







爬虫第一天,跟着老师练习了几个小案例
一、简易网页采集器
模仿浏览器查找相关内容
以搜狗为例,在搜索栏中输入需要搜索的内容,则会得到如下内容
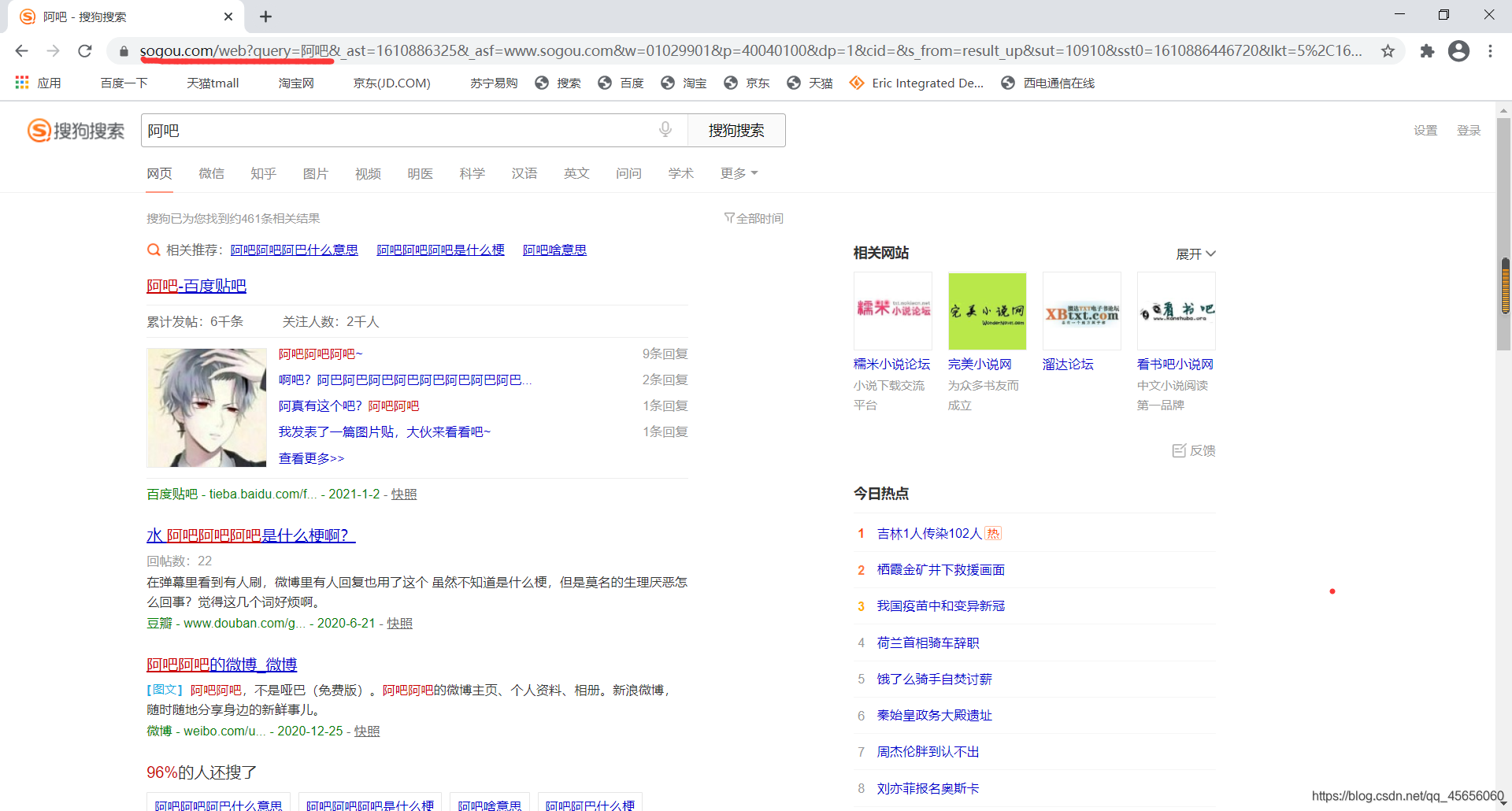
此时可以看到在网页链接后面还有一长串的字符串,而query后面对应的就是我们搜索的关键词,去掉后面的字符串,只保留https://www.sogou.com/web?query=阿吧网页依旧可以打开
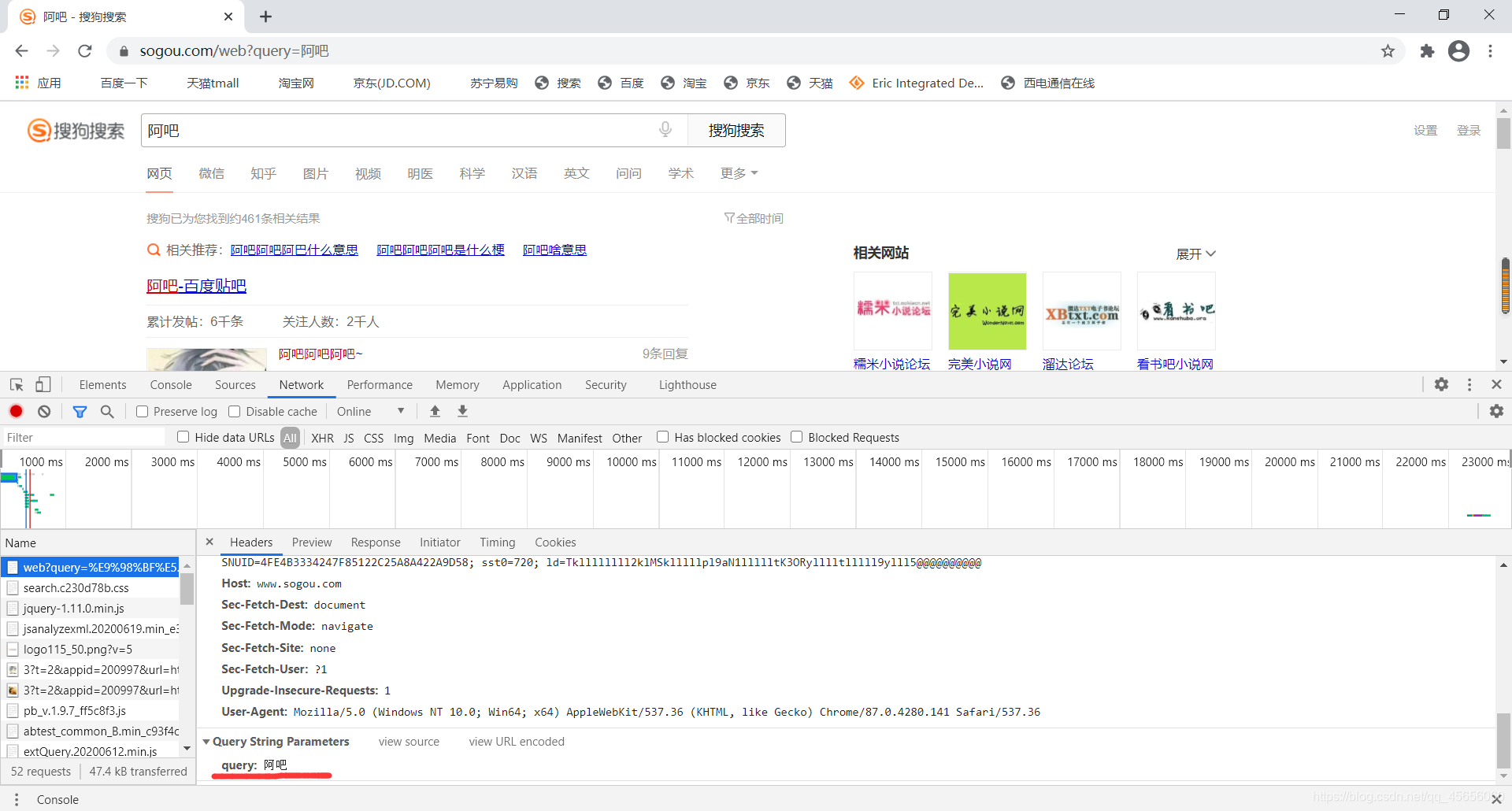
因此,我们将query后面的参数设置成动态的,话不多说,上代码
