







cs61b实验记录(八)project 3:BearMaps
由于本学期我们开了一门Android课,所以我对这个project做了一些扩展,将它移植到了Android上。本篇文章只是我在做project3时的记录,我的这篇文章(Android课程设计:基于离线地图服务器的Android地图应用)对此project的实现做了更加详细的描述。如果有兴趣,可以参考上面的文章。
Application Structure
Your job for this project is to implement the back end of a web server. To use your program, a user will open an html file in their web browser that displays a map of the city of Berkeley, and the interface will support scrolling, zooming, and route finding (similar to Google Maps).We’ve provided all of the front end code. Your code will be the “back end” which does all the hard work of figuring out what data to display in the web browser.
The user’s web browser provides a URL to your Java program, and your Java program will take this URL and generate the appropriate output, which will displayed in the browser.
The job of the back end server (i.e. your code) is take this URL and generate an image corresponding to a map of the region specified inside the URL. This image will be passed back to the front end for display in the web browser.
Assignment Overview
- The
Rastererclass will take as input an upper left latitude and longitude, a lower right latitude and longitude, a window width, and a window height. Using these six numbers, it will produce a 2D array of filenames corresponding to the files to be rendered. - The
GraphDBclass will read in the Open Street Map dataset and store it as a graph. Each node in the graph will represent a single intersection, and each edge will represent a road. - The
Routerclass will take as input aGraphDB, a starting latitude and longitude, and a destination latitude and longitude, and it will produce a list of nodes (i.e. intersections) that you get from the start point to the end point.
we can debug map.html on browser’s Javascript console : on Windows, in Chrome you can press F12 to open up the developer tools, click the network tab, and all calls to your MapServer should be listed under type xhr, and if you mouse-over one of these xhr lines, you should see the full query appear

we can also see the replies from our MapServer in the console tab
Rasterer
这个类根据就是根据用户输入的左上角的经度和纬度(ullon,ullat: upper left longitude,latitude),右下角的经度和纬度(lrlon,lrlat),以及窗口的宽和高这六个参数来在数据集中寻找满足要求的图片,或者是由多张图片拼接而成的一张满足要求的图片,最后以字符串数组的形式返回这些图片的名字。我们称用户要求的查询区域(即由ullon,ullat,lrlon,lrlat构成的正方形区域)为query box。
MapServer类接受Rasterer类返回字符串数组,将对应的这些图片拼接在一起展示在屏幕上,就是用户的查询结果。
我们要求生成的图片:
-
包含query box中的所有区域,也就是说经度和纬度的范围必须要大于等于query box的范围
-
LonDPP小于等于query box的LonDPP,并且为了不进行无意义的计算,同时还要是这个范围中最大的。LonDPP=经度范围/图片的宽度(像素),这个值实际上就是地图的分辨率,我们生成的图片的分辨率必须要高于用户要求的分辨率,那么这个值就必须小于等于query box的值。而已知生成的图片的经度范围必须大于等于query box的经度范围,所以它的图片的像素大小也至少大于query box的像素大小。
所以,给定一个查找,我们需要做如下几步工作:
- 根据query box的分辨率,确定返回图片的分辨率,确定要在哪一层寻找图片
- 根据query box的经度和纬度,确定返回这一层中的哪几张图片
public class Rasterer {
private static final double ULLON=MapServer.ROOT_ULLON;
private static final double LRLON=MapServer.ROOT_LRLON;
private static final double ULLAT=MapServer.ROOT_ULLAT;
private static final double LRLAT=MapServer.ROOT_LRLAT;
private static final double LONG_WIDTH=Math.abs(LRLON-ULLON);
private static final double LAT_HEIGHT=Math.abs(ULLAT-LRLAT);
private static final double TILE_SIZE=MapServer.TILE_SIZE;
public Rasterer() {
// YOUR CODE HERE
}
public Map<String, Object> getMapRaster(Map<String, Double> params) {
// System.out.println(params);
Map<String, Object> results = new HashMap<>();
double lrlon = params.get("lrlon");
double ullon = params.get("ullon");
double lrlat = params.get("lrlat");
double ullat = params.get("ullat");
double width = params.get("w");
double height = params.get("h");
int depth = commuteDepth(ullon, lrlon, width);
boolean querySuccess = true;
//边界条件判断
if (lrlon < ullon || ullat < lrlat || lrlon <= ULLON || ullon >= LRLON || lrlat >= ULLAT || ullat <= LRLAT) {
querySuccess = false;
}
//在这一层寻找对应的图片
//每张图片的宽度和高度(以经度纬度为单位)
double widthPerPic = LONG_WIDTH / Math.pow(2.0, depth);
double heightPerPic = LAT_HEIGHT / Math.pow(2.0, depth);
//x、y方向对应哪几张图片
int xMin = (int) (Math.floor((ullon - ULLON) / widthPerPic)) ;
int xMax = (int) (Math.floor((lrlon - ULLON) / widthPerPic)) ;
int yMin = (int) (Math.floor((ULLAT - ullat) / heightPerPic)) ;
int yMax = (int) (Math.floor((ULLAT - lrlat) / heightPerPic)) ;
// System.out.println("xMin:" + xMin + " xMax" + xMax + " yMin" + yMin + " yMax" + yMax);
//图片的边界经纬度
double xLeftBounding = ULLON + xMin * widthPerPic;
double xRightBounding = ULLON + (xMax + 1) * widthPerPic;
double yUpperBouding = ULLAT - yMin * heightPerPic;
double yLowerBouding = ULLAT - (yMax + 1) * heightPerPic;
//在角落的情况
if (ullon < ULLON) {
xMin = 0;
xLeftBounding = ULLON;
}
if (lrlon > LRLON) {
xMax = (int) Math.pow(2, depth) - 1;
xRightBounding = LRLON;
}
if (ullat > ULLAT) {
yMin = 0;
yUpperBouding = ULLAT;
}
if (lrlat < LRLAT) {
yMax = (int) Math.pow(2, depth) - 1;
yLowerBouding = LRLAT;
}
String[][] render_grid = new String[yMax - yMin + 1][xMax - xMin + 1];
for (int i = yMin; i <= yMax; i++) {
for (int j = xMin; j <= xMax; j++) {
render_grid[i - yMin][j - xMin] = "d" + depth + "_x" + j + "_y" + i + ".png";
