








1. 编码
计算机只能识别高低电平, 将高低电平用数字表示: '0'表示低电压, '1'表示高电平.
于是就创造出来'二进制数', 一个二进制有 '0' 和 '1', 两种状态,
设计硬盘的目的就是为了能保存这两种状态.
想要将数据存储到硬盘中, 就必须将数据转化为二进制形式存储.
编码: 将数据将数据转化为二进制的过程.
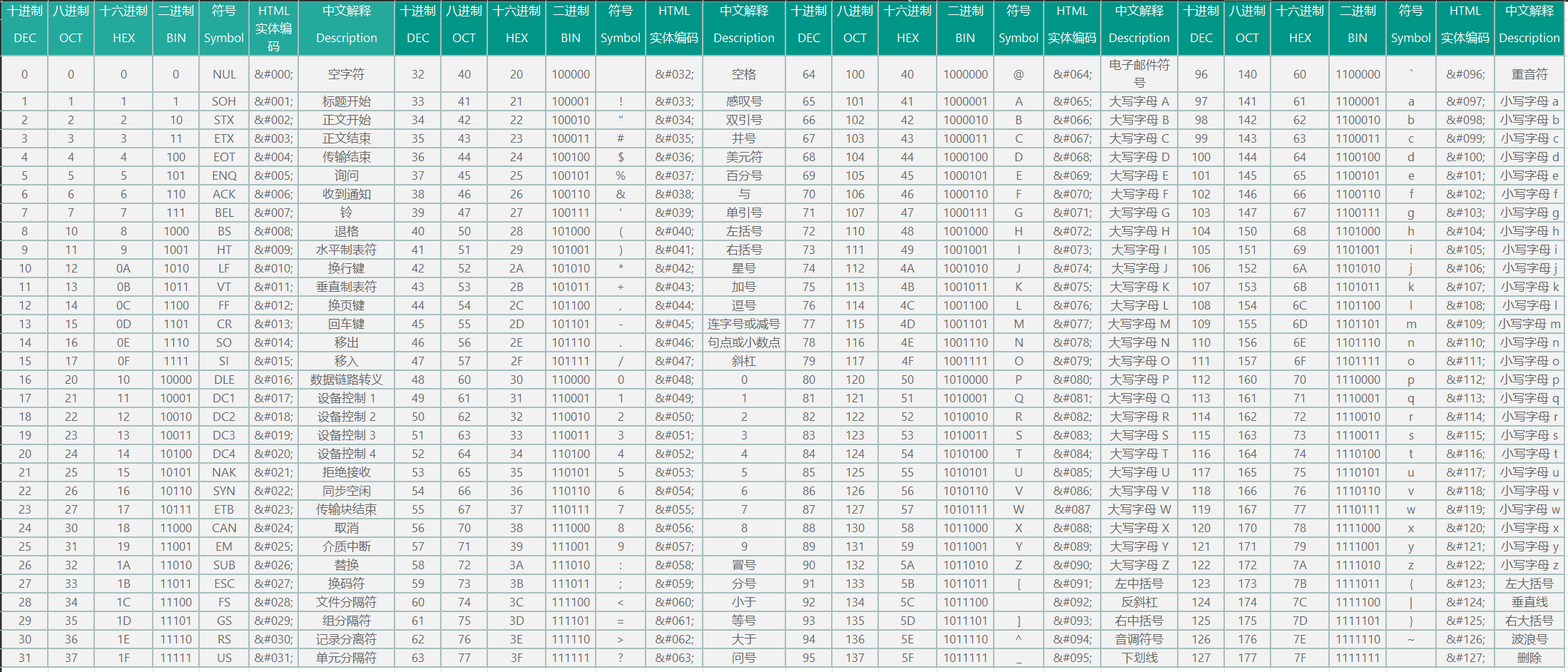
2. ASCII 字符集
文本的最小组件是字符, 'A', 'B', 'C' 等都是不同的字符.
计算机是美国人发明的, 为了让加计算机能够识别所有的英文字符, 制作了 ASCII 字符集.
