






卷积神经网络
一、绪论
1.卷积神经网络的应用
无处不在的卷积神经网路
分割、检测、分类、人脸识别、人脸表情识别、图像生成、图像风格转化、自动驾驶
2.传统神经网络vs卷积神经网络
深度学习三部曲
Step1.搭建神经网络结构
Step2.找到一个合适的损失函数
Step3.找到一个合适的优化函数,更新参数
损失函数


二、基本组成结构
1.卷积

什么是卷积,以及为什么需要二维卷积
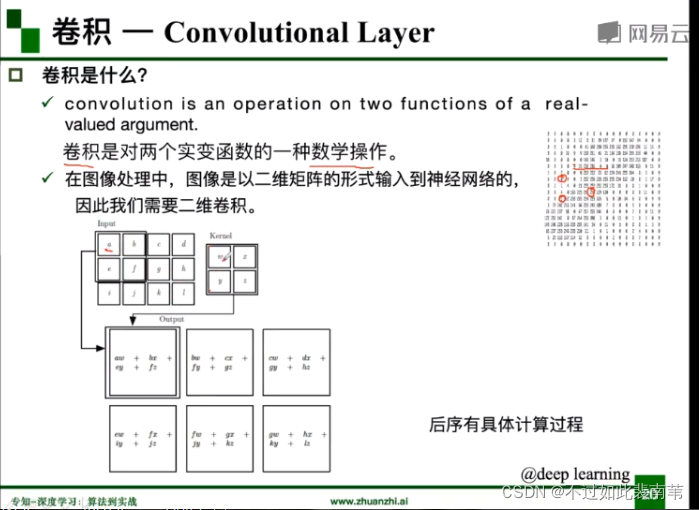
基本概念

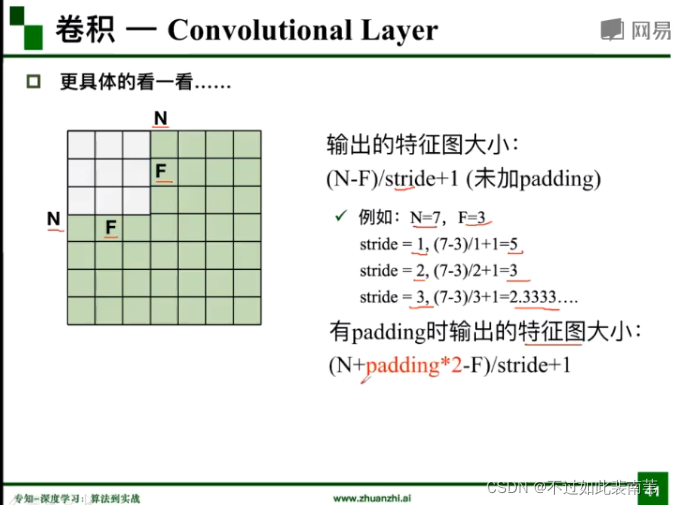
计算特征图大小
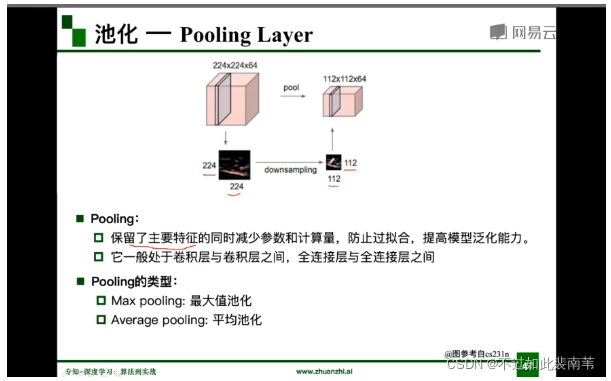
2.池化
池化类似于缩放
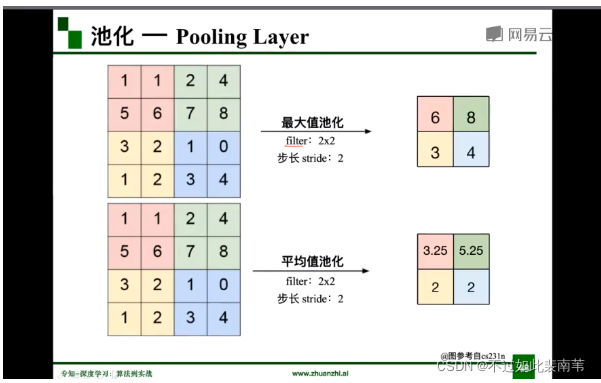
最大值池化和平均值池化
3.全连接