// System.out.println("i:" + i + " j:" + j);
// System.out.println(render_grid[i - yMin][j - xMin]);
}
}
results.put("render_grid", render_grid);
results.put("raster_ul_lon", xLeftBounding);
results.put("raster_ul_lat", yUpperBouding);
results.put("raster_lr_lon", xRightBounding);
results.put("raster_lr_lat", yLowerBouding);
results.put("depth", depth);
results.put("query_success", querySuccess);
// System.out.println(results);
return results;
}
private int commuteDepth(double ullon, double lrlon, double width) {
double desiredLonDPP = (lrlon - ullon) / width;
double n = Math.log(LONG_WIDTH / (desiredLonDPP * TILE_SIZE)) / Math.log(2.0);
int depth = (int) Math.ceil(n);
return depth >= 7 ? 7 : depth;
}
}
Routing & Location Data (Part II)
GraphDB
public class GraphDB {
//每个序号对应的点,在调用了clean方法后,就剩下图中所有相连的点,该Map在搜索最短路径时使用
public Map<Long, Node> nodes = new HashMap<>();
//每个点相邻的点
private Map<Long, ArrayList<Long>> adjNode = new HashMap<>();
//一个名字可能对应多个点
private Map<String, ArrayList<Long>> names = new HashMap<>();
private Map<Long, ArrayList<Edge>> adjEdge = new HashMap<>();
//地图中所有的点,不管是否相连。在搜索location时使用
public Map<Long, Node> locations = new HashMap<>();
//Trie,字符串匹配时使用
private Trie<Long> trie = new Trie<>();
public static class Edge {
private Long v;
private Long w;
private double weight;
private String name;
public Edge(Long v, Long w, double weight, String name) {
this.v = v;
this.w = w;
this.weight = weight;
this.name = name;
}
public Long either() {
return v;
}
public Long other(Long vertex) {
return vertex.equals(v) ? w : v;
}
public double getWeight() {
return weight;
}
public String getName() {
return name;
}
}
public static class Node {
public final Long id;
public final double lon;
public final double lat;
public String name = null;
public Node(Long id, double lon, double lat) {
this.id = id;
this.lon = lon;
this.lat = lat;
}
}
//构造函数解析xml文件,将xml文件以图的形式表示出来
public GraphDB(String dbPath) {
try {
//读取xml文件
File inputFile = new File(dbPath);
FileInputStream inputStream = new FileInputStream(inputFile);
// GZIPInputStream stream = new GZIPInputStream(inputStream);
//第二步:创建SAX解析器
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser saxParser = factory.newSAXParser();
//第三步:创建事件处理程序对象
GraphBuildingHandler gbh = new GraphBuildingHandler(this);
//第四步:将XML文件和事件处理程序分配到解析器,parser从上到下遍历xml文件中的每一个element,
// 回调GraphBuildingHandler中的事件处理方法
saxParser.parse(inputStream, gbh);
} catch (ParserConfigurationException | SAXException | IOException e) {
e.printStackTrace();
}
clean();
}
static String cleanString(String s) {
return s.replaceAll("[^a-zA-Z ]", "").toLowerCase();
}
private void clean() {
// TODO: Your code here.
Iterator<Map.Entry<Long, ArrayList<Long>>> it = adjNode.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<Long, ArrayList<Long>> entry = it.next();
if (entry.getValue().isEmpty()) {
//只清理nodes和adjNode
nodes.remove(entry.getKey());
it.remove();
}
}
}
Iterable<Long> vertices() {
//YOUR CODE HERE, this currently returns only an empty list.
return nodes.keySet();
}
Iterable<Long> adjacent(Long v) {
validateVertex(nodes.get(v));
return adjNode.get(v);
}
Iterable<Edge> neighbors(Long v) {
return adjEdge.get(v);
}
double distance(Long v, Long w) {
return distance(lon(v), lat(v), lon(w), lat(w));
}
static double distance(double lonV, double latV, double lonW, double latW) {
double phi1 = Math.toRadians(latV);
double phi2 = Math.toRadians(latW);
double dphi = Math.toRadians(latW - latV);
double dlambda = Math.toRadians(lonW - lonV);
double a = Math.sin(dphi / 2.0) * Math.sin(dphi / 2.0);
a += Math.cos(phi1) * Math.cos(phi2) * Math.sin(dlambda / 2.0) * Math.sin(dlambda / 2.0);
double c = 2 * Math.atan2(Math.sqrt(a), Math.sqrt(1 - a));
return 3963 * c;
}
double bearing(Long v, Long w) {
return bearing(lon(v), lat(v), lon(w), lat(w));
}
static double bearing(double lonV, double latV, double lonW, double latW) {
double phi1 = Math.toRadians(latV);
double phi2 = Math.toRadians(latW);
double lambda1 = Math.toRadians(lonV);
double lambda2 = Math.toRadians(lonW);
double y = Math.sin(lambda2 - lambda1) * Math.cos(phi2);
double x = Math.cos(phi1) * Math.sin(phi2);
x -= Math.sin(phi1) * Math.cos(phi2) * Math.cos(lambda2 - lambda1);
return Math.toDegrees(Math.atan2(y, x));
}
long closest(double lon, double lat) {
double closest = Double.MAX_VALUE;
Long ret = 0l;
for (Long id : vertices()) {
double distance = distance(lon(id), lat(id), lon, lat);
if (distance < closest) {
closest = distance;
ret = id;
}
}
return ret;
}
double lon(Long v) {
validateVertex(nodes.get(v));
return nodes.get(v).lon;
}
double lat(Long v) {
validateVertex(nodes.get(v));
return nodes.get(v).lat;
}
String getName(Long v) {
if (nodes.get(v).name == null) {
throw new IllegalArgumentException();
}
return nodes.get(v).name;
}
void addName(Long id, double lon, double lat, String locationName) {
//将名字统一转换成小写
String cleanedName = cleanString(locationName);
if (!names.containsKey(cleanedName)) {
names.put(cleanedName, new ArrayList<>());
}
//names中存放的是cleanString和id列表,方便我们根据cleanString获取对应的所有点的id