import requests
if __name__=='__main__':
url='https://www.sogou.com/web'
kw=input('qsr:')
header={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
#如果有多组参数,都需要加进去
param={
'query':kw
}
response=requests.get(url=url,params=param,headers=header)
filename=kw+'.html'
with open(filename,'w',encoding='utf-8') as fp:
fp.write(response.text)
二、百度翻译破解
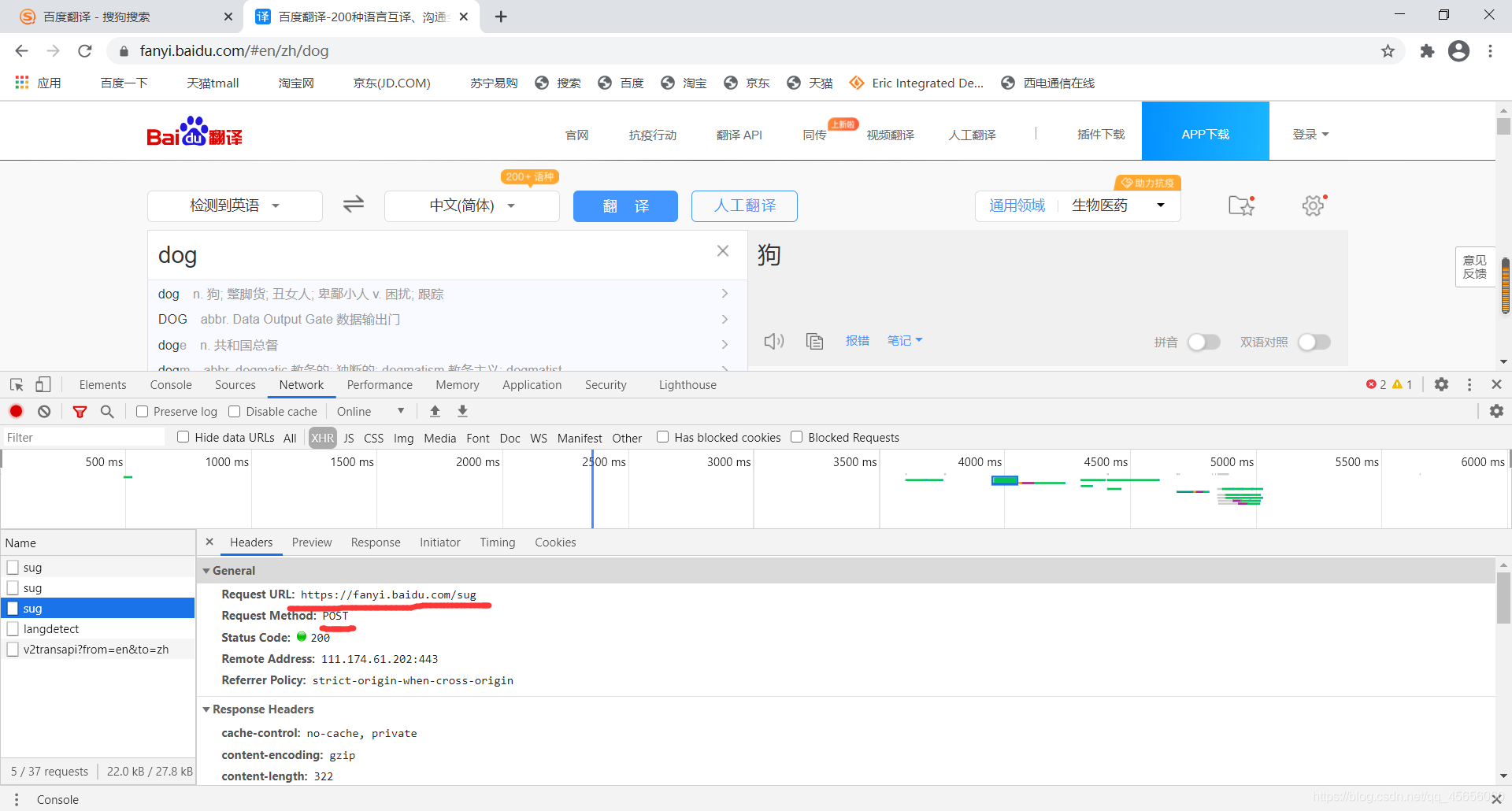
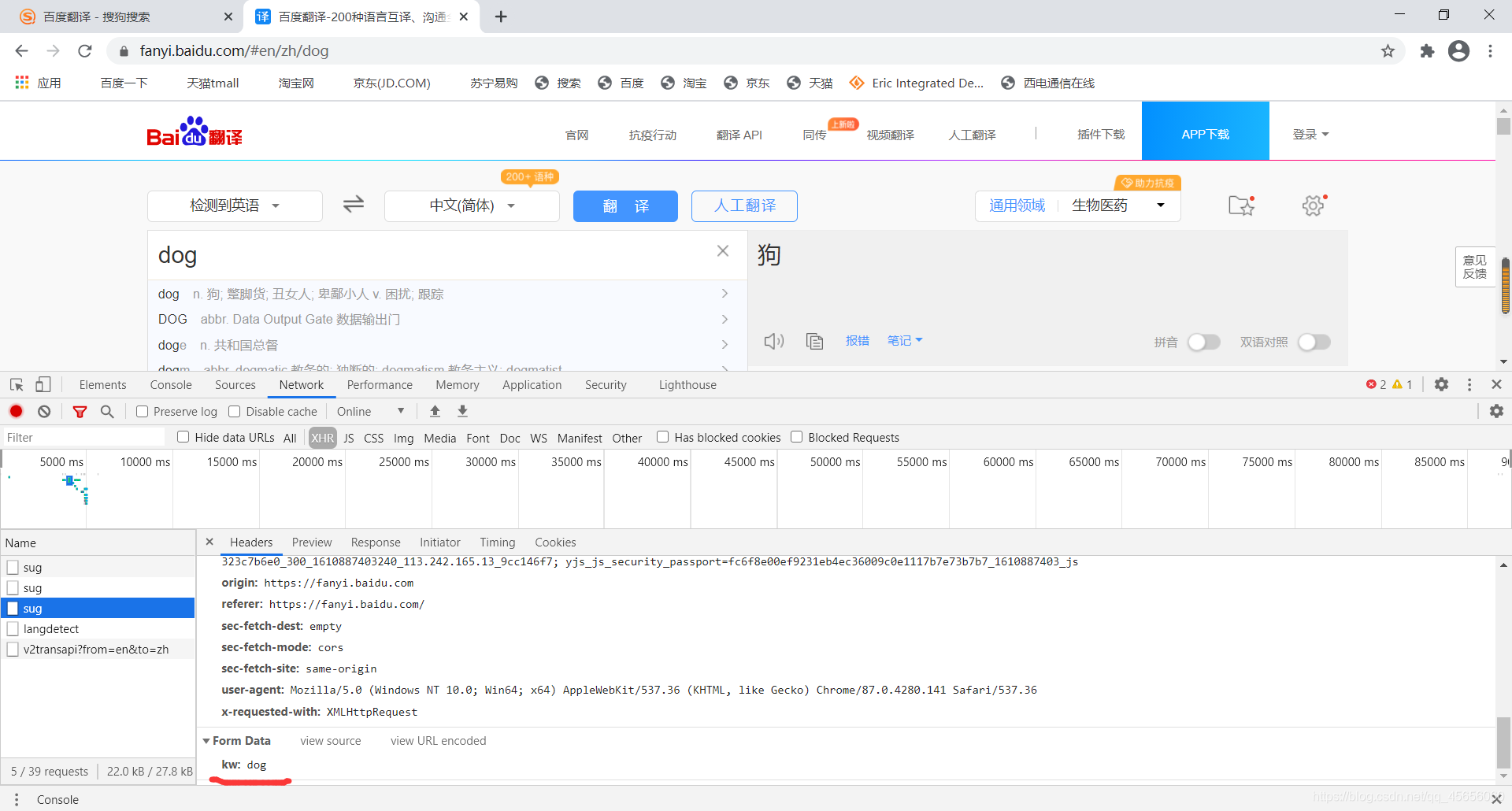
import requests
import json
url='https://fanyi.baidu.com/sug'
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
word=input()
data={
'kw':word