小结

三、卷积神经网络典型结构
神经网络发展历程
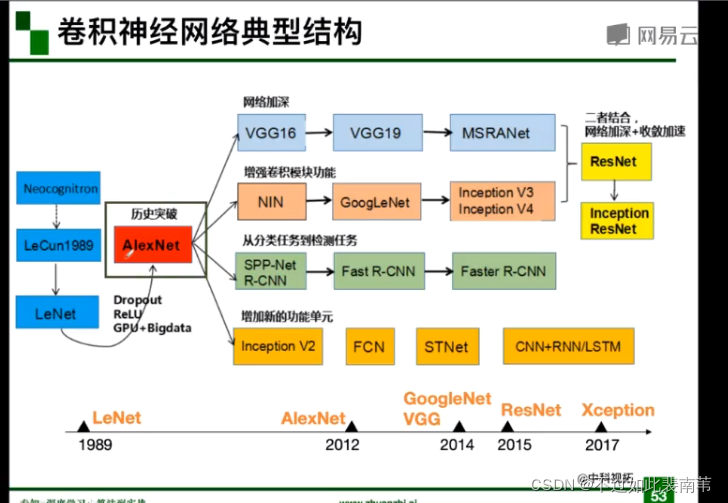
1.AlexNet

AlexNet成功的原因

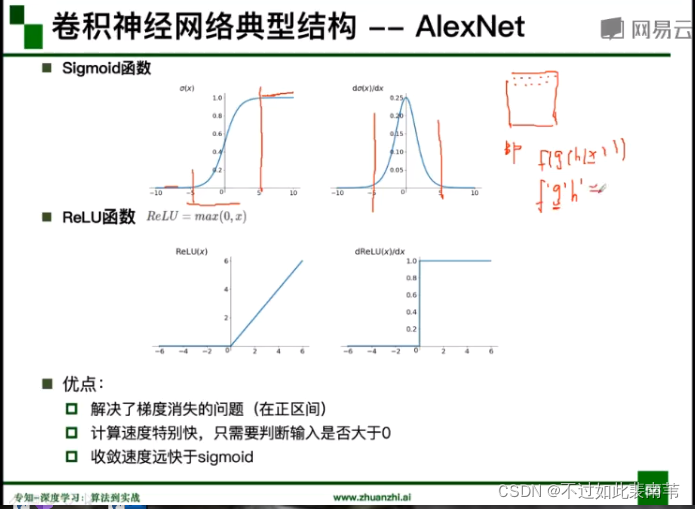
Sigmoid和ReLU函数的优劣分析
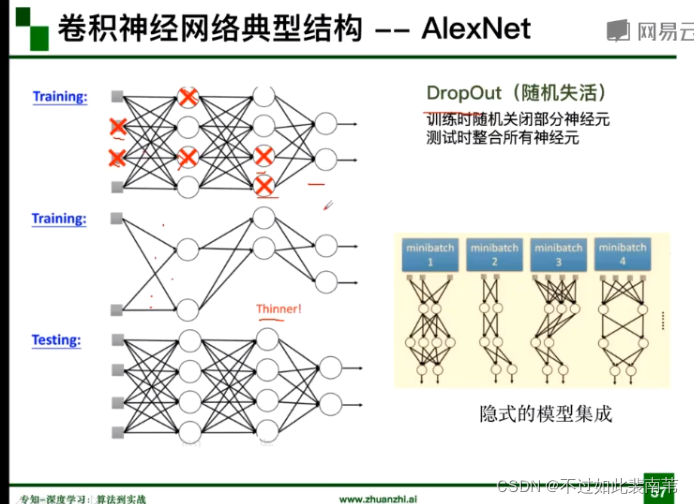
DropOut(随机失活)函数分析:减小参数量
数据增强

AlexNet分层解析
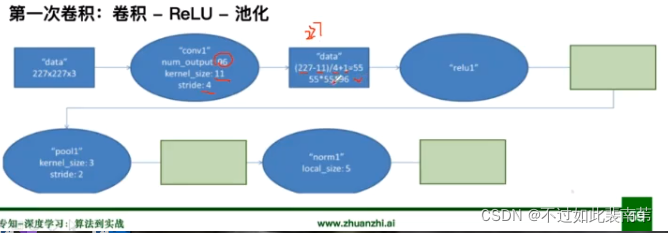
第一次卷积
第二次卷积
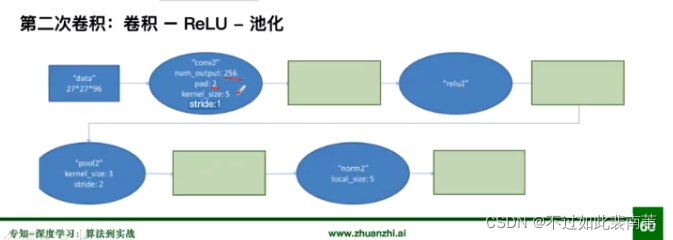
后续几次卷积方式类似
全连接层

