







CAM : 通道注意力
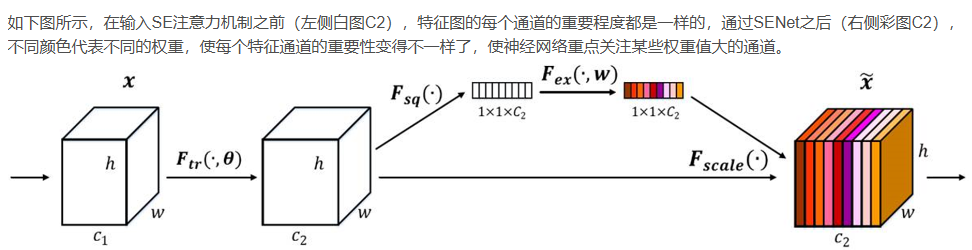
通道注意力:目标是让网络能够自适应地为每个通道分配权重,突出重要通道,抑制不太重要的通道。
通过自动学习的方式,使用另外一个新的神经网络,获取到特征图的每个通道的重要程度,然后用这个重要程度去给每个特征赋予一个权重值,从而让神经网络重点关注某些特征通道。提升对当前任务有用的特征图的通道,并抑制对当前任务用处不大的特征通道。
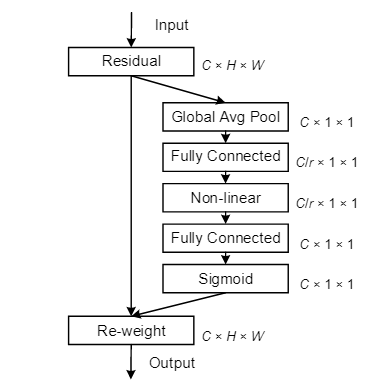
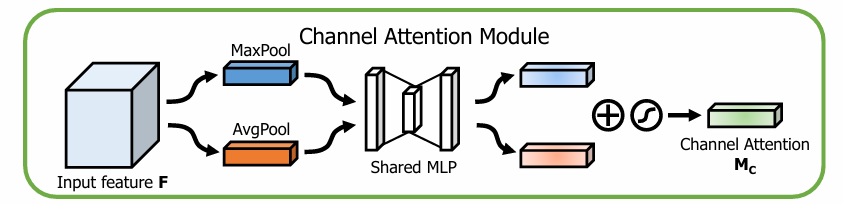
上图为通道注意力机制的逻辑图
下图为通道注意力机制的代表模型 SENet (Squeeze-and-Excitation Networks)
import torch
import torch.nn as nn
class ChannelAttention(nn.Module):
def __init__(self, in_channels, reduction=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 全局平均池化
self.max_pool = nn.AdaptiveMaxPool2d(1) # 全局最大池化
### nn.AdaptiveAvgPool2d(n) 是全局平均池化,参数n指输出的特征图为n*n
# 全连接层减少通道数,再恢复
self.fc = nn.Sequential(
nn.Conv2d(in_channels, in_channels // reduction, 1, bias=False),
nn.ReLU(),
nn.Conv2d(in_channels // reduction, in_channels, 1, bias=False),
)
self.sigmoid = nn.Sigmoid() # Sigmoid激活函数,将输入的每个值都被压缩到 0 到 1
#比如输入是;input_tensor = torch.randn(1, 64, 32, 32),输出依然是这个形状,只是将每个值都经过函数压缩到 0 到 1
def forward(self, x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
# 将两种池化的结果相加并通过Sigmoid激活
out = self.sigmoid(avg_out + max_out) ###这个是逐个元素相加,不是concat
return x * out
###假如输入的张量x是input_tensor = torch.randn(1, 64, 32, 32)
###那么out.shape:(1, 64, 1, 1)
###通过广播机制将out扩展为 (1, 64, 32, 32),以便与 x 进行逐元素相乘。其中out的单个通道内的值都相同
###out实际就是原特征图x每个通道的权重,由注意力机制计算得出
###return x * out 实际上是对输入特征图 x 的每个通道进行加权,通道的权重是通过注意力机制计算得到的。
###这样可以增强重要特征,同时抑制不重要的特征。