}
response=requests.post(url=url,data=data,headers=headers)
dic_json=response.json()
filename=word+'.json'
fp=open(filename,'w',encoding='utf-8')
json.dump(dic_json,fp=fp,ensure_ascii=False)
三、豆瓣电影
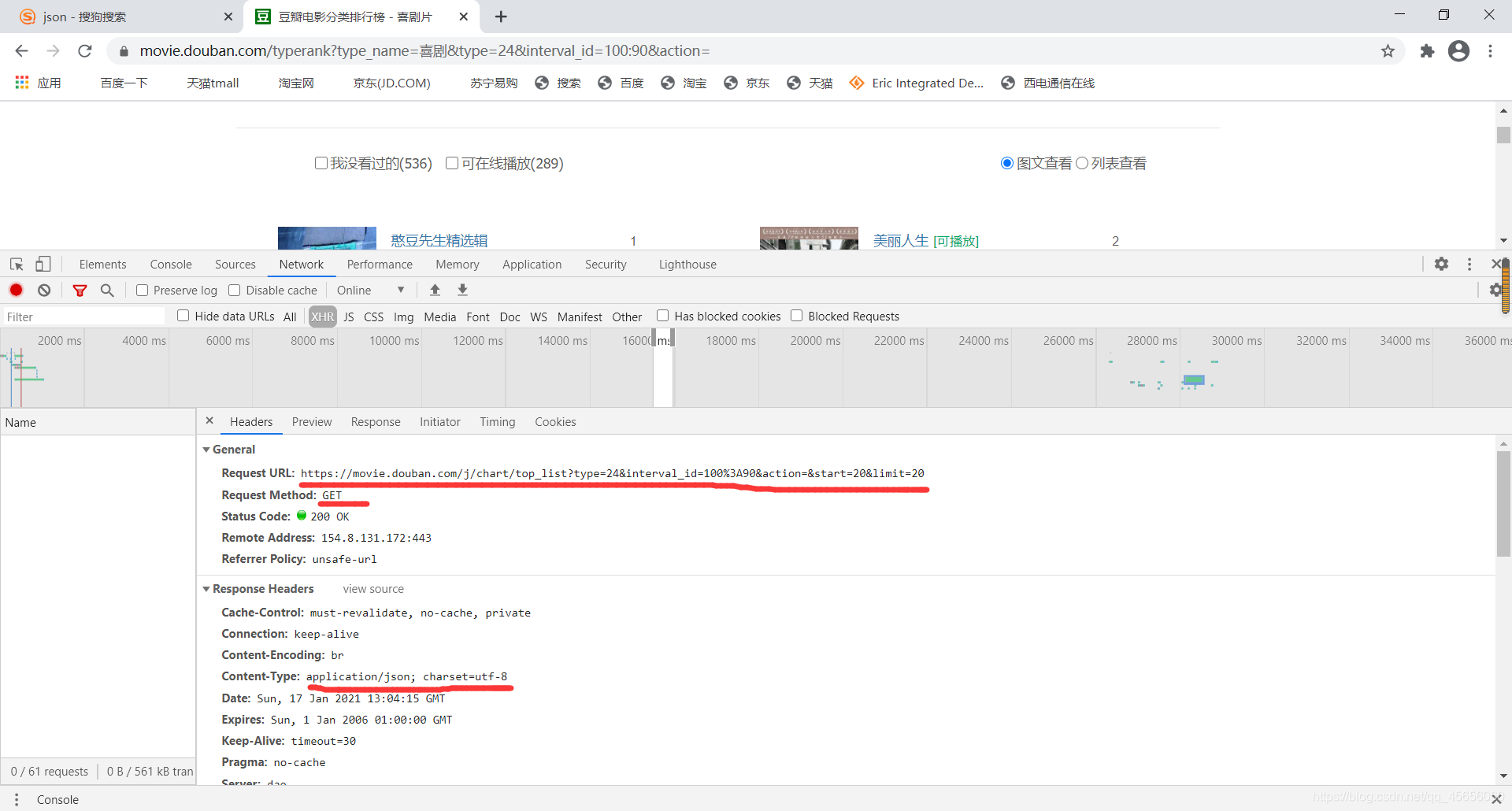
删除“?”后面多余的参数
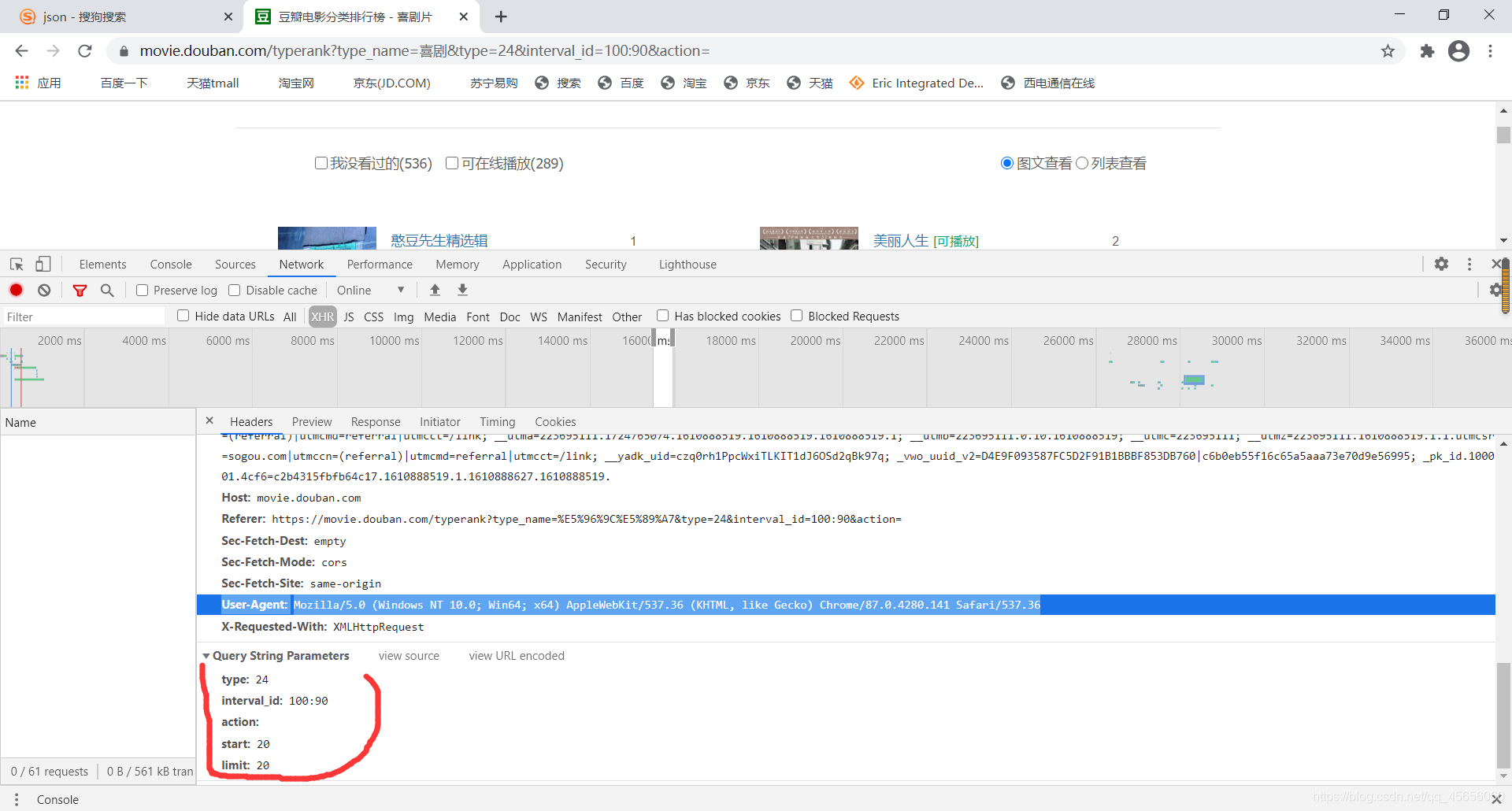
在代码当中添加相应的参数即可,其中star表示在电影数据库中取得第几部电影,limit表示一次取出的个数
import requests
import json
if __name__=='__main__':
url='https://movie.douban.com/j/chart/top_list'
data={
'type':'24',
'interval_id': '100:90',
'action': '',
'start': '20',
'limit': '20'
}
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
response=requests.get(url=url,params=data,headers=headers)
data_list=response.json()
fp=open('./douban.json','w',encoding='utf-8')
json.dump(data_list,fp=fp,ensure_ascii=False)














 867
867











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