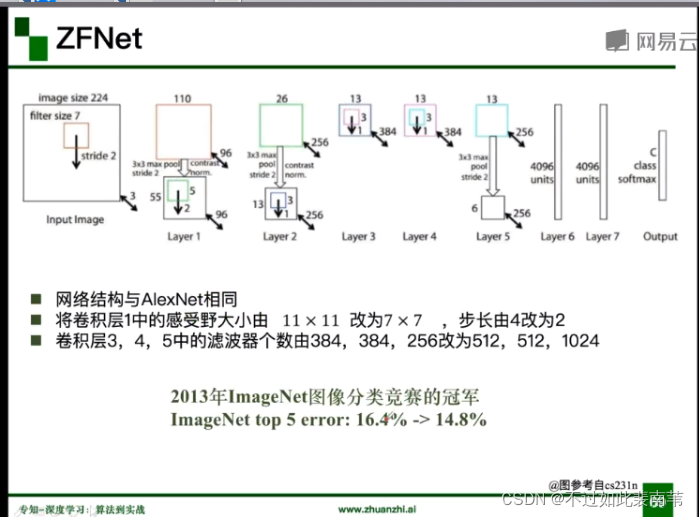
2.ZFNet
3.VGG

4.GoogleNet
参数小且没有全连接层
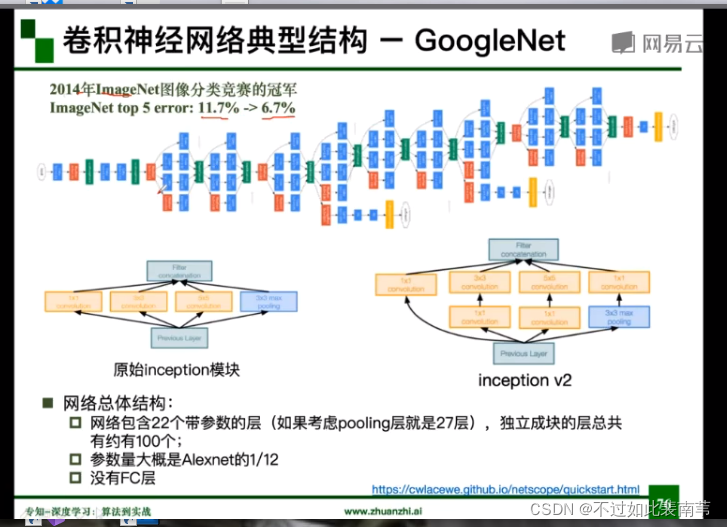
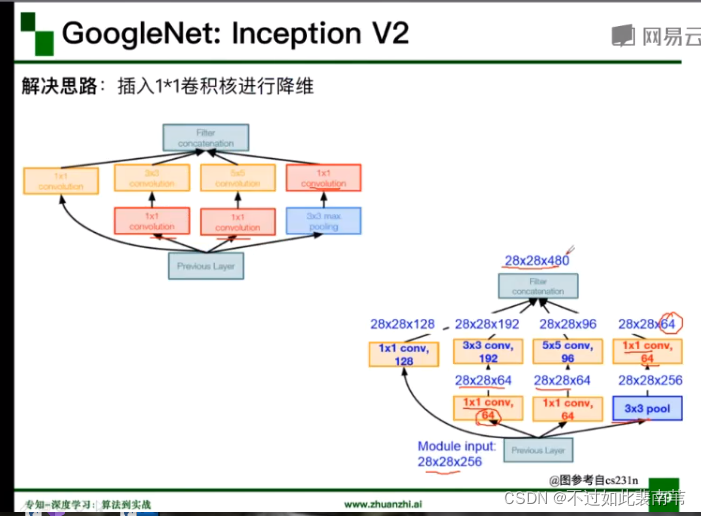
插入1*1卷积核降维,减少参数量
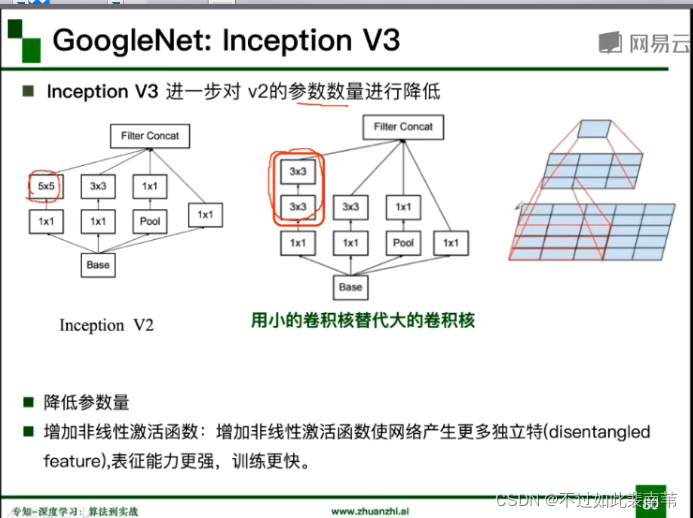