names.get(cleanedName).add(id);
//Node对象中的name属性存放的是真实的locationName,通过names获取id后,再用nodes获取id的真正名字
nodes.get(id).name = locationName;
locations.get(id).name = locationName;
//trie里存放的是cleanString,方便检索
trie.put(cleanedName, id);
}
//获取对应名字的点
ArrayList<Long> getLocations(String name) {
return names.get(cleanString(name));
}
void addNode(Long id, double lon, double lat) {
Node n = new Node(id, lon, lat);
nodes.put(id, n);
adjNode.put(id, new ArrayList<>());
adjEdge.put(id, new ArrayList<>());
locations.put(id, n);
}
void addWay(ArrayList<Long> ways, String wayName) {
for (int i = 1; i < ways.size(); i++) {
addEdge(ways.get(i - 1), ways.get(i), wayName);
}
}
void addEdge(Long v, Long w, String wayName) {
validateVertex(nodes.get(v));
validateVertex(nodes.get(w));
adjNode.get(v).add(w);
adjNode.get(w).add(v);
adjEdge.get(v).add(new Edge(v, w, distance(v, w), wayName));
adjEdge.get(w).add(new Edge(v, w, distance(v, w), wayName));
}
void validateVertex(Node v) {
if (!nodes.containsKey(v.id)) {
throw new IllegalArgumentException("Vertex " + v + "is not in the graph");
}
}
List<String> keysWithPrefixOf(String prefix) {
List<String> result = new ArrayList<>();
//用cleanString从trie中获得的也是以其为前缀的cleanString,我们还需要找到cleanString对应的真实名字
for (String key : trie.keysWithPrefix(cleanString(prefix))) {
for (Long id : names.get(key)) {
result.add(locations.get(id).name);
}
}
System.out.println(result);
return result;
}
}
GraphBuildingHandler
//第一步:创建事件处理程序(编写ContentHandler的实现类,一般继承自DefaultHandler类,采用adapter模式)
public class GraphBuildingHandler extends DefaultHandler {
private static final Set<String> ALLOWED_HIGHWAY_TYPES = new HashSet<>(Arrays.asList
("motorway", "trunk", "primary", "secondary", "tertiary", "unclassified",
"residential", "living_street", "motorway_link", "trunk_link", "primary_link",
"secondary_link", "tertiary_link"));
private String activeState = "";
private final GraphDB g;
private static ArrayList<Long>ways;
private boolean validWay;
public GraphBuildingHandler(GraphDB g) {
this.g = g;
}
private Long id;
private double lon;
private double lat;
private String wayName = "";
private Long wayID;
//parser解析器调用了这个事件处理程序中的该方法,参数是解析器传进来的,对应正在解析的element的属性
//xml文件中先出现所有的点,然后再出现way,通过对之前已经出现的点的引用,将它们连接成路
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes)
throws SAXException {
/* Some example code on how you might begin to parse XML files. */
//有些元素内部会有子元素,这些子元素有时会决定我们对该元素的操作,所以我们需要保持对父元素的追踪,
//activeState就是用来保持对父元素的追踪,在某一个元素的内部,我们可以通过activeState来知道它的父元素是什么
if (qName.equals("node")) {
/* We encountered a new <node...> tag. */
activeState = "node";
id = Long.parseLong(attributes.getValue("id"));
lon = Double.parseDouble(attributes.getValue("lon"));
lat = Double.parseDouble(attributes.getValue("lat"));
g.addNode(id, lon, lat);
} else if (qName.equals("way")) {
/* We encountered a new <way...> tag. */
//遇到way,我们需要继续向下遍历,记录过程中的所有node,遇到tag时才能判断是否是合法的路,
//如果是合法的路,将node两两连接成边,加入Graph中
activeState = "way";
//创建一个List,记录这个way标签中的node
ways = new ArrayList<>();
validWay = false;
wayID = Long.parseLong(attributes.getValue("id"));
} else if (activeState.equals("way") && qName.equals("nd")) {
//在tag中遇到node,加入list
ways.add(Long.parseLong(attributes.getValue("ref")));
} else if (activeState.equals("way") && qName.equals("tag")) {
String k = attributes.getValue("k");
String v = attributes.getValue("v");
if (k.equals("maxspeed")) {
} else if (k.equals("highway")) {
if (ALLOWED_HIGHWAY_TYPES.contains(attributes.getValue("v"))) {
validWay = true;
}
} else if (k.equals("name")) {
wayName = v;
}
} else if (activeState.equals("node") && qName.equals("tag") && attributes.getValue("k")
.equals("name")) {
g.addName(id, lon, lat, attributes.getValue("v"));
}
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
if (qName.equals("way")) {
//如果当前的way元素是合法的话,将way中的所有node连接起来
if (validWay) {
g.addWay(ways, wayName);
wayName = "";
}
}
}
}
Route Search (Part III)
The class receives four values for input: the start point’s longitude and latitude, and the end point’s longitude and latitude.
Your route should be the shortest path that starts from the closest connected node to the start point and ends at the closest connected node to the endpoint. The length of a path is the sum of the distances between the ordered nodes on the path.
A*
Dijkstra’s is a Uniform-Cost search algorithm - you visit all nodes at a distance d or less from the start node. However, in cases like this, where we know the direction that we should be searching in, we can employ that information as a heuristic.
Let n be some node on the search fringe (a min priority queue), s be the start node, and t be the destination node. A* differs from Dijkstra’s in that it uses a heuristic h(n) for each node n that tells us how close it is to t. The priority associated with n should be f(n) = g(n) + h(n), where g(n) is the shortest known path distance from s and h(n) is the heuristic distance, the great-circle distance from n to t, and thus the value of h(n) should shrink as n gets closer to t. This helps prevent Dijkstra’s from exploring too far in the wrong direction.
