



多查询注意力(Multi Query Attention, MQA) 是多头注意力机制的一种变体,它的主要特点是 不同的注意力头共享一个键(Key)和值(Value) 的集合,而每个注意力头仅保留各自的查询(Query)参数。这一设计与传统的多头注意力机制有所不同,传统多头注意力为每个头独立生成查询、键和值矩阵。
1. 多头注意力机制回顾
在标准的 多头注意力机制(Multi-Head Attention, MHA) 中,输入通常被投影到多个查询(Q)、键(K)和值(V)矩阵,每个注意力头独立计算这些矩阵。其基本思想是通过多头来捕捉不同的子空间信息。每个头都执行如下步骤:
- 使用输入向量生成 Q、K 和 V 矩阵
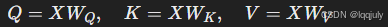
- 对每个头执行 Scaled Dot-Product Attention(缩放点积注意力),计算注意力权重并应用到值(V)上
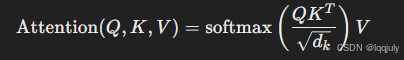
- 将所有头的输出拼接(concatenate)起来,并通过一个线性层进行转换。
标准 MHA 的优点是每个注意力头可以关注输入的不同部分,捕捉不同的特征。然而,MHA 的缺点是每个注意力头都独立生成 Q、K 和 V 矩阵,导致显存占用随着注意力头的数量线性增加,尤其在处理长序列时,计算成本和显存需求显著增加。
2. 多查询注意力的改进
多查询注意力(MQA) 的提出是为了解决上述问题。它的主要改进点在于 共享 K 和 V 矩阵,从而降低计算和显存开销。
-
在 MQA 中,所有的注意力头共享相同的键(K)和值(V)矩阵。每个注意力头只保留自己的查询(Q)矩阵。这意味着键和值的计算和存储只需要进行一次,而不是为每个头重复计算。
-
查询(Q)矩阵仍然是独立的:每个头有自己独立的查询矩阵,因此每个头仍然可以从不同的角度来关注输入数据的不同特征。
这一机制的关键公式如下:
-
共享 K 和 V:
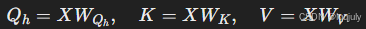
其中,h 表示第 h个注意力头。注意这里每个头都有自己的 Qh,但所有头共享同一组 K 和 V。
-
计算注意力:
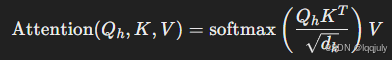
虽然 K 和 V被共享,但每个头仍然可以独立计算自己的注意力分布。
3. 多查询注意力的优势
-
显存占用显著减少:在传统的多头注意力机制中,每个注意力头都独立生成 K 和 V 矩阵,随着注意力头数的增加,显存开销会快速增长。MQA 中所有注意力头共享 K 和 V 矩阵,因此不再需要为每个头独立存储这些矩阵。这在处理长序列输入时尤其有效,因为矩阵的大小与输入序列长度呈二次增长。
-
计算效率提升:减少了矩阵的生成和存储需求,从而减少了显存读写操作,提升了计算效率。特别是在大规模模型或长序列的情况下,显存的带宽和读写瓶颈通常成为计算效率的主要限制。MQA 的设计直接减少了对显存的频繁读写。
-
对序列长度更友好:由于键和值矩阵的大小与序列长度成正比,因此减少这些矩阵的存储可以更高效地处理长序列数据。标准的 MHA 机制在序列长度很大时会显著增加存储和计算需求,而 MQA 有助于缓解这种问题。
4. 训练与微调的适应性
虽然多查询注意力对模型结构做出了修改,但模型不一定需要从头开始支持 MQA。已经训练好的模型可以通过 微调 来添加 MQA 支持,且只需使用原始训练数据的一小部分(大约 5%)进行微调。这意味着即使拥有一个已经训练好的多头注意力模型,也可以通过微调的方式让它支持 MQA,从而减少显存消耗并提升推理效率。由于只需要少量数据和计算资源,这种转化过程非常高效。
5. 实例应用
MQA 的高效性使得它在很多最新的大规模模型中得到了应用,例如 Falcon、SantaCoder 和 StarCoder。这些模型在处理复杂任务和长序列输入时都能受益于 MQA 提供的显存优化与计算效率提升。
- Falcon 是一个大规模语言模型,采用了多查询注意力来提高处理速度和效率。
- SantaCoder 和 StarCoder 则是专注于代码生成和理解的模型,它们通过 MQA 来优化显存占用,以便处理更长的代码序列和更复杂的代码结构。
6. MQA 的扩展与局限
尽管 MQA 在大多数场景下表现良好,但它也有一些局限性:
-
适用场景:MQA 适合于模型参数较多、序列较长的任务,尤其是需要大量显存时的场景。然而在某些小规模任务中,标准的多头注意力机制已经足够高效,MQA 的收益可能较小。
-
模型结构变化:虽然可以通过微调的方式将 MQA 集成到已有模型中,但仍然需要对模型结构进行一定调整,这对一些预训练模型或系统可能需要较大工程改动。
总结
多查询注意力(MQA)是一种对多头注意力机制的改进,主要通过共享键和值矩阵来减少显存占用并提升计算效率。它特别适合长序列输入和大规模模型的应用场景。通过减少显存读写操作,MQA 有效缓解了传统多头注意力在显存使用上的瓶颈问题,同时可以通过微调将其集成到现有模型中。许多现代模型如 Falcon、SantaCoder 和 StarCoder 已经使用了该机制,实现了性能和效率的提升。

















 1718
1718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