ASCII 字符集: 记录了英文字符与二进制的对应关系, 用一个字节来表示所有对应关系.
* 确定了计算机存储的最小单位: 字节 ( 8位二进制 ).
一位可以表示2种状态, 8 位可以表示 2 ** 8 = 266 种状态.
0 - 31 为控制字符: 不能用于打印控制的编码, 而是用于控制像打印机一样的外围设备.
32 - 127 为打印字符: 常用的数字, 大小写字母, 运算符号等.
128 - 255 为扩展码: 特殊符号字符, 外来语字母和图形符号, 法国字母注音符等.
3. 字符编码发展
计算机普及世界, 各国为了能让电脑能识别自己的语言字符, 制作了不同的字符集.
中国编码:
GB2312 编码: 包含了 ASCII 编码, 扩充6000多个常用汉字, 英文占一个字节, 中文占两个字节.
GBK 编码: 包含了GB2312 编码, 扩充繁体字偏僻字, 英文占一个字节, 中文占两个字节.
GB18030 编码: 包含 GBK 编码, 扩充少数民族字符, 英文占一个字节, 中文占两到四个字节.
...
其它各国相继开发自己的编码, 导致一段二进制在各国都是不同的意思.
4. Unicode 字符集
为了实现不同国家之间的文本数据能够彼此无障碍交流, 对编码进行统一制作了 Unicode 字符集.
将世界上所有的符号都纳入其中, 每一个符号都给予一个独一无二的编码,
目前 Unicode 5.0 收录的字符已经达到 99024 .
Unicode 字符集:
UCS-2 固定使用两个字节编码, 两个字节 2 ** 16 = 65536种状态, 容纳世界上常用书面字符,
不兼容 ASCII 码, ASCII 码转 Unicode 编码时, 后8位保持不变, 前8位只需要用0去补全即可.
对中文的兼容性不好, 汉字根据不完全统计汉字大约有十万个左右, 两个字节不足以完全收纳汉字.
UCS-4 用4个字节编码, 为了防止将来2个字节不够用才开发的. 4个字节 2 ** 32 = 4294967296种状态.
容纳世界上所用书面字符, 不兼容 ASCII 码, 兼容中文.
5. 字符编码
Unicode 虽然统一了编码, 但没有规定如何存储, 导致 Unicode 出现了的多种存储方式,
例: UTF-8, UTF-16, UTF-32 ...
'字符集'和'字符编码'不是一个概念.
字符集: 定义了文字和二进制的对应关系, 为字符分配了唯一的编号.
字符编码: 规定了如何将文字的编号存储到内存中, 但凡涉及字符的存储都需要考虑字符编码的问题.
5.1 UTF-16
UTF-16 编码源于 UCS-2, 固定使用两个字符表示一个字符, 是 Unicode 最早的编码方式 (不兼容 ASCII 码).
5.3 UTF-32
UTF-32 编码源于 UCS-4 , 固定使用四个字节表一个字符, 当前主流, (不兼容 ASCII 码).
5.3 UTF-8
UTF-8 可变长字符, 使用1~4个字节表示一个符号, 当存储英文时只使用一个字节,
而存储中文字符时, 使用三个字节来表示 (兼容 ASCII 码).
为什么设计为可变长?
UTF-16 和 UTF-32 缺点就是它们固定使用两个或四个字节,
书写文本时如果文本中多少 ASCII 的英文字符, 那么文件的体积翻倍.
* 目前主流使用的都是 UTF-8.
6. 文件编码转换
文件的数据最初产生在还是在内存, 那么内存也需要使用字符编码.
UTF-8 长度不固定, 在内存处理字符变得复杂, 例: 不知道申请几个字节的空间...
文件的编码会自动转换:
字符从文件中读取 utf-8 编码到内存时, 会自动转换为 Unicode 编码,
而从内存中将字符保存到文件时, 则自动转换为 utf-8 编码.