Router
shortestPath
private static GraphDB.Node start;
private static GraphDB.Node destination;
private static GraphDB graph;
private static class SearchNode implements Comparable<SearchNode> {
public Long id;
public SearchNode parent;
public double distanceToStart;
public double priorit;
public SearchNode(Long id, SearchNode parent,double distanceToStart) {
this.id = id;
this.parent = parent;
this.distanceToStart = distanceToStart;
this.priorit = distanceToStart + distanceToDest(id);
}
@Override
public int compareTo(SearchNode o) {
if (this.priorit < o.priorit) {
return -1;
}
if (this.priorit > o.priorit) {
return 1;
}
return 0;
}
}
private static double distanceToDest(Long id) {
GraphDB.Node v = graph.nodes.get(id);
return GraphDB.distance(v.lon, v.lat, destination.lon, destination.lat);
}
public static List<Long> shortestPath(GraphDB g, double stlon, double stlat,
double destlon, double destlat) {
graph = g;
start = graph.nodes.get(g.closest(stlon, stlat));
destination = graph.nodes.get(g.closest(destlon, destlat));
Map<Long, Boolean> marked = new HashMap<>();
PriorityQueue<SearchNode> pq = new PriorityQueue<>();
pq.offer(new SearchNode(start.id, null, 0));
while (!pq.isEmpty() && !isGoal(pq.peek())) {
SearchNode v = pq.poll();
//标记为经过
marked.put(v.id, true);
for (Long w : g.adjacent(v.id)) {
if (!marked.containsKey(w) || marked.get(w) == false) {
pq.offer(new SearchNode(w, v, v.distanceToStart + distance(g, w, v.id)));
}
}
}
SearchNode pos = pq.peek();
ArrayList<Long> path = new ArrayList<>();
while (pos != null) {
path.add(pos.id);
pos = pos.parent;
}
Collections.reverse(path);
return path; // FIXME
}
private static double distance(GraphDB graph,Long id1, Long id2) {
GraphDB.Node v1 = graph.nodes.get(id1);
GraphDB.Node v2 = graph.nodes.get(id2);
return GraphDB.distance(v1.lon, v1.lat, v2.lon, v2.lat);
}
private static boolean isGoal(SearchNode v) {
return distanceToDest(v.id) == 0;
}
太坑爹了!就因为compareTo方法把结果转成int,我花了一晚上的时间找bug!血泪!!!!!要不是看了最后的commonBug,我一辈子也找不出哪错了!!感谢josh hug!怀疑人生的四个小时。。。。。
Turn-by-turn Navigation
As an example, suppose when calling routeDirections for a given route, the first node you remove is on the way “Shattuck Avenue”. You should create a NavigationDirection where the direction corresponds to “Start”, and as you iterate through the rest of the nodes, keep track of the distance along this way you travel. When you finally get to a node that is not on “Shattuck Avenue”, you should make sure NavigationDirection should have the correct total distance travelled along the previous way to get there (suppose this is 0.5 miles). As a result, the very first NavigationDirection in your returned list should represent the direction “Start on Shattuck Avenue for 0.5 miles.”. From there, your next NavigationDirection should have the name of the way your current node is on, the direction should be calculated via the relative bearing, and you should continue calculating its distance like the first one.
以下为错误做法,记录在此以纪念我逝去的14个小时! 2021.4.22 9:00~23:57
实现这个功能需要知道每个点所在的路的名字,所以需要给节点添加一个wayNames属性。同时由于一个点可能对应多条路,所以应该使用一个集合来装wayNames
对GraphDB中的Node类稍加修改:
public static class Node{
public final long id;
public final double lon;
public final double lat;
public String name = null;
//一个点可以在多条路上,也就可以有多个路名
public Set<way> ways = new HashSet<>();
public Set<String> wayNames = new HashSet<>();
public Node(long id, double lon, double lat) {
this.id = id;
this.lon = lon;
this.lat = lat;
}
}
public static class way{
public final long id;
public final String name;
public way(long id, String name) {
this.id = id;
this.name = name;
}
@Override
public boolean equals(Object obj) {
way w = (way) obj;
return this.id == w.id && this.name == w.name;
}
@Override
public String toString() {
return ";wayID:" + id + " wayName:" + name;
}
}
还需要在GraphDB中新增一个方法,用来给一条路的所有节点绑定路的名字
void addWay(ArrayList<Long> ways,long wayID, String wayName) {
for (int i = 1; i < ways.size(); i++) {
long id1 = ways.get(i - 1);
long id2 = ways.get(i);
addEdge(nodes.get(id1), nodes.get(id2));
nodes.get(id1).ways.add(new way(wayID, wayName));
nodes.get(id1).wayNames.add(wayName);
}
nodes.get(ways.get(ways.size() - 1)).ways.add(new way(wayID, wayName));
nodes.get(ways.get(ways.size() - 1)).wayNames.add(wayName);
}
在GraphBuildingHandler中:
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
if (qName.equals("way")) {
if (validWay) {
g.addWay(ways, wayID, wayName);
wayName = "";
}
}
}
某一条路的路名由起始点和下一个点共同确定。
路的属性有name和id,name有可能相同,id是唯一的。
我们使用name来判断两条路是否是同一个NavigationDirection,即:只要两条路名字相同,就算它们的id不同,我们也认为它们属于同一个NavigationDirection,最后输出时,作为一条语句输出我们使用id来确定路的真正的名字。如果起始点和下一个点的路名集合中有多对相同的路名,其中id相同的一对才是真正的相同的路。