# 测试
if __name__ == "__main__":
input_tensor = torch.randn(1, 64, 32, 32) # 输入形状为 (batch_size, in_channels, height, width)
model = ChannelAttention(in_channels=64)
output = model(input_tensor)
print(output.shape) # 输出形状应与输入形状相同
通道注意力模块:ChannelAttention类用于计算输入特征图的通道注意力。它首先通过全局平均池化和全局最大池化生成通道特征描述。然后通过两个全连接层对特征进行非线性变换,再通过Sigmoid生成每个通道的权重。
前向传播:在forward函数中,首先将输入特征图分别通过全局平均池化和全局最大池化,然后使用全连接层计算每个通道的权重,最后将权重与原输入特征图按通道逐元素相乘。
传统的卷积操作对每个通道一视同仁,但实际上,不同通道在不同的任务中可能具有不同的重要性。通道注意力机制的目标是让网络能够自适应地为每个通道分配权重,突出重要通道,抑制不太重要的通道。
空间注意力
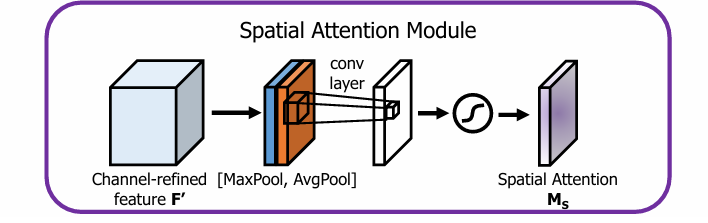
空间注意力的思路流程是:
-
首先,对一个尺寸为 $ H \times W \times C$ 的输入特征图F进行通道维度的全局最大池化和全局平均池化,得到两个$ H \times W \times 1$ 的特征图;(在通道维度进行池化,压缩通道大小,便于后面学习空间的特征)
-
然后,将全局最大池化和全局平均池化的结果,按照通道拼接 (concat),得到特征图尺寸为$ H \times W \times 2$ ,
-
最后,对拼接的结果进行 7 × 7 7\times 7 7×7 的卷积操作,得到特征图尺寸为 $ H \times W \times 1$ ,接着通过Sigmoid激活函数 ,得到空间注意力权重矩阵 ( 7 × 7 7\times 7 7×7 的卷积核,padding = 3 ,保证输出的 $H \times W $ 不变)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
#7x7的卷积核,padding = 3 ,保证输出的 HxW不变
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
CBAM: 通道空间混合
CBAM (Convolutional Block Attention Module )包含空间注意力和通道注意力两部分:
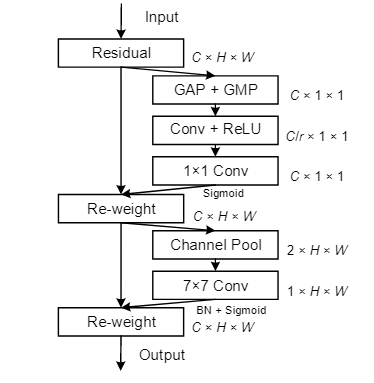
“GAP” and “GMP” refer to the global average pooling and global max pooling, respectively
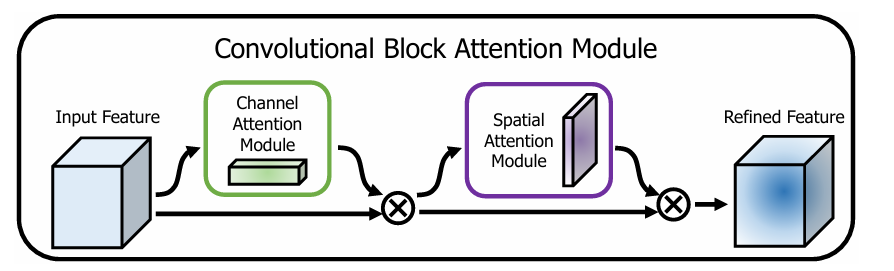
通道注意力和空间注意力这两个模块可以以并行或者顺序的方式组合在一起,但是作者发现顺序组合并且将通道注意力放在前面可以取得更好的效果。
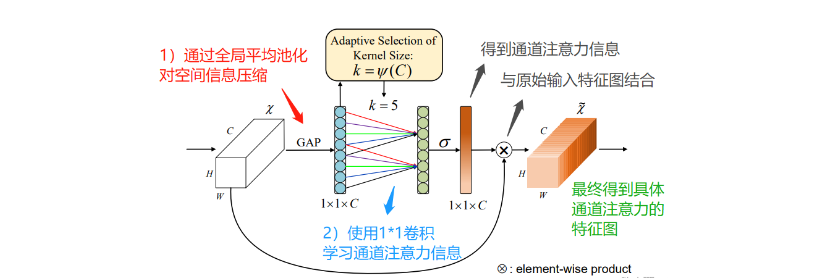
