







此文主要是按照上一篇的介绍能够定制爬虫项目中间件,scrapy框架里面的代码和基本和上一篇的相同,这里进行一一介绍。
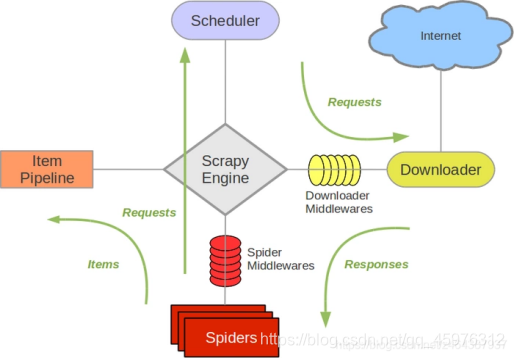
这是scrapy框架的流程图(scrapy原理,安装方法都在上一篇)
接下来我们进行中间件的定制。
(这是打开后的样子,里已经有了scrapy框架的各种组件,只要我动手写代码就可以进行爬虫)
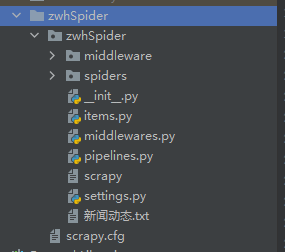
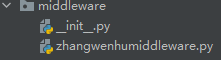
(这是按照我们的要求的自定义中间件文件面里面有中间件的python文件,暂时还没有代码)
为了便与学习,我们仍然采用上一篇的实战网站。(https://www.tipdm.org)
(1)编写爬虫文件 pachong.spider python文件
import scrapy
from zwhSpider.items import ZwhspiderItem
import scrapy
from zwhSpider.items import ZwhspiderItem
class PachongSpider(scrapy.Spider):
name = 'pachong' #爬虫名称
#allowed_domains = ['http://lab.scrapyd.cn']
start_urls = ['https://www.tipdm.org/bdrace/notices/'] #起始url
url='https://www.tipdm.org/bdrace/notices/index_%d.html' #要实现翻页更能,实现全站数据爬取
page_sum=2 #定义页面数
def parse(self, response): #进行全站数据的爬取
div_list = response.xpath('/html/body/div/div[3]/div/div/div[2]/div[2]/ul/li')
for div in div_list:
tit=div.xpath('./div[1]/a/text()')[0].extract() #标题位置
time=div.xpath('./div[2]/span[1]/text()').extract() #时间都位置
contnet=div.xpath('./div[3]//text()').extract() #文本内容的位置
contnet=''.join(contnet)
item=ZwhspiderItem() #将爬到的数据放入item实体,也就是将爬到的数据以item对象返回
item['tit']=tit
item['time']=time
item['contnet']=contnet
yield item
if self.page_sum<=5: #实现翻页功能
new_url=format(self.url%self.page_sum)
self.page_sum+=1
yield scrapy.Request(url=new_url,callback=self.parse)
(2)items.py文件
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ZwhspiderItem(scrapy.Item):
# define the fields for your item here like:
tit=scrapy.Field()
time=scrapy.Field()
contnet=scrapy.Field()
(3)middlewares.py文件(目前还未修改中间件组件)
(起始settings并没有开启中间件)
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
class ZwhspiderSpiderMiddleware: #爬虫中间件
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, or item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Request or item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class ZwhspiderDownloaderMiddleware: #下载中间件
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
#拦截请求
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
#拦截所有的响应
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
#拦截发生异常的请求
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
(4)pipelines.py文件(管道)
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class ZwhspiderPipeline(object):
fp = None
# 重写父类一个方法:该方法旨在开始爬虫的hi和被调用一次
def open_spider(self, spider):
print("开始爬虫.....")
self.fp = open('./新闻动态.txt', 'w', encoding='utf-8')
# 专门用来处理item类型对象的
# 该方法可以接收爬虫文件提交过来的item对象
# 该方法每接收到一个item就会被调用一次
def process_item(self, item, spider):
# 将接收到的item对象中存储的数据进行持久化存储操作(写入本地文件)
tit = item['tit']
time = item['time']
contnet=item['contnet']
self.fp.write(str(tit) +':'+str(time) +':' + str(contnet)+'\n\n')
return item # 就会传递给下一个即将被执行的管道类
def close_spider(self, spider):
print("结束爬虫!")
self.fp.close()
(5)settings.py文件
# Scrapy settings for zwhSpider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'zwhSpider'
SPIDER_MODULES = ['zwhSpider.spiders']
NEWSPIDER_MODULE = 'zwhSpider.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36' #url可以定义多个
# Obey robots.txt rules
ROBOTSTXT_OBEY = False #不遵从robots.txt协议
LOG_LEVEL='ERROR' #不爬取无关日志
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'zwhSpider.middlewares.ZwhspiderSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'zwhSpider.middlewares.ZwhspiderDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'zwhSpider.pipelines.ZwhspiderPipeline': 300, #开启管道
# 300表示的是优先级,数值越小优先级越高
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
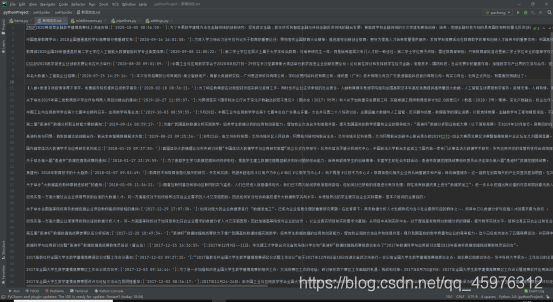
使用scrapy crawl pachong 启动爬虫