如果某一点的路名集合不包含上一条路的name,说明进入了一条新的路,但是我们无法得知该路的路名是什么,新的路名由起始点和下一个点共同确定。将上一条路的夹角,距离,路名生成NavigationDirection对象,加入List。距离清零,新的夹角由当前点和上一个点计算出来。
如果某一点的路名集合包含上一条路的路名,还是处于原来的路,距离继续累加。
角度计算方法:
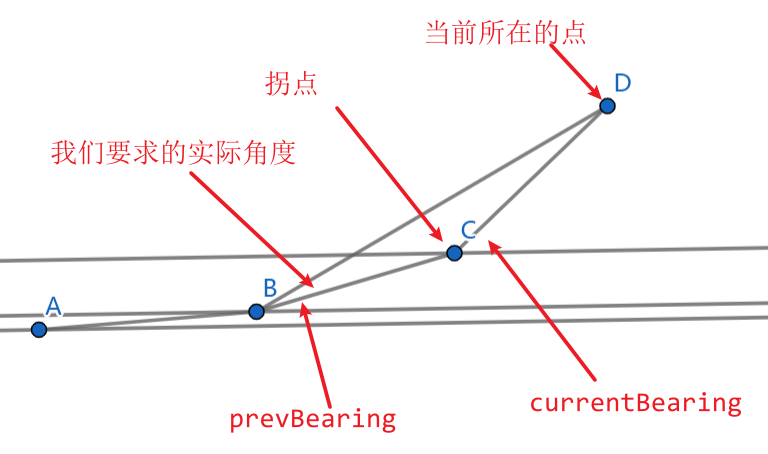
我们需要求的是当前点与之前的道路的夹角,而不是当前点与之前的点的夹角。这个值应该等于currentBearing-prevBearing
routeDirections:
public static List<NavigationDirection> routeDirections(GraphDB g, List<Long> route) {
// graph = g;
ArrayList<NavigationDirection> navigationDirections = new ArrayList<>();
long roadID = 0;
String roadName = "";
//标记起始点的id
long startNode = route.get(0);
int direction = NavigationDirection.START;
double curBearing = g.bearing(route.get(0), route.get(1));
double prevBearing;
double distance = 0;
System.out.println("nodeID:" + route.get(0) + g.nodes.get(route.get(0)).ways.toString());
for (int i = 1; i < route.size(); i++) {
long prevNode = route.get(i - 1);
long curNode = route.get(i);
prevBearing = curBearing;
curBearing = g.bearing(route.get(i - 1), route.get(i));
System.out.println("nodeID:" + route.get(i) + g.nodes.get(route.get(i)).ways.toString());
//每一条路的name由起始点和下一个点共同确定
if (prevNode == startNode) {
roadName = wayName(g, prevNode, curNode);
}
Set<String> currentWayNames = g.nodes.get(route.get(i)).wayNames;
//如果当前点的路名集合包含之前的路名,说明还在同一条路上,需要对距离继续累加。注意!只对名字进行判断
if (currentWayNames.contains(roadName)) {
distance += distance(g, route.get(i - 1), route.get(i));
}
//如果当前点与之前的路名相同,而且不是最后一个数,此时可以直接进行下一次循环,不用继续执行下面的内容
if (currentWayNames.contains(roadName) && i < route.size() - 1) {
continue;
}
/**此时剩下了两种情况:
* 1.当前点与之前的路名相同且是最后一个数
* 2.当前点与之前的路名不相同
*/
//如果当前点与之前的路名相同,但是是最后一个数,那么我们需要将最后一段,也就是当前点所在的一段加入NavigationDirection
//如果当前点与前面的路名不同,则产生了新的路,我们需要将前面的路加入NavigationDirection
NavigationDirection nd = new NavigationDirection(direction, roadName, distance);
navigationDirections.add(nd);
if (currentWayNames.contains(roadName)) {
continue;
}
/**此时剩下了一种情况:
* 1.当前点与之前的路名不相同
*/
//产生新的路
nd = new NavigationDirection();
distance = distance(g, route.get(i - 1), route.get(i));
//将当前的点标记为起始点,与后面的点共同决定这条路的路名
startNode = curNode;
direction = relativeDirection(prevBearing, curBearing);
//如果当前点与前面的路名不同,而且当前点是最后一点,那么我们不仅需要将前面的路加入NavigationDirection,还需要将新产生的这一段路加入NavigationDirection
if (i == route.size() - 1) {
roadName = wayName(g, route.get(i - 1), route.get(i));
navigationDirections.add(new NavigationDirection(direction, roadName, distance));
}
}
return navigationDirections;
}
private static int relativeDirection(double prevBearing, double curBearing) {
double relativeBearing = curBearing - prevBearing;
double absBearing = Math.abs(relativeBearing);
if (absBearing > 180) {
absBearing = 360 - absBearing;
relativeBearing *= -1;
}
if (absBearing <= 15) {
return NavigationDirection.STRAIGHT;
}
if (absBearing <= 30) {
return relativeBearing < 0 ? NavigationDirection.SLIGHT_LEFT : NavigationDirection.SLIGHT_RIGHT;
}
if (absBearing <= 100) {
return relativeBearing < 0 ? NavigationDirection.LEFT : NavigationDirection.RIGHT;
}
else {
return relativeBearing < 0 ? NavigationDirection.SHARP_LEFT : NavigationDirection.SHARP_RIGHT;
}
}
private static String wayName(GraphDB g,long prev,long cur) {
for (GraphDB.way a : g.nodes.get(prev).ways) {
for (GraphDB.way b : g.nodes.get(cur).ways) {
//只有id和name都相同,才是能确定是同一条路
if (a.equals(b)) {
return a.name;
}
}
}
return "";
}
这段垃圾代码耗费了我一整天的时间,面对大量不规则的长达8位的数字和字符debug,一路修修补补,几乎让我崩溃,最后还是有三个测试没有通过。回想起jush hug说过:As a human programmer,you only have so much working memory,you must restrict the complexity of your life!Simple code is usually the best code!我不应该继续就special case对我的程序进行无底洞一样的修补,而是应该丢掉这堆垃圾代码,转换思路,用一个一致性更好,不需要对特殊情况进行大量修补的方法。
正确思路:
GraphDB类:
private Map<Long,ArrayList<Edge>> adjEdge = new HashMap<>();
public static class Edge{
private long v;
private long w;
private double weight;
private String name;
public static class Edge {
private Long v;
private Long w;
private double weight;
private String name;
public Edge(Long v, Long w, double weight, String name) {
this.v = v;
this.w = w;
this.weight = weight;
this.name = name;
}
public Long either() {
return v;
}
public Long other(Long vertex) {
return vertex.equals(v) ? w : v;
}
public double getWeight() {
return weight;
}
public String getName() {
return name;
}
}
Iterable<Edge> neighbors(long v) {
return adjEdge.get(v);
}
void addName(Long id, double lon, double lat, String locationName) {
//将名字统一转换成小写
String cleanedName = cleanString(locationName);
if (!names.containsKey(cleanedName)) {
names.put(cleanedName, new ArrayList<>());
}
//names中存放的是cleanString和id列表,方便我们根据cleanString获取对应的所有点的id
names.get(cleanedName).add(id);
//Node对象中的name属性存放的是真实的locationName,通过names获取id后,再用nodes获取id的真正名字