ECA : 高效通道注意力
背景:ECA-Net认为:SENet 中采用的降维操作会对通道注意力的预测产生负面影响;同时获取所有通道的依赖关系是低效的,而且不必要的;
设计:ECA在SE模块的基础上,把SE中使用全连接层FC学习通道注意信息,**改为1*1卷积(这里是Conv1d,不是Conv2d)**学习通道注意信息;
作用:使用 1 × 1 1\times1 1×1 卷积捕获不同通道之间的信息,避免在学习通道注意力信息时,通道维度减缩;同时能够降低参数量;(FC具有较大参数量;1*1卷积只有较小的参数量)
import torch
import torch.nn as nn
import torch.nn.functional as F
class ECALayer(nn.Module):
def __init__(self, channel, k_size=3):
"""
初始化ECA模块
:param channel: 输入特征图的通道数
:param k_size: 卷积核大小,自适应通道依赖
"""
super(ECALayer, self).__init__()
# 1D卷积,padding保证输入输出维度一致
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 全局平均池化
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size-1)//2, bias=False) # 1D卷积
def forward(self, x):
# 获取输入的维度
B, C, H, W = x.size()
# 全局平均池化: [B, C, H, W] -> [B, C, 1, 1]
y = self.avg_pool(x)
# 将特征重塑为适合1D卷积的格式: [B, C, 1, 1] -> [B, 1, C]
y = y.view(B, C) #因为 y 形状为:[B, C, 1, 1],最后连个维度都是 1 ,所以可以通过 view 把它reshape 成形状 (B, C)
y = y.unsqueeze(1) #在批次和通道之间插入了一个新维度,使它符合1D卷积的输入需求
# 使用1D卷积来捕捉通道间的依赖关系: [B, 1, C] -> [B, 1, C]
y = self.conv(y)
# Sigmoid激活得到权重: [B, 1, C] -> [B, C, 1, 1]
y = torch.sigmoid(y).view(b, c, 1, 1)
# 对输入特征图进行加权: [B, C, H, W] * [B, C, 1, 1]
return x * y.expand_as(x)
# 示例用法
input_tensor = torch.randn(8, 64, 32, 32) # 假设输入为 [B=8, C=64, H=32, W=32]
eca_layer = ECALayer(channel=64) # 创建ECA模块,输入通道数为64
output_tensor = eca_layer(input_tensor) # 前向传播
print(output_tensor.shape) # 输出的形状与输入一致 [8, 64, 32, 32]
ECA 相比 SENet有什么提升?
