















 8227
8227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