nodes.get(id).name = locationName;
locations.get(id).name = locationName;
//trie里存放的是cleanString,方便检索
trie.put(cleanedName, id);
}
void addNode(Long id, double lon, double lat) {
Node n = new Node(id, lon, lat);
nodes.put(id, n);
adjNode.put(id, new ArrayList<>());
adjEdge.put(id, new ArrayList<>());
locations.put(id, n);
}
void addWay(ArrayList<Long> ways, String wayName) {
for (int i = 1; i < ways.size(); i++) {
addEdge(ways.get(i - 1), ways.get(i), wayName);
}
}
void addEdge(Long v, Long w, String wayName) {
validateVertex(nodes.get(v));
validateVertex(nodes.get(w));
adjNode.get(v).add(w);
adjNode.get(w).add(v);
adjEdge.get(v).add(new Edge(v, w, distance(v, w), wayName));
adjEdge.get(w).add(new Edge(v, w, distance(v, w), wayName));
}
void validateVertex(Node v) {
if (!nodes.containsKey(v.id)) {
throw new IllegalArgumentException("Vertex " + v + "is not in the graph");
}
}
GraphBuildingHandler
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
if (qName.equals("way")) {
//如果当前的way元素是合法的话,将way中的所有node连接起来
if (validWay) {
g.addWay(ways, wayName);
wayName = "";
}
}
}
Router
public static List<NavigationDirection> routeDirections(GraphDB g, List<Long> route) {
double distance = 0;
int relativeDirection = NavigationDirection.START;
ArrayList<NavigationDirection> navigationList = new ArrayList<>();
//将输入的点转化为连接点的边,如果边的名字相同,则说明在同一条路上,否则就不在同一条路上
ArrayList<GraphDB.Edge> ways = getWays(g, route);
if (ways.size() == 1) {
navigationList.add(new NavigationDirection(NavigationDirection.START, ways.get(0).getName(), ways.get(0).getWeight()));
return navigationList;
}
for (int i = 1; i < ways.size(); i++) {
GraphDB.Edge preEdge = ways.get(i - 1);
GraphDB.Edge nextEdge = ways.get(i);
Long prevVertex = route.get(i - 1);
Long curVertex = route.get(i);
Long nextVertex = route.get(i + 1);
String preWayName = preEdge.getName();
String nextWayName = nextEdge.getName();
distance += preEdge.getWeight();
//如果前后两条路的名字不一样,则说明切换了路线,更新NavigationList,清零distance
if (!preWayName.equals(nextWayName)) {
double preBearing = g.bearing(prevVertex, curVertex);
double nextBearing = g.bearing(curVertex, nextVertex);
navigationList.add(new NavigationDirection(relativeDirection, preWayName, distance));
relativeDirection = relativeDirection(preBearing, nextBearing);
distance = 0;
}
if (i == ways.size() - 1) {
distance += nextEdge.getWeight();
navigationList.add(new NavigationDirection(relativeDirection, nextWayName, distance));
}
}
return navigationList;
}
private static ArrayList<GraphDB.Edge> getWays(GraphDB g, List<Long> route) {
ArrayList<GraphDB.Edge> ways = new ArrayList<>();
for (int i = 1; i < route.size(); i++) {
Long curVertex = route.get(i - 1);
Long nextVertex = route.get(i);
for (GraphDB.Edge e : g.neighbors(curVertex)) {
if (e.other(curVertex).equals(nextVertex)) {
ways.add(e);
}
}
}
return ways;
}
private static int relativeDirection(double prevBearing, double curBearing) {
double relativeBearing = curBearing - prevBearing;
double absBearing = Math.abs(relativeBearing);
if (absBearing > 180) {
absBearing = 360 - absBearing;
relativeBearing *= -1;
}
if (absBearing <= 15) {
return NavigationDirection.STRAIGHT;
}
if (absBearing <= 30) {
return relativeBearing < 0 ? NavigationDirection.SLIGHT_LEFT : NavigationDirection.SLIGHT_RIGHT;
}
if (absBearing <= 100) {
return relativeBearing < 0 ? NavigationDirection.LEFT : NavigationDirection.RIGHT;
}
else {
return relativeBearing < 0 ? NavigationDirection.SHARP_LEFT : NavigationDirection.SHARP_RIGHT;
}
}
我花了十几个小时都无法修复的bug,换了一个做法,从头再来仅仅需要不到2个小时就可以完成并且通过测试。好的代码往往是简单的代码,当我们在实现一个算法,陷入了无止境的修复特殊情况的困境时,往往更好的做法是:丢弃所有的代码,从头开始,思考另一个更加简单、干净的解法。
autocomplete
GraphDB类中相关方法:
//每个序号对应的点,在调用了clean方法后,就剩下图中所有相连的点,该Map在搜索最短路径时使用
public Map<Long, Node> nodes = new HashMap<>();
//一个名字可能对应多个点
private Map<String, ArrayList<Long>> names = new HashMap<>();
//地图中所有的点,不管是否相连。在搜索location时使用
public Map<Long, Node> locations = new HashMap<>();
//Trie,字符串匹配时使用
private Trie<Long> trie = new Trie<>();
public static class Node {
public final Long id;
public final double lon;
public final double lat;
public String name = null;
public Node(Long id, double lon, double lat) {
this.id = id;
this.lon = lon;
this.lat = lat;
}
}
static String cleanString(String s) {
return s.replaceAll("[^a-zA-Z ]", "").toLowerCase();
}
void addName(Long id, double lon, double lat, String locationName) {
//将名字统一转换成小写
String cleanedName = cleanString(locationName);
if (!names.containsKey(cleanedName)) {
names.put(cleanedName, new ArrayList<>());
}
//names中存放的是cleanString和id列表,方便我们根据cleanString获取对应的所有点的id
names.get(cleanedName).add(id);