ECA 的设计简化了SENet的复杂结构。ECA通过1D卷积代替全连接层,以此建模通道之间的关系。这种方式不仅有效减少了模型的参数量,而且保持了通道间的依赖关系。ECA通过动态调整卷积核的大小来适应不同的通道数量,避免了全连接层中额外的降维和扩展操作。
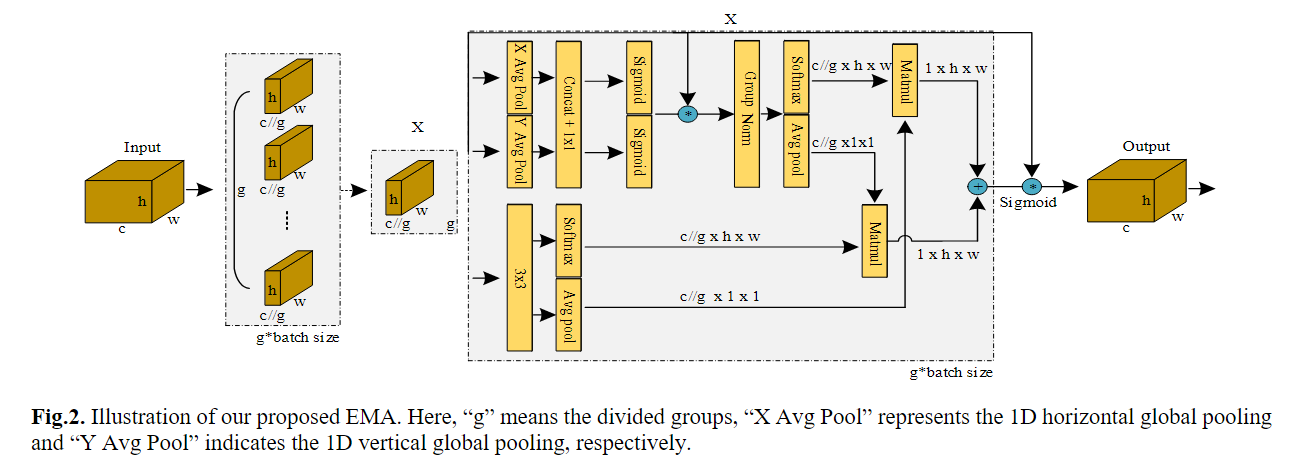
EMA:高效多尺度注意力模块
EMA-attention-module/EMA_attention_module at main · YOLOonMe/EMA-attention-module (github.com)
import torch
import torch.nn as nn
import torch.nn.functional as F
class EMA(nn.Module):
def __init__(self, channels, num_scales=3):
"""
初始化EMA模块
:param channels: 输入特征图的通道数
:param num_scales: 使用的多尺度数量
"""
super(EMA, self).__init__()
# 创建不同尺度的卷积核
self.convs = nn.ModuleList([
nn.Conv2d(channels, channels, kernel_size=3, padding=1, dilation=scale, bias=False)
for scale in range(1, num_scales+1)
])
# 用于融合不同尺度的特征
self.fusion_conv = nn.Conv2d(channels * num_scales, channels, kernel_size=1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 保存每个尺度的卷积输出
multi_scale_features = []
# 多尺度卷积
for conv in self.convs:
multi_scale_features.append(conv(x))
# 将不同尺度的特征拼接在一起
fused_features = torch.cat(multi_scale_features, dim=1)
# 通过1x1卷积进行特征融合
out = self.fusion_conv(fused_features)
# 使用sigmoid生成注意力权重
attention_weights = self.sigmoid(out)
# 对原始输入进行加权
out = x * attention_weights
return out
# 示例用法
input_tensor = torch.randn(8, 64, 32, 32) # 假设输入为 [B=8, C=64, H=32, W=32]
ema_layer = EMA(channels=64, num_scales=3) # 创建EMA模块
output_tensor = ema_layer(input_tensor) # 前向传播
print(output_tensor.shape) # 输出的形状与输入一致 [8, 64, 32, 32]
Coordinate Attention: CA 坐标注意力
注意力机制——Coordinate Attention-CSDN博客
Coordinate Attention 是一种改进的注意力机制,旨在在捕捉通道信息的同时增强特征图的空间坐标信息。传统的注意力机制,如SE(Squeeze-and-Excitation)模块或 ECA(Efficient Channel Attention),主要侧重于通道间的注意力,但缺乏对空间信息的感知。而 Coordinate Attention 通过引入空间坐标信息来增强注意力机制,使其不仅能够关注通道间的依赖关系,还能有效捕捉特征图的空间信息。
-
SENet 只考虑内部通道信息而忽略了位置信息的重要性,而视觉中目标的空间结构是很重要的。
-
BAM和CBAM尝试去通过在通道上进行全局池化来引入位置信息,但这种方式只能捕获局部的信息,而无法获取长范围依赖的信息(过几层的卷积后feature maps的每个位置都包含了原图像一个局部区域的信息,CBAM是通过对每个位置的多个通道取最大值和平均值来作为加权系数,因此这种加权只考虑了局部范围的信息)