内存中存储字符时使用 unicode 编码, 因为 unicode 编码的长度固定,
而在文件的存储中, 则使用 utf-8 编码可以压缩内存, 节省空间.
7. 乱码问题
一串字符的二进制数, 想要解码, 就必须知道它的编码方式, 不然就会出现我们有时候看到的乱码.
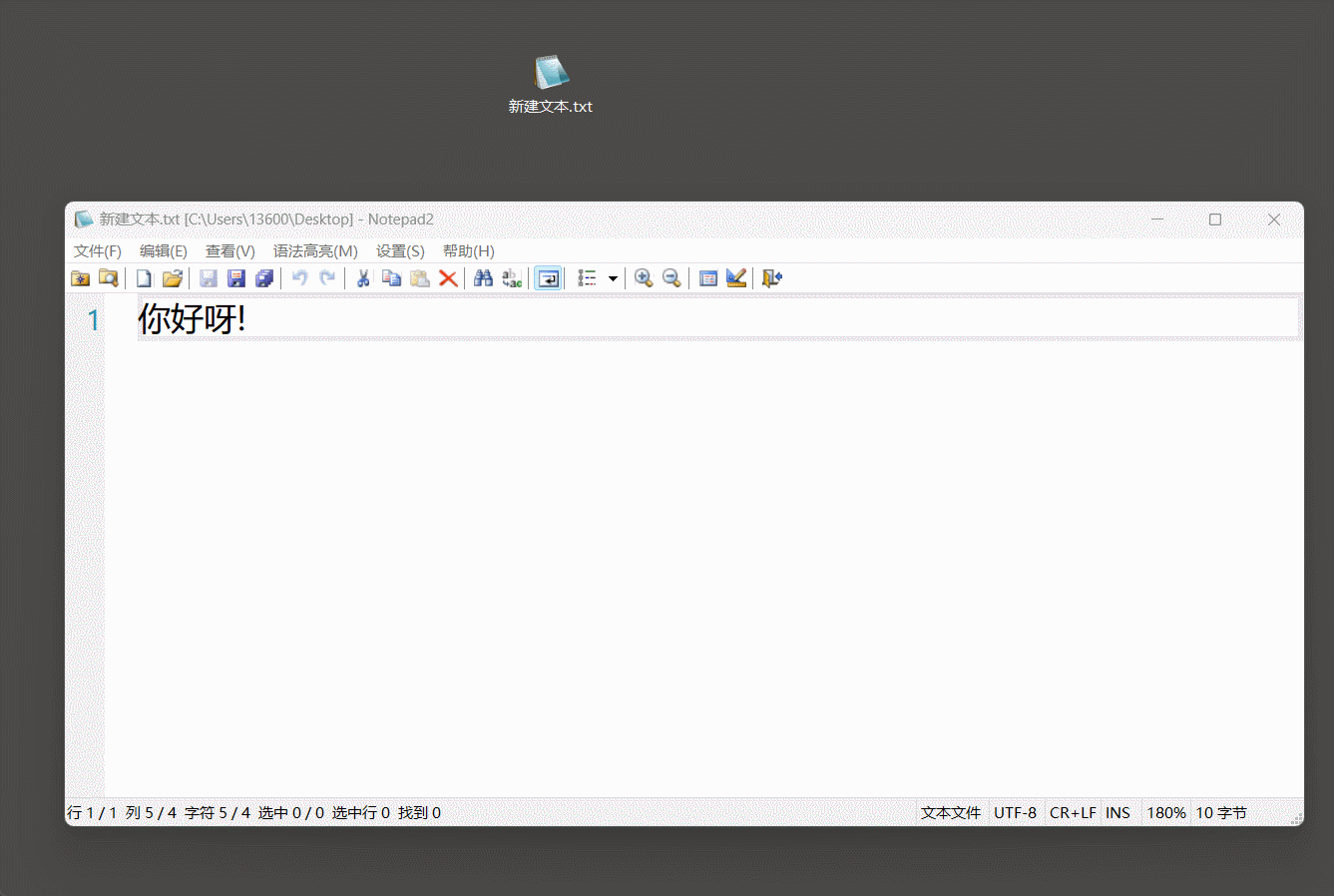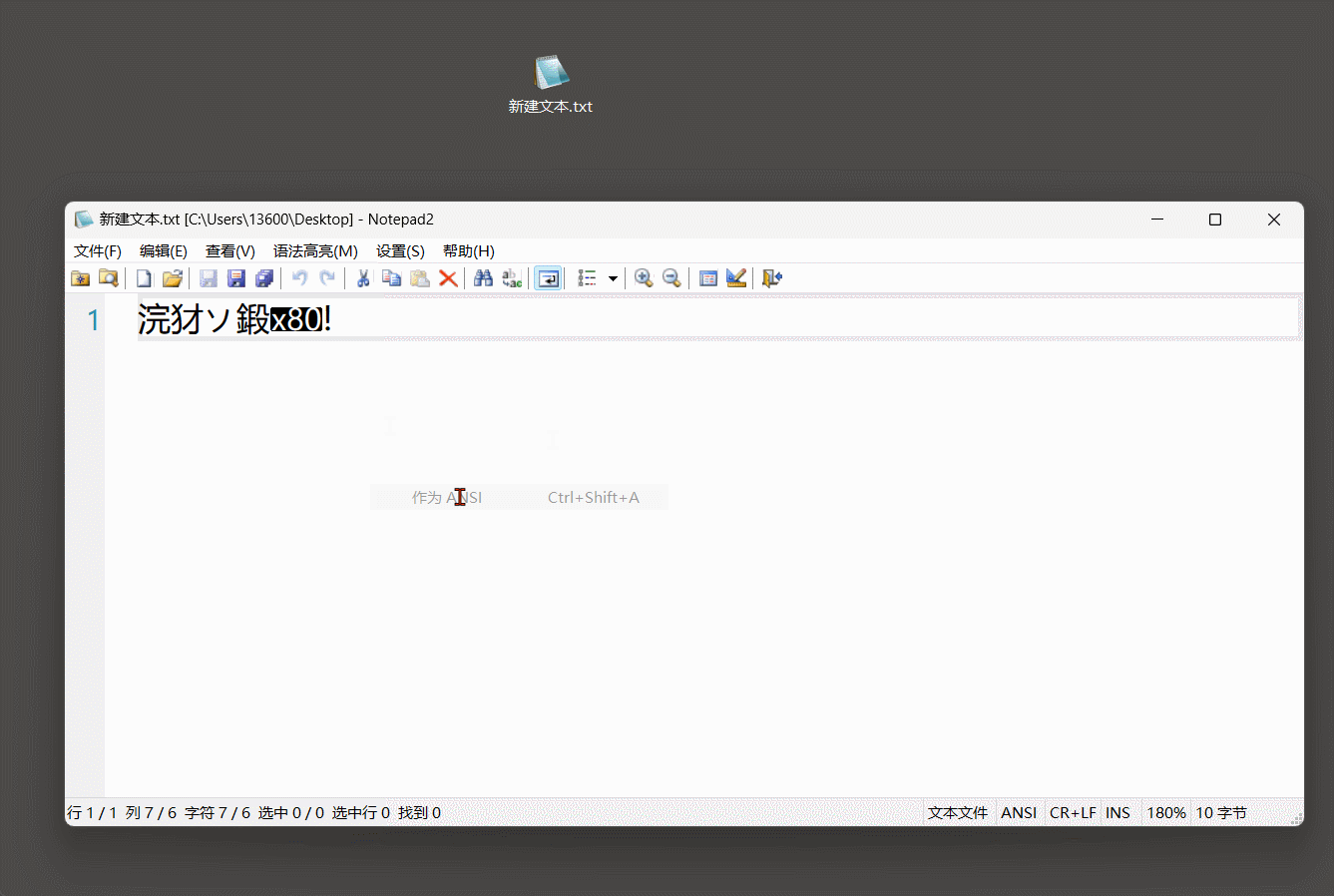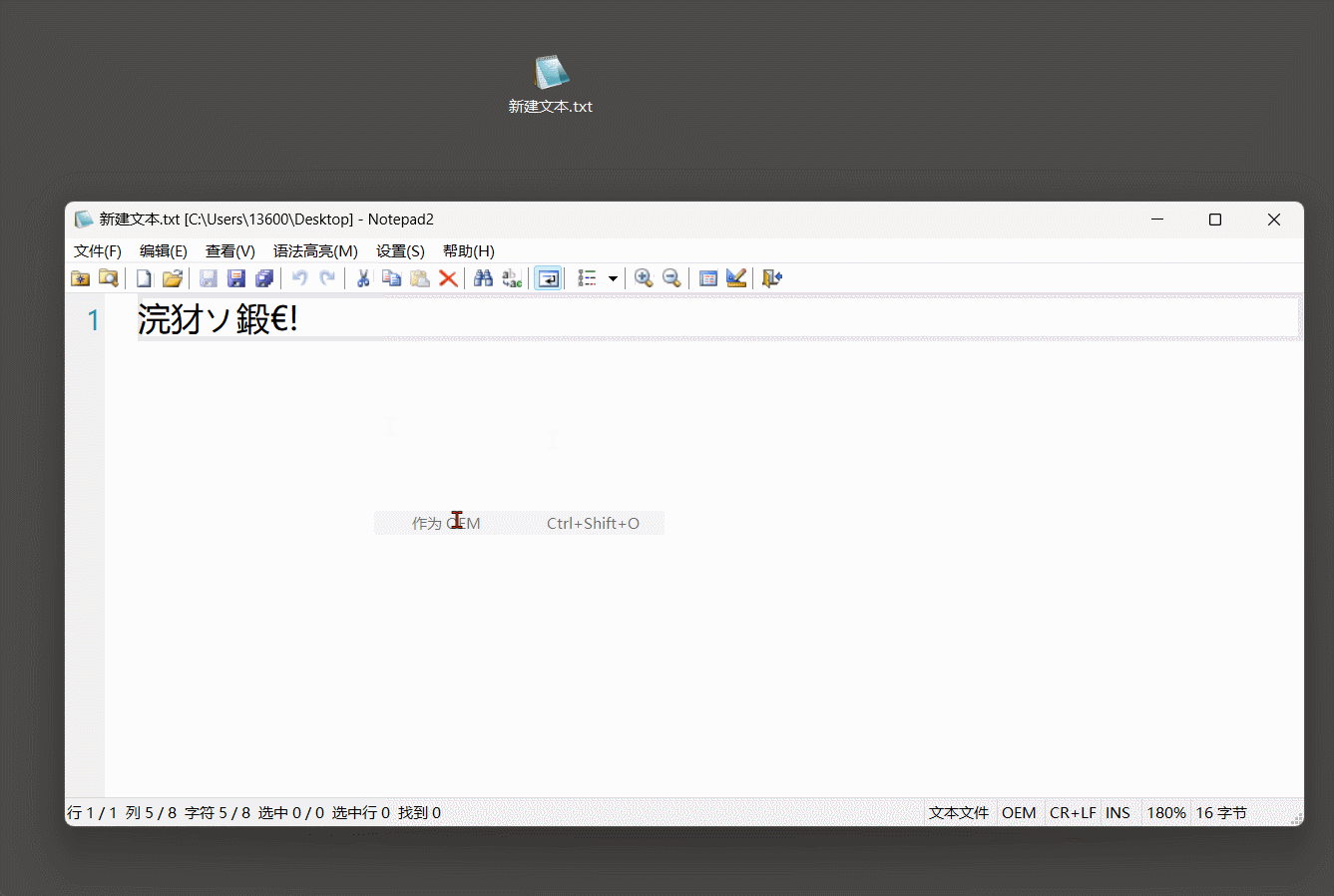