//Node对象中的name属性存放的是真实的locationName,通过names获取id后,再用nodes获取id的真正名字
nodes.get(id).name = locationName;
locations.get(id).name = locationName;
//trie里存放的是cleanString,方便检索
trie.put(cleanedName, id);
}
//获取对应名字的点
ArrayList<Long> getLocations(String name) {
return names.get(cleanString(name));
}
void addNode(Long id, double lon, double lat) {
Node n = new Node(id, lon, lat);
nodes.put(id, n);
adjNode.put(id, new ArrayList<>());
adjEdge.put(id, new ArrayList<>());
locations.put(id, n);
}
List<String> keysWithPrefixOf(String prefix) {
List<String> result = new ArrayList<>();
//用cleanString从trie中获得的也是以其为前缀的cleanString,我们还需要找到cleanString对应的真实名字
for (String key : trie.keysWithPrefix(cleanString(prefix))) {
for (Long id : names.get(key)) {
result.add(locations.get(id).name);
}
}
System.out.println(result);
return result;
}
Trie
public class Trie<Value> {
private static int R = 256;
private Node root;
private static class Node {
private Object val;
private Map<Character, Node> next = new HashMap<>();
}
public Value get(String key) {
Node x = get(key, root, 0);
if (x==null) return null;
return (Value) x.val;
}
private Node get(String key, Node x,int index) {
if (x == null) return null;
//index是字符串中下一个要比较的下标,也就是说,当前要比较的下标就是字符串的末尾
//此时字符串除了最后一个字符,其他的都已经比较完了
//现在,这个字符存在两种状态:是或不是
//如果是,就返回该字符对应的值,如果不是,就返回null,所以不需要进行判断
if (index == key.length()) {
return x;
}
return get(key, x.next.get(key.charAt(index)), index + 1);
}
public void put(String key, Value value) {
root = put(key, value, root, 0);
}
//put先查找,如果沿途中的字符与key中的字符一一对应,那么把value赋值给最后一个节点
//如果在查找时遇到了空节点,那么将key中剩下的字符继续接下去,然后再将value赋值给最后一个节点
private Node put(String key, Value value, Node x, int index) {
if (x==null) x = new Node();
if (index == key.length()) {
x.val = value;
return x;
}
char c=key.charAt(index);
x.next.put(c, put(key, value, x.next.get(c), index + 1));
return x;
}
public Iterable<String> keys() {
return keysWithPrefix("");
}
public Iterable<String> keysWithPrefix(String s) {
Queue<String> queue = new LinkedList<>();
collect(get(s, root, 0), s, queue);
return queue;
}
private void collect(Node x, String pre, Queue<String> queue) {
if (x == null) return;
if (x.val != null) queue.offer(pre);
for (Map.Entry<Character, Node> entry : x.next.entrySet()) {
collect(entry.getValue(), pre + entry.getKey(), queue);
}
}
public String longestPrefixOf(String s) {
int length = search(root, s, 0, 0);
return s.substring(0, length);
}
private int search(Node x, String s, int index, int length) {
if (x == null ) return length;
if (x.val != null) length = index;
if (index == s.length()) return length;
return search(x.next.get(s.charAt(index)), s, index + 1, length);
}
public void delete(String key) {
root = delete(root, key, 0);
}
private Node delete(Node x, String key, int index) {
if (x==null) return null;
//index实际上是下一次的下标,也就是字符串到了最后一个字符,查找到了所在位置,将值置为空
if (index == key.length()) {
x.val = null;
}
//如果字符串还没有匹配完,继续对下一个字符进行匹配
else{
//index指向下一次要匹配的字符下标
char c = key.charAt(index);
//将链接重置
x.next.put(c, delete(x.next.get(c), key, index + 1));
}
//匹配完成,将当前节点的值置为null之后,对多余的节点进行删除
//要求:树的叶结点的val必须存在
//如果本身的val非空,则不需要再删除,直接返回自己
if (x.val != null)
return x;
//如果本身的val为空,那么是否需要删除则取决于是不是叶结点
//也就是说,如果该节点有非空链接,就可以不用删除
//如果该节点全部都是空链接,就需要删除
if (!x.next.isEmpty()) return x;
return null;
}
}
MapServer:
//该方法负责获取指定前缀的字符串名字,而由对应的字符串名字获取实际的点,由getLocations负责
public static List<String> getLocationsByPrefix(String prefix) {
return graph.keysWithPrefixOf(prefix);
}
public static List<Map<String, Object>> getLocations(String locationName) {
ArrayList<Long> nodes = graph.getLocations(locationName);
//通常以Map<String,Object>的形式存储键值对,同一个名字对应的点不唯一,所以使用List来存储所有与该名字对应的点
List<Map<String, Object>> result = new LinkedList<>();
for (Long i : nodes) {
Map<String, Object> nodeInfo = new HashMap<>();
GraphDB.Node node = graph.locations.get(i);
nodeInfo.put("lat", node.lat);
nodeInfo.put("lon", node.lon);
nodeInfo.put("name", node.name);
nodeInfo.put("id", node.id);
result.add(nodeInfo);
}
return result;
}
KDtree和索引优先队列
我看了看2019的这个project,发现它还需要实现KDtree来优化closeset,实现索引优先队列来优化A*。所以我在2018的基础上做了一些扩展,完成了这两项优化。
KDtree:
public class KDTree implements PointSet{
private static final boolean diviedByX = false;
private static final boolean diviedByY = true;
private class Node implements Comparable<Node> {
private Node left;
private Node right;
private point p;
private boolean orientation;
public double bestDistanceToGoal = Double.MAX_VALUE;
public Node(point p, boolean orientation) {
this.p = p;
this.orientation = orientation;
}
@Override
public int compareTo(Node o) {
if (this.orientation == diviedByX) {
return Double.compare(this.p.getX(), o.p.getX());