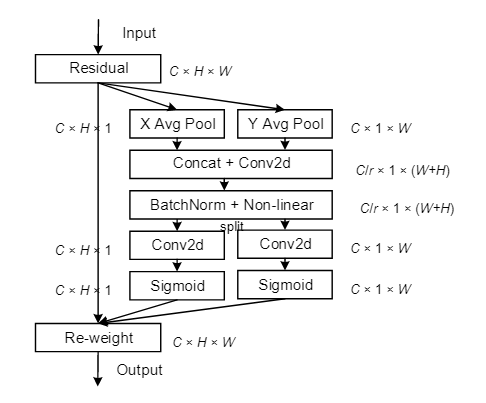
这里的“GAP”和“GMP”分别指全局平均池和全局最大池。“X平均池”和“Y平均池”分别指一维水平全局池和一维垂直全局池。
下面这个代码最大的问题在于输入输出通道不相等时会出错,因为最后的输出结果了直接那最开始的输入张量乘计算过后的权重,但是这个权重在通道维度是指定的oup,所以要特殊处理,解决方法有两种:
1.设置 inp = oup
2.多加一层 1*1 卷积,nn.Conv2d(oup, inp, kernel_size=1, stride=1, padding=0)
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
"""
模拟 Sigmoid 函数,限制了输出值的范围在 [0, 1] 之间,同时计算代价较低
"""
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
# ReLU6 在ReLU的基础上抑制最大值为6, min(6,max(0,x)),即它将输入的值限制在 [0, 6] 的范围内
#如果你设置 inplace=True,输入张量 x 会直接被修改,而不是创建新的张量 y。这在内存使用和性能优化方面可能会有帮助
def forward(self, x):
return self.relu(x + 3) / 6
# 这里使用 self.relu(x + 3) / 6 而不是 self.relu(x) / 6 是因为:
# 为了模拟 Sigmoid 函数,当x= 0 时 Sigmoid输出为 0.5,所以 为了让h_sigmoid在 x=0时也输出0.5
"""
h_swish 在 MobileNetV3 中广泛使用,能提升模型效率。
"""
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1)) # (H, 1)
self.pool_w = nn.AdaptiveAvgPool2d((1, None)) # (1, W)
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0) # 通道减少,特征尺寸不变
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x) #(N, C, H, 1)
x_w = self.pool_w(x).permute(0, 1, 3, 2) #(N, C, W, 1)
#将 x_h 和 x_w 拼接为 [B, C, H+W, 1],通过1x1卷积 conv1 压缩通道和激活函数 h_swish 。
y = torch.cat([x_h, x_w], dim=2) #(N, C, H + W, 1)
y = self.conv1(y) #(N, mip, H + W, 1)
y = self.bn1(y)
y = self.act(y) #(N, mip, H + W, 1)
# torch.split用于将张量按照指定的大小分割成多个子张量。它允许你将一个张量沿指定维度拆分为若干部分。
# 注意:这里的 x_h, x_w 与上面的不同,这里的是通过1x1卷积 conv1 压缩通道和激活函数的,值都改变了
x_h, x_w = torch.split(y, [h, w], dim=2) #(N, mip, H, 1) , (N, mip, W, 1)
x_w = x_w.permute(0, 1, 3, 2)
# 生成高度和宽度方向的注意力权重
a_h = self.conv_h(x_h).sigmoid() #(N, oup, H, 1)
a_w = self.conv_w(x_w).sigmoid() #(N, oup, 1, W)
# 这个乘法是有问题的,在通道维度上不匹配乘不了
out = identity * a_w * a_h
# out = a_h.expand_as(x) * a_w.expand_as(x) * identity
return out















 1779
1779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