用两个3*3的卷积核的替代5*5的卷积核降低参数量
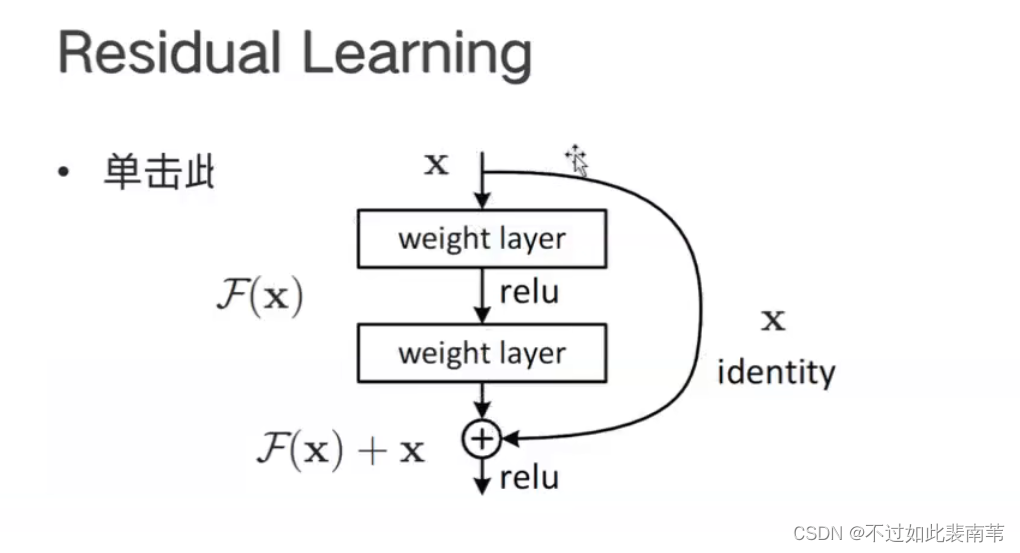
5.ResNet
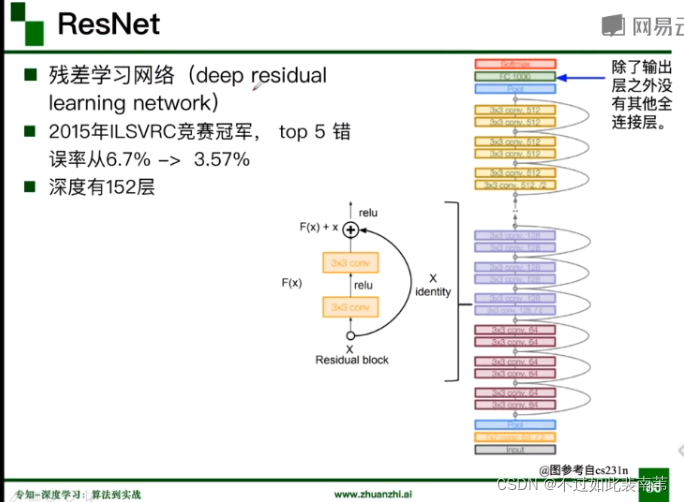
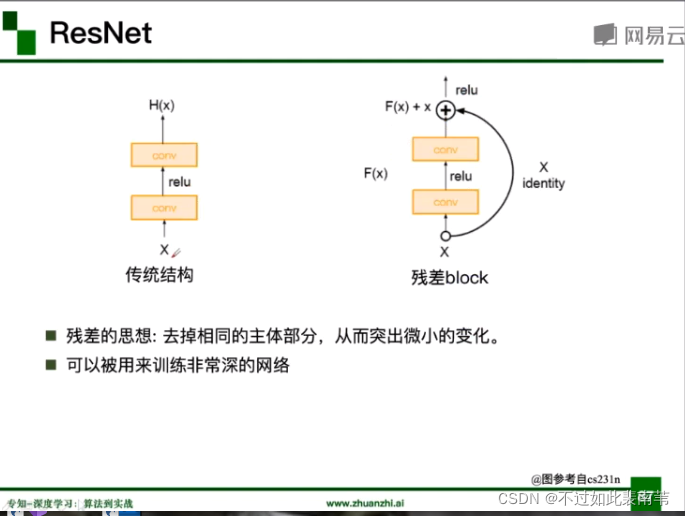
残差思想
四、代码实战
Tensorflow-CNN
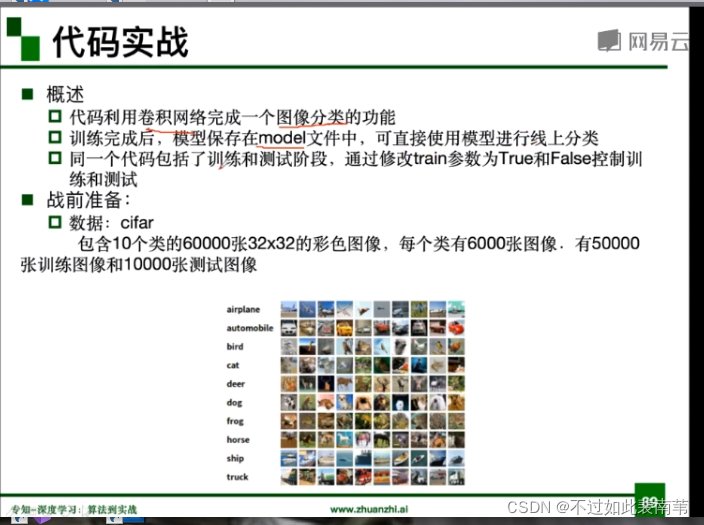
图片分类