} else {
return Double.compare(this.p.getY(), o.p.getY());
}
}
}
private Node root;
public KDTree(List<point> points) {
for (point p : points) {
insert(p);
}
}
public KDTree(){
}
public void insert(point p) {
root = insert(root, p, diviedByX);
}
private Node insert(Node x, point p, boolean orientation) {
if (x == null) return new Node(p, orientation);
int cmp = x.compareTo(new Node(p, orientation));
if (cmp < 0) x.left = insert(x.left, p, !orientation);
else x.right = insert(x.right, p, !orientation);
if (x.p.equals(p)) x.p = p;
return x;
}
public point nearest(double x, double y) {
return nearest(root, root, new point(null, x, y), diviedByX).p;
}
private Node nearest(Node x, Node best, point goal, boolean orientation) {
if (x == null) return best;
if (Double.compare(x.p.distanceTo(goal), best.bestDistanceToGoal) < 0) {
best = x;
best.bestDistanceToGoal = x.p.distanceTo(goal);
}
int cmp = x.compareTo(new Node(goal, orientation));
Node goodSide = cmp < 0 ? x.left : x.right;
Node badSide = cmp < 0 ? x.right : x.left;
best = nearest(goodSide, best, goal, !orientation);
if (isWorthLook(x, goal, best.bestDistanceToGoal, orientation))
best = nearest(badSide, best, goal, !orientation);
return best;
}
private boolean isWorthLook(Node curNode, point goal, double bestDistance, boolean orientation) {
if (orientation == diviedByX)
return goal.getX() - curNode.p.getX() < bestDistance;
else
return goal.getY() - curNode.p.getY() < bestDistance;
}
}
KDtree中用到的point类
public class point {
public final Long id;
public final double lon;
public final double lat;
public String name = null;
public point(Long id, double lon, double lat) {
this.id = id;
this.lon = lon;
this.lat = lat;
}
public point(double lon, double lat) {
this.id = null;
this.lon = lon;
this.lat = lat;
}
public double getX() {
return lon;
}
public double getY() {
return lat;
}
public double distanceTo(point p) {
return GraphDB.distance(this.lon, this.lat, p.lon, p.lat);
}
@Override
public boolean equals(Object obj) {
if (obj == null) return false;
if (obj.getClass() != this.getClass()) return false;
point p = (point) obj;
return this.getX() == p.getX() && this.getY() == p.getY();
}
}
ArrayHeapMinPQ:
public class ArrayHeapMinPQ<T> {
private class priorityNode implements Comparable{
T item;
double priority;
//priorityNode包含了储存的item和item对应的优先级,只有这样,我们才能修改对应item的优先级
//普通的优先队列,优先级是隐含的,包含在元素之内,通过元素与元素之间的比较才能确定优先级
//索引优先队列,优先级在元素之外,可以改变特定元素的优先级
public priorityNode(T item, double priority) {
this.item = item;
this.priority = priority;
}
@Override
public int compareTo(Object o) {
if (o == null) return -1;
if (o.getClass() != this.getClass()) return -1;
return Double.compare(this.priority, ((priorityNode) o).priority);
}
}
private List<priorityNode> pq = new ArrayList<>();
private Map<T, Integer> itemToIndex = new HashMap<>();
public ArrayHeapMinPQ() {
pq.add(null);
}
/* Inserts an item with the given priority value. */
void add(T item, double priority){
pq.add(new priorityNode(item, priority));
itemToIndex.put(item, pq.size() - 1);
swim(pq.size() - 1);
}
public boolean isEmpty(){
return size() == 0;
}
private void exch(int i, int j) {
priorityNode t = pq.get(i);
itemToIndex.put(pq.get(i).item, j);
itemToIndex.put(pq.get(j).item, i);
pq.set(i, pq.get(j));
pq.set(j, t);
}
private boolean less(int i, int j) {
return pq.get(i).compareTo(pq.get(j)) < 0;
}
private void swim(int k) {
if (k / 2 >= 1 && less(k, k / 2)) {
exch(k / 2, k);
swim(k / 2);
}
}
private void sink(int index) {
int j = 2 * index;
if (j > pq.size()-1) return;
if (j + 1 <= pq.size()-1 && less(j + 1, j)) j++;
if (less(index, j)) return;
exch(index, j);
sink(j);
}
/* Returns true if the PQ contains the given item. */
boolean contains(T item){
return itemToIndex.containsKey(item);
}
/* Returns the minimum item. */
T getSmallest(){
return pq.get(1).item;
}
/* Removes and returns the minimum item. */
T removeSmallest(){
T t = pq.get(1).item;
exch(1, pq.size() - 1);
itemToIndex.remove(pq.get(pq.size() - 1).item);
pq.remove(pq.size() - 1);
sink(1);
return t;
}
/* Changes the priority of the given item. Behavior undefined if the item doesn't exist. */
/**
* 改变对应item的priority,如果不包含这个item,就将它添加进优先队列
* @param item
* @param priority
*/
void changePriority(T item, double priority){
int index = itemToIndex.get(item);
double curPriority = pq.get(index).priority;
pq.get(index).priority = priority;
if (priority > curPriority) sink(index);
else swim(index);
}
/* Returns the number of items in the PQ. */
int size(){
return pq.size() - 1;
}
}
就是优化结果并不是很明显,使用了KDtree的closeset只比暴力快了几倍,我也找不出是什么原因。。。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









