







NCE Loss(Noise Contrastive Estimation Loss)和 InfoNCE Loss 是两种常用的损失函数,主要应用在对比学习和自监督学习任务中。它们的区别在于应用场景和具体实现细节。下面是对两者的详细比较:
1. NCE Loss(Noise Contrastive Estimation Loss)
-
目的:NCE 是一种将密度估计问题转换为二分类问题的方法,常用于近似难以计算的概率分布,比如训练 word2vec 等模型。
-
原理:在传统密度估计中,目标是最大化真实样本的概率分布。但计算这些概率往往非常复杂。NCE 引入了噪声分布,通过将区分真实样本和噪声样本的任务看作一个二分类问题,进而使得密度估计问题变得可行。
-
公式:

其中,
p(x)是目标分布,p_n(x)是噪声分布,k是噪声样本与真实样本的比例。 -
应用:NCE 最常用于 word2vec、语言模型等对比正样本和负样本的任务中。
2. InfoNCE Loss
-
目的:InfoNCE 是对比学习中常用的损失函数,旨在最大化正样本对之间的相似度,同时最小化正样本与负样本之间的相似度。它广泛应用于对比学习任务,如 SimCLR、MoCo 等。
-
原理:InfoNCE 通过最大化目标样本与正样本的对比得分,并最小化目标样本与负样本的对比得分,从而学习到有意义的表示。
-
公式:
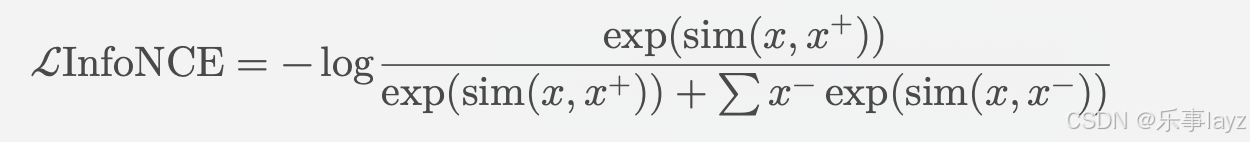
其中,
x是目标样本,x^+是与目标样本相匹配的正样本,x^-是负样本,sim(·)是相似性度量函数(通常为余弦相似度)。 -
应用:InfoNCE 主要用于自监督学习中,如图像、文本等领域的对比学习,通过构造正负样本对来学习潜在的表示。
主要区别
-
目标:
- NCE Loss 是一种用于估计概率分布的替代方法。
- InfoNCE Loss 专注于对比学习中的正负样本对比,应用于表示学习。
-
损失计算:
- NCE Loss 偏向于估计数据分布,并将问题转化为二分类问题。
- InfoNCE Loss 通过对比相似度来进行优化,目标是最大化相似样本对之间的相似性,最小化不相似样本对之间的相似性。
两者在细节和应用场景上有所不同,InfoNCE 更专注于表示学习和自监督学习,而 NCE 更偏向于概率分布估计任务。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