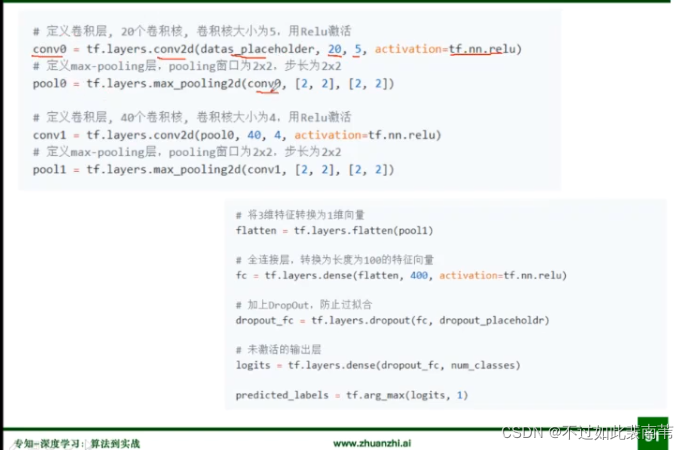
卷积层,池化层(最大值池化),全连接层代码
五、结合pytorch代码讲解ResNet
网络退化现象
高层数的准确率可能会低于底层数的准确率
此时函数H(X)难以训练拟合,我们尝试训练F(X)=H(X)-X,如果F(X)可以训练,可以得到函数H(X)=F(X)+X,其中H(X)-X就是残差,这个训练过程就叫残差学习。
从传统VGG到ResNet,在层之间添加恒等映射
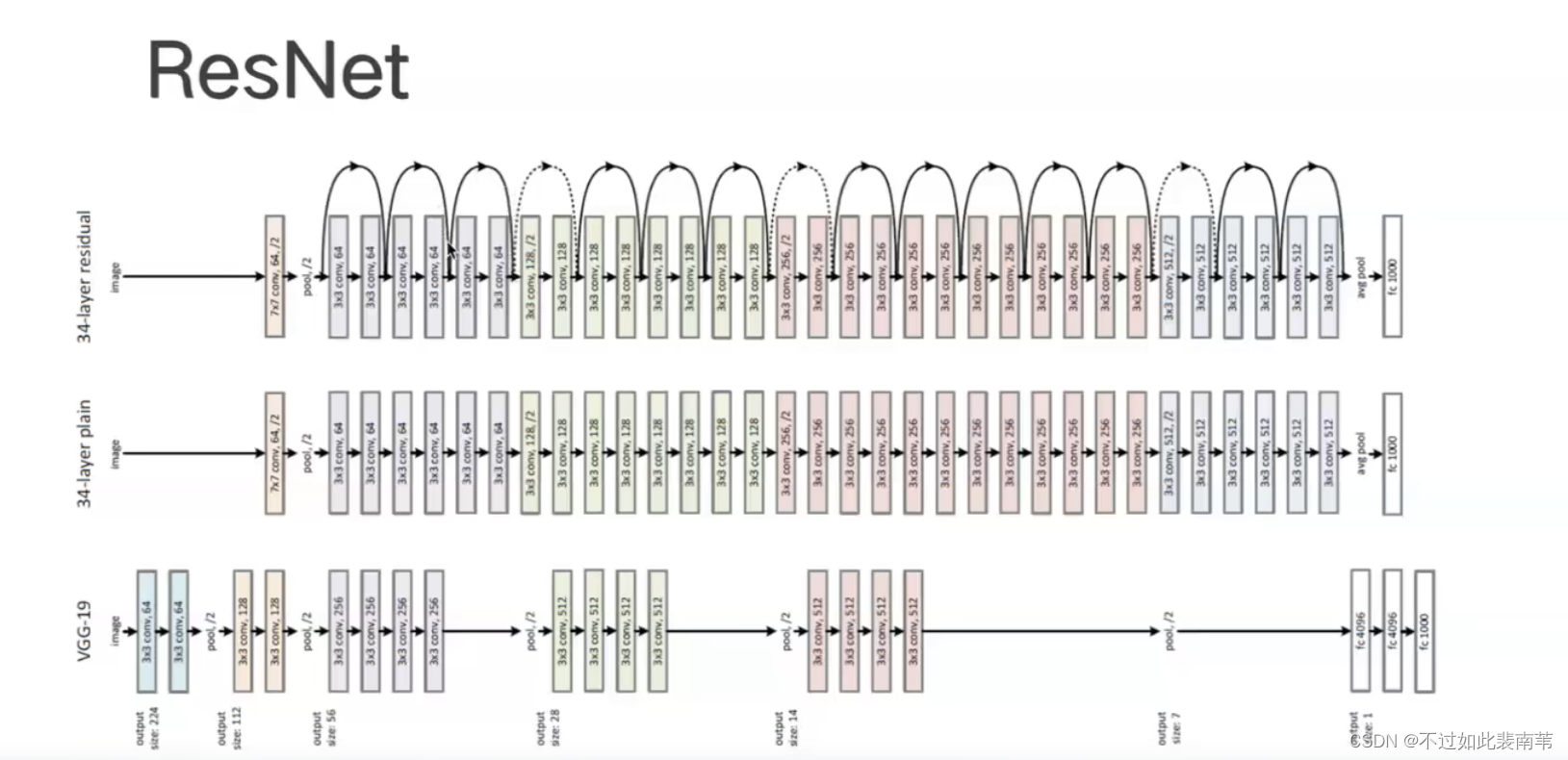
每个ResNet由五个stage组成,一个stage由若干个block组成,一个block由若干个convs组成
全局平均池化可以替代全连接层
减少参数,避免过拟合
50层以上的ResNet有三层block
50层以下的ResNet只有两层block
与BottleNeck相关
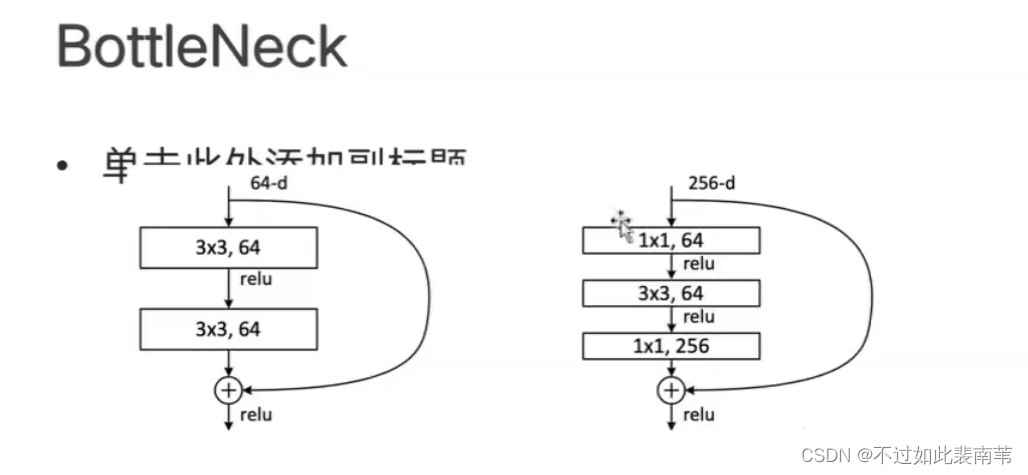
ResNet的新发展:
1.ResNeXt:引入了分组卷积
2.ResNeXt-Attention:注意力机制
3.ResNeXt WSL:弱监督训练
六、MNIST数据集分类
1.加载数据
值得注意的是,DataLoader是一个比较重要的类,提供的常用操作有:batch_size(每个batch的大小), shuffle(是否进行随机打乱顺序的操作), num_workers(加载数据的时候使用几个子进程)
input_size = 28*28 # MNIST上的图像尺寸是 28x28
output_size = 10 # 类别为 0 到 9 的数字,因此为十类
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])),
batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])),
batch_size=1000, shuffle=True)
显示数据集中的部分图像
plt.figure(figsize=(8, 5))
for i in range(20):
plt.subplot(4, 5, i + 1)
image, _ = train_loader.dataset.__getitem__(i)
plt.imshow(image.squeeze().numpy(),'gray')
plt.axis('off');
2.创建网络
定义训练函数train和测试函数test
3.在小型全连接网络上训练
准确率略有波动 84%-88%