看到我们爬取成功了。
接下来进行中间件的修改:
****1.编辑以自己名字拼音+middlewares建立的py文件,编辑该脚本文件,添加随机选择的User_Agent的代码;

from scrapy import signals
import random
import base64
#from settings import USER_AGENTS
#from settings import PROXIES
USER_AGENTS= ['Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
]
# 随机的User-Agent
class RandomUserAgent(object):
def process_request(self, request, spider):
useragent = random.choice(USER_AGENTS)
request.headers.setdefault("User-Agent", useragent)
2.编辑setting脚本,激活创建的中间件;
打开settings中的
DOWNLOADER_MIDDLEWARES = {
}
添加自己定义的中间件
DOWNLOADER_MIDDLEWARES = {
#'zwhSpider.middlewares.zhangwenhumiddlewares.MyExtension':200,
'zwhSpider.middlewares.zhangwenhumiddlewares.RandomUserAgent':220 #激活创建的中间件
#'zwhSpider.middlewares.RandomUserAgent':222,
#'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 0, #关闭内置下载器中间件RobotsTxtMiddleware
#'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware': 0 #关闭UrlLengthMiddlewareSpider中间件
}
3.编辑setting脚本,关闭RobotsTxtMiddleware下载器中间件;
因为RobotsTxMiddleware是内置下载器中间件,所有修改必须要导入
from scrapy.downloadermiddlewares.robotstxt import RobotsTxtMiddleware
接下来进行关闭:
DOWNLOADER_MIDDLEWARES = {
'zwhSpider.middlewares.zhangwenhumiddlewares.MyExtension':200,
'zwhSpider.middlewares.zhangwenhumiddlewares.RandomUserAgent':220, #激活创建的中间件
#'zwhSpider.middlewares.RandomUserAgent':222,
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 0, #关闭内置下载器中间件RobotsTxtMiddleware
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware': 0 #关闭UrlLengthMiddlewareSpider中间件
}
4.编辑setting脚本,关闭UrlLengthMiddlewareSpider中间件。
因为RobotsTxMiddleware是内置爬虫中间件,所有修改必须要导入
from scrapy.spidermiddlewares.urllength import UrlLengthMiddleware
接下来进行关闭:
DOWNLOADER_MIDDLEWARES = {
'zwhSpider.middlewares.zhangwenhumiddlewares.MyExtension':200,
'zwhSpider.middlewares.zhangwenhumiddlewares.RandomUserAgent':220, #激活创建的中间件
#'zwhSpider.middlewares.RandomUserAgent':222,
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 0, #关闭内置下载器中间件RobotsTxtMiddleware
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware': 0 #关闭UrlLengthMiddlewareSpider中间件
}
这时,我们已经自定义了中间件,我们可以运行一下,看我们的爬虫能否正常进行:

看到我们的爬虫运行了,再看看我们保存到本地的文件里面有没有爬到的数据:
在本地找到我们爬虫的项目,找到这个文件并打开它:

我们可以看见我们爬取到了数据,说明我们定制成功!
(本文只会用于python爬虫的简单学习,不针对任何网站)














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