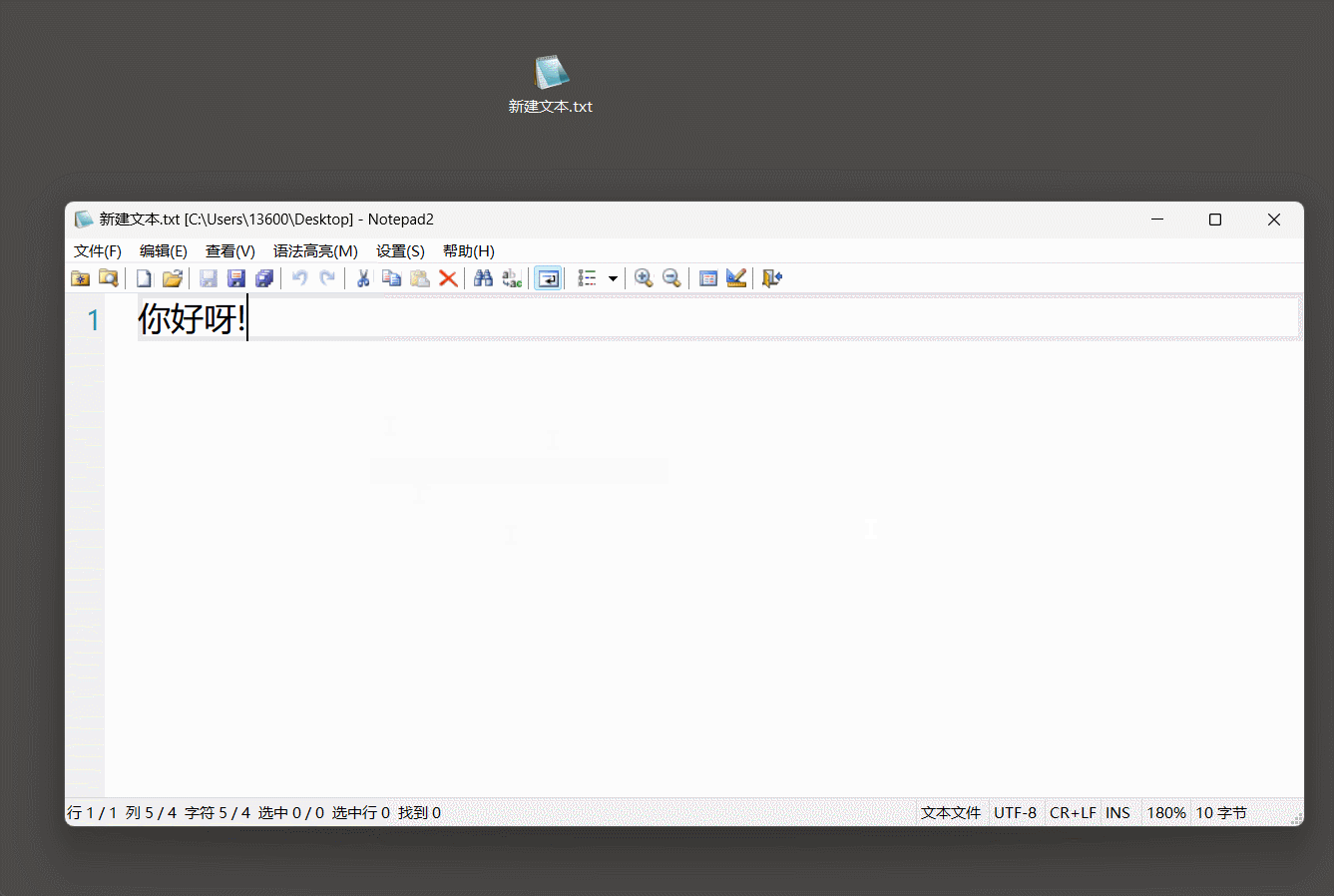
只有某个编码包含的 ASCII, 就能识别英文字符.
文章的段落全是代码块包裹的, 留言0是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言1是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言2是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言3是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言4是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言5是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言6是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言7是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言8是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言9是为了避免文章提示质量低.














 483
483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