4.在卷积神经网络上训练
定义的CNN和全连接网络,拥有相同数量的模型参数
 对比结果可以看出,相同的参数数量下CNN效果优于简单地全连接网络,原因是CNN能通过卷积和池化更好地挖掘图像中的信息。
对比结果可以看出,相同的参数数量下CNN效果优于简单地全连接网络,原因是CNN能通过卷积和池化更好地挖掘图像中的信息。
5.打乱像素顺序再次在两个网络上训练与测试
考虑到CNN在卷积与池化上的优良特性,我们把图像中的像素打乱顺序,让卷积和池化难以发挥作用了。

加入data后重新定义测试与训练函数
在全连接网络上训练与测试
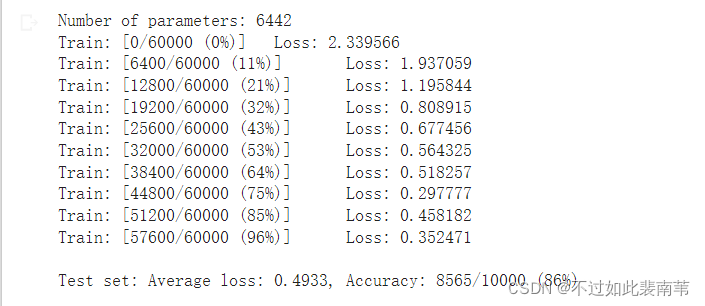
在卷积神经网络上训练与测试

通过测试结果可以看出,全连接网络准确率基本不受影响,卷积神经网络性能明显下降
这是由于像素的局部关系会影响卷积神经网络的准确度。
七、CIFAR10数据集分类
首先,加载并归一化 CIFAR10 使用 torchvision 。torchvision 数据集的输出是范围在[0,1]之间的 PILImage,我们将他们转换成归一化范围为[-1,1]之间的张量 Tensors。
下面代码中说的是 0.5,怎么就变化到[-1,1]之间了?
PyTorch源码中是这么写的:
input[channel] = (input[channel] - mean[channel]) / std[channel]
这样就是:((0,1)-0.5)/0.5=(-1,1)。
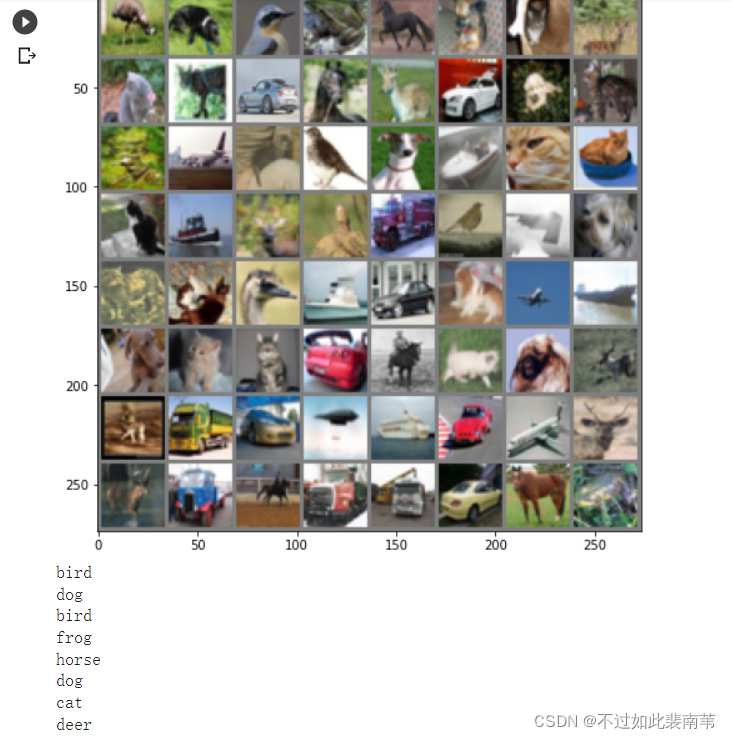
展示CIFAR10中的一部分图片
接着定义网络,损失函数和优化器
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 网络放到GPU上
net = Net().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)训练网络
从测试集中取出八张图片

把图片输入模型,查看CNN的识别效果

对比结果可知
与高老师的代码预期结果有差异,自身存在疑惑,多次运行后得到的结果都是两次识别结果完全一致
高老师的结果
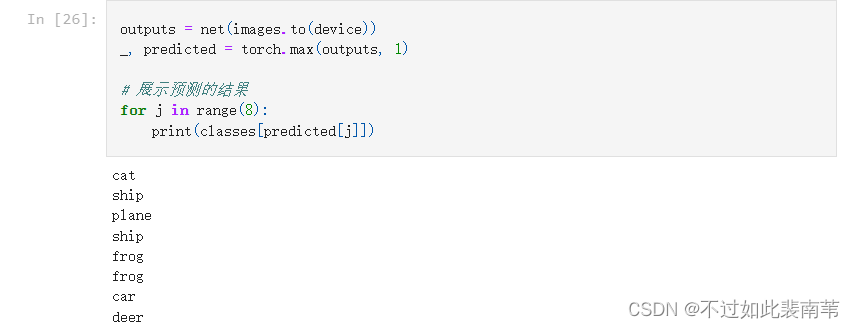
我的结果
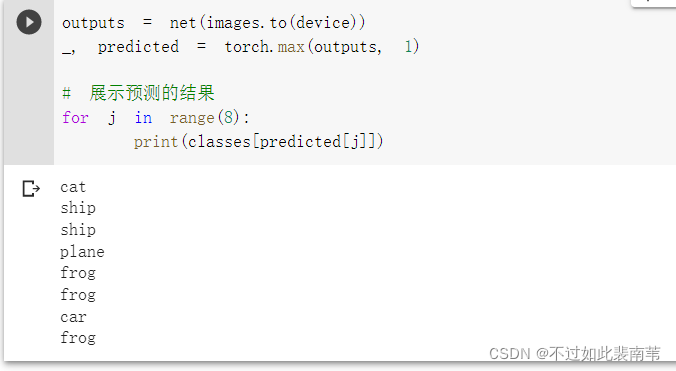
接着查看CNN网络在整个数据集上的表现

准确率一般
八、使用VGG16对CIFAR10分类
定义dataloader
transform和dataloader定义不同,调用函数及参数各有不同
VGG中的定义

CNN中的定义

CIFAR10中的定义

VGG网络定义
经过高老师手动改参之后定义更美观对初始化网络,根据实际需要,修改分类层。因为 tiny-imagenet 是对200类图像分类,这里把输出修改为200。
![]()
![]()
关于这一行代码中的cfg有疑惑,自己实际运行时如果不加self.则无法顺利运行,跟高老师的代码存在不一样的地方,原因暂时未找到

之后进行网络训练
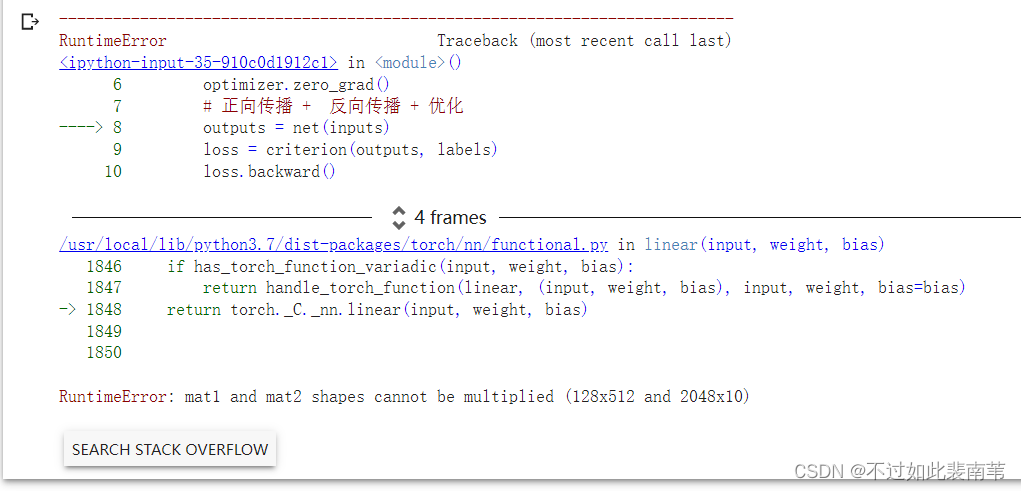
在关于Linear函数的参数设定上具有疑惑,在实际操作中如果设置成2048*10则会报错
mat1和mat2类型无法相乘分别是128*512和2048*10,需将2048*10改成128*512
![]()
![]()
测试验证正确率
![]()
根据结果可以明显看到,使用简化的vgg网络也大幅度提高了准确率
这周的学习到此就告一段落了,期待下周的学习














 581
581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









